Sticky Postings
By fabric | ch
-----
As we continue to lack a decent search engine on this blog and as we don't use a "tag cloud" ... This post could help navigate through the updated content on | rblg (as of 09.2023), via all its tags!
FIND BELOW ALL THE TAGS THAT CAN BE USED TO NAVIGATE IN THE CONTENTS OF | RBLG BLOG:
(to be seen just below if you're navigating on the blog's html pages or here for rss readers)
--
Note that we had to hit the "pause" button on our reblogging activities a while ago (mainly because we ran out of time, but also because we received complaints from a major image stock company about some images that were displayed on | rblg, an activity that we felt was still "fair use" - we've never made any money or advertised on this site).
Nevertheless, we continue to publish from time to time information on the activities of fabric | ch, or content directly related to its work (documentation).
Wednesday, August 26. 2015
Note: In parallel with the exhibition about the work of E.A.T at the Museum der Moderne in Salzburg, another exhibition: Hippie Modernism: The Struggle for Utopia that will certainly be worth a detour at the Walker Art Center in Minneapolis later this autumn.
Via Dezeen
-----
The architecture and design of the counterculture era has been overlooked, according to the curator of an upcoming exhibition dedicated to "Hippie Modernism".

Yellow submarine by Corita Kent, 1967. Photograph by Joshua White
The radical output of the 1960s and 1970s has had a profound influence on contemporary life but has been "largely ignored in official histories of art, architecture and design," said Andrew Blauvelt, curator of the exhibition that opens at the Walker Art Center in Minneapolis this autumn.
"It's difficult to identify another period of history that has exerted more influence on contemporary culture and politics," he said.
"Much of what was produced in the creation of various countercultures did not conform to the traditional definitions of art, and thus it has largely been ignored in official histories of art, architecture, and design," he said. "This exhibition and book seeks to redress this oversight."

Superchair by Ken Isaacs, 1967

Women in Design: The Next Decade by Sheila Levrant de Bretteville, 1975. Courtesy of Sheila Levrant de Bretteville
While not representative of a formal movement, the works in Hippie Modernism challenged the establishment and high Modernism, which had become fully assimilated as a corporate style, both in Europe and North America by the 1960s.
The exhibition, entitled Hippie Modernism: The Struggle for Utopia will centre on three themes taken from taken from American psychologist and psychedelic drug advocate Timothy Leary's era-defining mantra: Turn on, tune in, drop out.
Organised with the participation of the Berkeley Art Museum/Pacific Film Archive, it will cover a diverse range of cultural objects including films, music posters, furniture, installations, conceptual architectural projects and environments.

Hendrixwar/Cosmococa Programa-in-Progress, 1973. Courtesy of the Walker Art Center collection, Minneapolis

Jimi Hendrix, Ira Cohen, 1968. Photograph from the Mylar Chamber, courtesy of the Ira Cohen Archive
The Turn On section of the show will focus on altered perception and expanded individual awareness. It will include conceptual works by British avant-garde architectural group Archigram, American architecture collective Ant Farm, and a predecessor to the music video by American artist Bruce Conner – known for pioneering works in assemblage and video art.
Tune In will look at media as a device for raising collective consciousness and social awareness around issues of the time, many of which resonate today, like the powerful graphics of the US-based black nationalist party Black Panther Movement.

Untitled [the Cockettes] by Clay Geerdes, 1972. Courtesy of the estate of Clay Geerdes
Drop Out includes alternative structures that allowed or proposed ways for individuals and groups to challenge norms or remove themselves from conventional society, with works like the Drop City collective's recreation dome – a hippie version of a Buckminster Fuller dome – and Newton and Helen Mayer Harrison's Portable Orchard, a commentary on the loss of agricultural lands to the spread of suburban sprawl.

Environment Transformer/Flyhead Helmet by Haus-Rucker-Co, 1968. Photograph courtesy of Haus-Rucker-Co and Gerald Zugmann
The issues raised by the projects in Hippie Modernism – racial justice, women's and LGBT rights, environmentalism, and localism among many other – continue to shape culture and politics today.
Blauvelt sees the period's ongoing impact in current practices of public-interest design and social-impact design, where the authorship of the building or object is less important than the need that it serves.

Payne's Gray by Judith Williams, circa 1966. Photograph courtesy of the Morris and Helen Belkin Art Gallery, The University of British Columbia

Superonda Sofa by Archizoom Associati, 1966. Photograph courtesy of Dario Bartolini, Archizoom Associati
Many of the exhibited artists, designers, and architects created immersive environments that challenged notions of domesticity, inside/outside, and traditional limitations on the body, like the Italian avant-garde design group Superstudio's Superonda: conceptual furniture which together creates an architectural landscape that suggests new ways of living and socialising.

Hello Dali by Isaac Abrams, 1965
Blauvelt sees the period's utopian project ending with the OPEC oil crisis of the mid 1970s, which helped initiate the more conservative consumer culture of the late 1970s and 1980s.
Organised in collaboration with the Berkeley Art Museum and the Pacific Film Archive, Hippie Modernism will run from 24 October 2015 to 28 February 2016 at the Walker Art Center.
Monday, July 27. 2015
Note: nice to discover that a museum has decided to mount a retrospective ("first-ever") about the activities of Expriments in Art and Technologies (E.A.T.), a group composed of avant-garde artists and scientists (R. Rauschenberg, R. Whitman, D. Tudor, B. Klüver, F. Waldhauer) that were behind milestones events such as "Event scores, 9 evening" in New York (mainly scored by R. Roschenberg, but with fellow artists and "scorists" like J. Cage, D. Tudor, R. Whitman, L. Childs, etc.) or later the Pepsi Pavilion in Osaka, with Fujiko Nakaya (fog sculptures). This association helped anchor the association of visionary people and scientific labs (Bell Labs in this case, where people like Frank Malina was also working at the time, or A. Michael Noll too... to name a few). Later influential labs (Menlo Park, Xerox, Media Lab) and of course many recent Swiss initiatives (i.e. Artists in labs or Collide@CERN) are inheritors of this early collaboration.
BTW, we should suggest to Pro Helvetia that they could also run an "architects in labs" so as a "designers in lab", that would be a great initiative!
The exhibition opened last Saturday and will last until November 1, 2015.
Via Domus (thank you David Colombini for the link!)
-----
E.A.T.
The Museum der Moderne Salzburg presents a comprehensive survey of the projects of the evolving association of artists and technologists E.A.T. – Experiments in Art and Technology.

The Museum der Moderne Salzburg mounts the first-ever comprehensive retrospective of the activities of Experiments in Art and Technology (E.A.T.), a unique association of engineers and artists who wrote history in the 1960s and 1970s.
Artists like Robert Rauschenberg (1925–2008) and Robert Whitman (b.1935) teamed up with Billy Kluver (1927–2004), a visionary technologist at Bell Telephone Laboratories, and his colleague Fred Waldhauer (1927–1993) to launch a groundbreaking initiative that would realize works of art in an unprecedented collaborative effort.

Top and above: Experiments in Art and Technology (E.A.T.), Pepsi Pavilion, exterior with fog installation by Fujiko Nakaya and Floats by Robert Breer © J. Paul Getty Trust. Getty Research Institute, Los Angeles (2014.R.20). Photo: Shunk-Kender
Around two hundred works of art and projects ranging from kinetic objects, installations, and performances to films, videos, and photographs as well as drawings and prints exemplify the most important stages of E.A.T.’s evolution.
In light of the rapid technological developments of the period, the group aimed to put an art into practice that would employ cutting-edge technology. Starting in the early 1960s, Kluver collaborated with artists including Jean Tinguely, Andy Warhol, Jasper Johns, and Yvonne Rainer on an individual basis.
Like some artists of the time, he was interested in the social implications of novel technologies and believed that the marriage of art and science had to take place on a practical and physical level. Members of E.A.T. hoped that the meeting between artists and engineers would allow for the production of works that would not have been possible without the special expertise of trained technologists. The engineers would conversely be inspired to think in new directions and help shape the future evolution of technology.

Jean Tinguely, Homage to New York, 1960. Kinetic sculpture (mixed media) and performance. The Museum of Modern Art, New York, NY, US, Sculpture Garden, March 17, 1960 © Estate of David Gahr. Photo: David Gahr. Right: Jean Dupuy, Heart Beats Dust, 1968. Engineer: Ralph Martel Lithol rubine pigment, wood, glass, light, stethoscope, amplifier. Collection FRAC Bourgogne © ADAGP, Paris/Courtesy Galerie Loevenbruck, Paris. Photo: Terry Stevenson
-----
July 25 – November 1, 2015
E.A.T. – Experiments in Art and Technology
Museum der Moderne Salzburg
Mönchsberg 32, Salzburg
Monday, September 12. 2011
Via MIT Technology Review
-----
The Web giant reveals its energy use for the first time.
By Kristina Grifantini
 |
Google power Google developed a new, seawater-based cooling system for its servers in Hamina, Finland.
Credit: Google |
Google is the first major Web company to reveal exactly how much energy it uses—information that will help researchers and policy makers understand how the massive explosion of Internet usage and cloud computing is contributing to global energy consumption.
Google uses 260 million watts continuously across the globe, the company reported on Wednesday. This is equivalent to the power used by all the homes in Richmond, Virginia, or Irvine, California (around 200,000 homes), and roughly a quarter of the output of a standard nuclear power plant.
By far, the majority of Google's energy use is tied up in its data storage centers, according to Jonathan Koomey, a professor at Stanford University and a researcher who focuses on energy and IT. He says that roughly 220 million of those watts are used solely by the company's data centers, based on figures Google showed him. Most of this energy is used in cooling data center systems. Google custom builds many data centers, such as a new one in Finland that uses a seawater cooling system, to cut down on electricity.
This has enabled Google to be relatively energy efficient, says Koomey, who estimates that the company owns about 3 percent of servers worldwide and uses only 1 percent of electricity for data centers worldwide. "They're operating more efficiently than other data centers," he says.
Other Web giants, including Amazon and Facebook, probably operate their data centers with similar efficiency due to hardware and software customization, and innovative cooling equipment, Koomey says. However, the majority of data center power use comes from non-IT companies running their own data centers less efficiently.
In its report, Google compares the energy usage of companies' in-house computer systems to the energy used by its cloud servers. It estimates that running Gmail instead of an in-house e-mail system can be almost 80 times more energy efficient. Google says that 25 percent of its energy was supplied by renewable fuels—such as from wind farms—in 2011, and plan to increase that to 30 percent this year.
Sherif Akoush, a researcher at the University of Cambridge who studies IT energy consumption, points out that Google could be even more energy efficient, and notes that the company's environmental footprint will continue to rise. "Google tackles this problem mainly by using power purchase agreements from green sources, which offset basically the emissions from its data centers," says Akoush. Instead, "it should just try to implement more radical solutions like green energy and be a zero-carbon company instead of pumping waste then trying to clean it up."
Bruce Nordman, a researcher at the Lawrence Berkeley National Laboratory, notes that most IT-related energy usage occurs from homes and offices, and not major data centers.
Google says that an average search uses .3 watt-hours of electricity. But Nordman points out that cutting back on Google searches is not going to save a significant amount of energy. "Something like having your display go to sleep a little faster would probably save more energy," he says.
He adds, "since there's more consumption [in homes and offices], there's potentially more savings and yet that's not what gets the attention."
Copyright Technology Review 2011.
Friday, April 01. 2011
Google has launched a close copy of Facebook's Like button that will crowdsource people's opinions to help the search engine know what's valuable online. Called +1, the button will appear on Web pages and alongside search results, enabling users to signal that they appreciated a piece of content. Google will track clicks of the button to hone search results, using clicks from your friends as a signal of what is most relevant to you.
The search company announced the new feature today, saying:
It's called +1—the digital shorthand for "this is pretty cool."
A YouTube video introduces the feature, which will be "slowly rolling out" on Google.com, at first for users of the English version. Google's new feature is very similar to one built by both rival Bing and search startup Blekko. Both use data from Facebook Like buttons to have your friends' opinions tune your search results.
However, your social network is something of a blind spot to Google, which doesn't have the same understanding of your social connections that Facebook does. Initially the +1s of your Google chat buddies and contacts will be used to "enhance" your results, the company says, while eventually +1s from your Twitter contacts might also be taken into account. At launch, though, +1 seems likely to be somewhat hamstrung by Google's lack of a detailed social "graph" for its users.
When Google previously tried to remedy that, it enraged people by guessing at whom its users were friends with from their e-mail activity, and pitching them into a copy of Twitter called Buzz. Coincidentally, the FTC today delivered its verdict on the debacle, labeling Google's behavior an example of "deceptive privacy practices."
Yet Google's hunger for a better understanding of your social network, and hence whose opinions it should use to tune your search results, is only going to be heightened by the launch of +1. Expect to see Google make renewed efforts to launch features and tools that capture social connections in coming months.
Personal comment:
With the actual hype word "crowdsourced", we can see a bigger trend coming on: the collaboration between a digital network of "universal computer machines" and a physical network of human brains to achieve tasks that humans can't do (as quickly) or that computers are not able to achieve (recaptcha paradigm). We see more and more network applications where computers either allow to organize a network of brains or literally rely on "organic brains" (a big and first exemple to my knowledge being the Mechanical Turk service by Amazon).
It is therefore a double augmentation: the human brain augmented by the networked computer(s) augmented by the brains. We can possibly see the same effects on contemporary space: the physical space augmented by the digital networked/mediated space augmented by the physical space...
Monday, October 04. 2010
-----
A Web startup demos a "predictive" search engine.
By Tom Simonite
 |
Eye candy: This visualization shows the connections between different places, companies, and people, following a search using Recorded Future.
Credit: Recorded Future |
A startup called Recorded Future has developed a tool that scrapes real-time data from the Internet to find hints of what will happen in the future. The company's search tool spits out results on a timeline that stretches into the future as well as the past.
The 18-month-old company gained attention earlier this year after receiving money from the venture capital arms of both Google and the CIA. Now the company has offered a glimpse of how its technology works.
Conventional search engines like Google use links to rank and connect different Web pages. Recorded Future's software goes a level deeper by analyzing the content of pages to track the "invisible" connections between people, places, and events described online.
"That makes it possible for me to look for specific patterns, like product releases expected from Apple in the near future, or to identify when a company plans to invest or expand into India," says Christopher Ahlberg, founder of the Boston-based firm.
A search for information about drug company Merck, for example, generates a timeline showing not only recent news on earnings but also when various drug trials registered with the website clinicaltrials.gov will end in coming years. Another search revealed when various news outlets predict that Facebook will make its initial public offering.
That is done using a constantly updated index of what Ahlberg calls "streaming data," including news articles, filings with government regulators, Twitter updates, and transcripts from earnings calls or political and economic speeches. Recorded Future uses linguistic algorithms to identify specific types of events, such as product releases, mergers, or natural disasters, the date when those events will happen, and related entities such as people, companies, and countries. The tool can also track the sentiment of news coverage about companies, classifying it as either good or bad.
Recorded Future's customer base is currently "sub-100," says Ahlberg. It includes a mix of financial firms, government analysts, and media analysts, who pay a monthly fee to access the online tools. "Government analysts are interested in tracking people and places, while financial services may want to reveal events coming up around particular companies," says Ahlberg.
As well as providing a slick online interface to perform searches that spit out timelines showing the results (see video), Recorded Future offers free e-mail newsletters that tip users off to predictions in specific areas. It also makes it possible for customers to write software that draws on the tool's data and analysis through application programming interfaces, or APIS.
In time, this may lead to the development of apps targeted at consumers, says Ahlberg. "If I'm about to buy an iPhone, I might want to know if I am going to look stupid because they'll launch a new one next week, or how long it usually takes for competitors to launch competing products after a new Apple launch." Financial analysts are already using the company's APIs to overlay or even integrate Recorded Future's data into their own models, he says.
"We have proven out that our data can make strong predictions," says Ahlberg, citing studies that compared Recorded Future's output with changes in the volume of activity around particular financial stocks. "We found that our momentum metric, which indicates the strength of activity around an event or entity, and our future events correlate with the volume of market activity," says Ahlberg.
His company's tools can also be used to work out which sources of information give the best clues as to future events. A recent analysis showed that the posts on one of the Financial Times's blogs were better than other news sources at predicting the performance of companies on the S&P 500 share index. Negative posts about a company correlated with below-market performance a week later, while positive ones correlated with above-market performance.
"What they're really doing here is identifying and collating statements that have been made about the future," says Steven Skiena at the State University of New York at Stony Brook. Skiena developed similar technology used by another startup, General Sentiment, to mine material from news and blogs. "An analyst can use those to inform their own predictions, less risky than Recorded Future actually making predictions themselves."
Various tools are capable of extracting events, people, and companies from text, but aligning that information in time is a trickier task, says Panagiotis Ipeirotis, at New York University's Leonard Stern School of Business. Ipeirotis researches how economically important data can be mined from online news sources and social media. "Analysis of sequences of events is very interesting, and underexploited in the research literature," he says. "Even getting decently timed data of news articles in order to properly generate event sequences is a hard problem."
This focus on the timeline sets Recorded Future apart from other firms trying to gain insights by mining news and other data, says Ipeirotis. "I'm curious to see when other text analytics firms will jump into the trend."
Recorded Future is about to expand its service to cover Arabic and Chinese sources. Making its indexes bigger is a major priority. "I'd like to be able to get in front of every piece of streaming data on the planet," says Ahlberg.
As the databases covered by Recorded Future, General Sentiment, and others grow, more powerful types of analysis will become possible, says Skiena. "I'm currently working with social scientists on models to predict what the probability is that a person that gets few mentions today suddenly becomes very famous in the future, by looking back at years of past data," he says.
Copyright Technology Review 2010.
Personal comment:
This has to be related to this sentence by Google CEO, Eric Schmidt: "I ACTUALLY think most people dont want Google to answer their questions, they want Google to tell them what they should be doing next." (taken from this article/post by William Gibson fro the New York Times).
Oh, really?
Wednesday, September 01. 2010
Via /Message
-----
Google’s Earth - William Gibson (The New York Times):
Google is made of us, a sort of coral reef of human minds and their products.
Gibson wonders about Google’s role in our world, and how it is a reflection of us, a tool that shapes us as we use it.
Personal comment:
Gibson's article starts with this sentence by Eric Schmidt (Google's CEO): "I ACTUALLY think most people dont want Google to answer their questions, said the search giants chief executive, Eric Schmidt, in a recent and controversial interview. They want Google to tell them what they should be doing next.". This probably tells a bit about where Google aims to go.
Wednesday, August 25. 2010
-----
A Yahoo Research tool mines news archives for meaning--illuminating past, present, and even future events.
By Tom Simonite
 |
Time traveler: Time Explorer shows coverage relevant to a search term over time.
Credit: Yahoo Research |
Showing news stories on a timeline has been tried before. But Time Explorer, a prototype news search engine created in Yahoo's Barcelona research lab, generates timelines that stretch into the future as well as the past.
Time Explorer's results page is dominated by an interactive timeline illustrating how the volume of articles for a particular search term has changed over time. The most relevant articles appear on the timeline, showing when they were published. If the user moves the timeline into the future, articles appear positioned at any point in time the text might have referred to.
This provides a new way to discover articles, and also a way to check up on past predictions. The timeline for 2010 becomes a way to discover a 2004 Op-Ed suggesting that by now, North Korea would have constructed some 200 nuclear warheads, or a 2007 article accurately predicting difficult policy decisions for Democrats over the expiration of George Bush's tax cuts.
News organizations are increasingly turning to new ways of presenting their content, including through enhanced forms of search. A Pew research study in 2008 found that 83 percent of people looking for news online use a search engine to find it.
Time Explorer can spot both absolute references to future times, such as "November 2010," and work forward from an article's publication date to figure out relative timings like "an election next month." It also extracts names, locations, and organizations mentioned in articles. These are shown in a box to the right of the results; they can be used to add a person or other entity to the timeline, and to fine-tune results to home in on combinations of particular people or places.
"You can see for wars or any other event not only the people that are important, but when they became important," says Michael Matthews, a member of the Yahoo research team. "The evolution of news over time is not something you can do very easily with tools that are out there today."
Time Explorer was built using a collection of 1.8 million articles released by the New York Times stretching from 1987 to 2007 to stimulate research into new ways of exploring news coverage. Time Explorer was presented, along with other ideas for using the same dataset, at a session of the Human Computer Interaction and Information Retrieval (HCIR) workshop in New Brunswick, NJ, over the weekend. Time Explorer won the most votes from attendees for best use of the Times articles.
Other tools presented at HCIR attempted to assess the authority of people mentioned in an article, determine phrases related to a search term, and rapidly pull together a page summarizing the latest news on a particular topic, for example a celebrity or country.
"For most news search engines, recency is a significant factor for relevance," says Daniel Tunkelang, a tech lead at Google's New York office who chaired the challenge session. "Time Explorer brings an exploratory perspective to the time dimension, letting users see the evolution of a topic over time."
"The slick visualization allows users to discover unexpected relationships between entities at particular points in time--for example, between Slobodan Milosevic and Saddam Hussein," says Tunkelang. Refining a search for the term "Yugoslavia" with the two leaders reveals how, at first, Hussein appears as a point of comparison in coverage of the Serbian leader, but later the two leaders were directly involved, with stories reporting arms deals between them.
Although Time Explorer currently only works with old news, it could also be used to explore new coverage, and to put it in context, says Matthews. "It would be tough to update in real time, but it could certainly be done daily, and I think that would be useful for sure."
He says the service would be best deployed as a tool that works off of the topics in a breaking story. A person reading a news report about, say, Medicaid would find it useful to see the history of coverage on the topic, as well as the predictions made about its future, says Matthews. "It's like a related-articles feature, but focused in the future." He and colleagues are working on adding more up-to-date news sources, as well as content from blogs and other sites to Time Explorer's scope.
The Times has digitized and made searchable its content going back to 1851, yet today's search technologies and interfaces are not up to the task of making such large collections explorable, says Evan Sandhaus, a member of the New York Times Research and Development Labs who oversaw the release of the article archive in late 2008.
"We can say, 'show me all the articles about Barack Obama,' but we don't have a database that can tell us when he was born, or how many books he wrote," says Sandhaus, who adds that tools developed to process the meaning of news articles could have wider uses. "That resource will not only help the research community move the needle for our company but for any company with a large-scale data-management problem."
With most organizations harboring millions of text documents, from e-mails to reports, smarter tools to handle them would likely be popular, Matthews says. "In theory, the underlying algorithms should work on anything, perhaps with a little tweaking."
Copyright Technology Review 2010.
Friday, June 04. 2010
-----
Software offers a running commentary to ease video searching and analysis.
By Tom Simonite
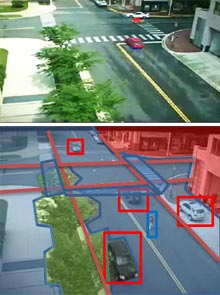 |
Picture this: The objects in a surveillance footage scene (top) are annotated by computer vision software (below).
Credit: Song-Chun Zhu/UCLA |
|
Multimedia
|
A prototype computer vision system can generate a live text description of what's happening in a feed from a surveillance camera. Although not yet ready for commercial use, the system demonstrates how software could make it easier to skim or search through video or image collections. It was developed by researchers at the University of California, Los Angeles, in collaboration with ObjectVideo of Reston, VA.
"You can see from the existence of YouTube and all the other growing sources of video around us that being able to search video is a major problem," says Song-Chun Zhu, lead researcher and professor of statistics and computer science at UCLA.
"Almost all search for images or video is still done using the surrounding text," he says. Zhu and UCLA colleagues Benjamin Yao and Haifeng Gong developed a new system, called I2T (Image to Text), which is intended to change that.
It puts a series of computer vision algorithms into a system that takes images or video frames as input, and spits out summaries of what they depict. "That can be searched using simple text search, so it's very human-friendly," says Zhu.
The team applied the software to surveillance footage in collaboration with Mun Wai Lee of ObjectVideo to demonstrate the strength of I2T. Systems like it might help address the fact that there are more and more surveillance cameras--on the streets and in military equipment, for instance--while the number of people working with them remains about the same, says Zhu.
The first part of I2T is an image parser that decomposes an image--meaning it removes the background, and objects like vehicles, trees, and people. Some objects can be broken down further; for example, the limbs of a person or wheels of a car can be separated from the object they belong to.
Next, the meaning of that collection of shapes is determined. "This knowledge representation step is the most important part of the system," says Zhu, explaining that this knowledge comes from human smarts. In 2005, Zhu established the nonprofit Lotus Hill Institute in Ezhou, China, and, with some support from the Chinese government, recruited about 20 graduates of local art colleges to work full-time to annotate a library of images to aid computer vision systems. The result is a database of more than two million images containing objects that have been identified and classified into more than 500 categories.
To ensure that workers annotate images in a standard way, software guides them as they work. It uses versions of the algorithms that will eventually benefit from the final data to pick out the key objects for a person to classify, and it suggests how they might be classified based on previous data. The objects inside images are classified into a hierarchy of categories based on Princeton's WordNet database, which organizes English words into groups according to their meanings. "Once you have the image parsed using that system that also includes the meaning, transcription into the natural language is not too hard," says Zhu, who makes some of the data available for free to other researchers. "It is high-quality data and we hope that more people are going to use this," he says.
The video-processing system also uses algorithms that can describe the movement of objects in successive frames. It generates sentences like "boat1 follows boat2 between 35:56 and 37:23" or "boat3 approaches maritime marker at 40:01." "Sometimes it can do a match on an object that has left and reentered a scene," says Zhu, "and say, for example, this is probably a certain car again." It is also possible to define virtual "trip wires" to help it describe certain events, like a car running a stop sign (see video).
Although the system demonstrates a step toward what Zhu calls a "grand vision in computer science," I2T is not yet ready for commercialization. Processing surveillance footage is relatively easy for the software because the camera--and hence the background in a scene--is static; I2T is far from capable of recognizing the variety of objects or situations a human could. If set loose on random images or videos found online, for example, I2T would struggle to perform so well.
Improving the system's knowledge of how to identify objects and scenes by adding to the number of images in the Lotus Hill Institute training set should help, says Zhu.
The I2T system underlying the surveillance prototype is powerful, says Zu Kim, a researcher at the University of California, Berkeley, who researches the use of computer vision to aid traffic surveillance and vehicle tracking. "It's a really nice piece of work," he says, even if it can't come close to matching human performance.
Kim explains that better image parsing is relevant to artificial intelligence work of all kinds. "There are very many possibilities for a good image parser--for example, allowing a blind person to understand an image on the Web."
Kim can see other uses for generating text from video, pointing out that it could be fed into a speech synthesizer. "It could be helpful if someone was driving and needed to know what a surveillance camera was seeing." But humans are visual creatures, he adds, and in many situations could be expected to prefer to decide what's happening in an image or a video for themselves.
Copyright Technology Review 2010.
Personal comment:
That's nothing new that surveillance camera are being driven by softwares that analyses the content of the image. The "interesting" point here is that the software creates a text based commentary (a sort of text based substitution of the image and its software analysis) upon which text based search algorythms can be applied to find specific content in a video.
Applied to surveillance camera, this could trigger powerfull surveillance. Applied to other projects, this could be interesting to get text based descriptiond of real time actions in public or private space. Of course, with all the questions about the nature of space that come along with this type of project...
Tuesday, April 20. 2010
-----
Social networking is changing the way we find information.
By Nicholas Carr
 |
The real-time man: Google's Amit Singhal is mining social networks to generate up-to-the-second search results.
Credit: Toby Burditt |
|
Multimedia
|
Amit Singhal
(Google) Real-time search means people will be able to track rapidly changing events
---
OTHERS WORKING ON REAL-TIME SEARCH
Sean Suchter, Microsoft Search Technology Center, Mountain View, CA
OneRiot, Boulder, CO
Sency, Santa Monica, CA
|
How do you parse a tweet? Five years ago, that question would have been gibberish. Today, it's perfectly sensible, and it's at the front of Amit Singhal's mind. Singhal is leading Google's quest to incorporate new data into search results in real time by tracking and ranking updates to online content--particularly the thousands of messages that course through social networks every second.
Real-time search is a response to a fundamental shift in the way people use the Web. People used to visit a page, click a link, and visit another page. Now they spend a lot of time monitoring streams of data--tweets, status updates, headlines--from services like Facebook and Twitter, as well as from blogs and news outlets.
Ephemeral info-nuggets are the Web's new currency, and sifting through them for useful information is a challenge for search engines. Its most daunting aspect, according to Singhal, is not collecting the data. Facebook and Twitter are happy to sell access to their data feeds--or "fire hoses," as they call them--directly to search providers; the information pours straight into Google's computers.
What's really hard about real-time search is figuring out the meaning and value of those fleeting bits of information. The challenge goes beyond filtering out spam, though that's an important part of it. People who search real-time data want the same quality, authority, and relevance that they expect when they perform traditional Web searches. Nobody wants to drink straight from a fire hose.
Google dominates traditional search by meticulously tracking links to a page and other signals of its value as they accumulate over time. But for real-time search, this doesn't work. Social-networking messages can lose their value within minutes of being written. Google has to gauge their worth in seconds, or even microseconds.
Google is notoriously tight-lipped about its search algorithms, but Singhal explains a few of the variables the company uses to analyze what he calls "chatter." Some are straightforward. A Twitter user who attracts many followers, and whose tweets are often "retweeted" by other users, can generally be assumed to have more authority. Similarly, Facebook users gain authority as their friends multiply, particularly if those friends also have many friends.
Other signals are more subtle. A sudden spike in the prevalence of a word in a message stream--earthquake, say--may indicate an important event. If a message on a commonly discussed topic includes unusual phrasing, that may signal new information or a fresh insight. Google, says Singhal, continuously scans for shifts in language and other deviations from predicted behavior.
The company is also working to connect message content to the geolocation data that's transmitted by smart phones and other mobile computers, or broadcast through services like Foursquare. The location of someone sending a message can matter a great deal. If you know that a person tweeting about an earthquake is close to the epicenter, chances are those tweets will be more valuable than those of someone hundreds of miles away.
Singhal's view of real-time search is very much in line with Google's strategy: distilling from a welter of data the few pieces of content that are most relevant to an individual searcher at a particular point in time. Other search providers, including Google's arch rival, Microsoft, are taking a more radical view.
Sean Suchter, who runs Microsoft's Search Technology Center in Mountain View, CA, doesn't like the term real-time search, which he considers too limiting. He thinks Microsoft's Bing search engine should not just filter data flowing from social networks but become an extension of them.
Ultimately, says Suchter, one-on-one conversations will take place within Bing, triggered by the keywords people enter. Real-time search, he predicts, will be so different from what came before that it will erase Google's long-standing advantages. "History doesn't matter here," he says. After a pause, he adds, "We're going to wipe the floor with them."
Amit Singhal has heard such threats before, and so far they haven't amounted to much. But even he admits that real-time search comes as close to marking "a radical break" in the history of search as anything he's seen. Keeping Google on top in the age of chatter may prove to be Singhal's toughest test.
Copyright Technology Review 2010.
Personal comment:
Strategies for finding content in the "real-time web"...
|