





HOLGER MADER, ALEXANDER STUBLIC & HEIKE WIERMANN
in collaboration with the Municipality of Hvidovre and DONG Energy
Monday, March 27. 2017Realms, architecture & videogames | #game #fiction #environments
Note: in direct link with the previous post about vr, this interesting evening discussion next April at the Bartlett School of Architecture about the relation between architecture and videogames (by extension, the architecture of videogames? and/or the architecture in videogames? And maybe even the architecture of fictional environments (BLDGBLOG), if we think about Inception movie or even the recent Dr Strange, with quite surprizing "architecture effects" related to the idea of "bending reality". Or If we go for older references in our own work, this reminds me of projects in which we explored this relation between architecture and artificial environments of games or interactive 3d spaces, like for exemple the MIX-m project (2005) or even La_Fabrique (1999 (!))... Hum.
Via Eventbride (thanks @chrstphggnrd for the ref.) -----
REALMS is an evening discussion on the relationship between video games and architecture held at the Bartlett School of Architecture as part of the London Games Festival 2017. As games become ever more complex and immersive, and architects increasingly adopt game technologies for visualizing and exploring their design ideas, Realms asks what the shared future of the two mediums may be. Might architects turn towards realizing ideas in virtual realms in the face of financial pressures, and what can we learn from the weird and wonderful spatial experiences that games can offer us? REALMS is an evening of informal talks from architects, writers and game developers followed by a panel discussion and audience Q&A. It will provide a platform for the free discussion of how architecture and video games may develop together both technologically and culturally. As part of Realms we will also showcase architecture student work from the Bartlett that deals with the relationship between architecture and video game space. The panel of speakers for REALMS is: Darran Anderson - author of Imaginary Cities, and writer for Killscreen/Versions. @oniropolis James Delaney - founder of Blockworks, one of the world's leading Minecraft builders. @BlockWorksYT Catrina Stewart - architect and founder of Office S&M and architectural designer on BAFTA award winning Lumino City. @CatrinaLStewart Maciek Strychalski - game developer and founder of SMAC Games releasing the upcoming Tokyo 42. @Tokyo42Game Philippa Warr - writer and author, currently working at Rock Paper Shotgun. @philippawarr
Entry is free on a first come first seated basis. Address: Refreshments will be provided.
Realms is supported by the Architecture Projects Fund of the Bartlett, UCL.
Wednesday, July 29. 2015Creating Radical Software: A Personal Account | #magazine #history #media
Note: after the recent post about E.A.T. and while we are into history, here is also an intersting article by Phyllis (Gershuny) Segura, one of the founders of the 1970's journal Radical Software, where she explains the birth and motivatiosn behind the magazine. It was a journal about the then very young video art, but exceeded this thematic by far, including avant-garde thematics such as cybernetic, information theory or networks.
Via Rhizome ----- Creating Radical Software: A Personal Account By Phyllis (Gershuny) Segura
What can be analyzed in my work, or criticized, are the questions that I ask…my composition arises out of asking questions. — John Cage
Radical Software Volume I, Number 1: the Alternate Television Movement (Spring 1970)
Radical Software Volume I, Number 2: the Electromagnetic Spectrum (Autumn 1970).
As rare as it is for something to be an instant success, this is what happened with Radical Software, a journal started in 1970 to bring a fresh direction to communication via personal and portable video equipment and other cybernetic explorations. Its intention was to foster an alternative to broadcast media and lessen the impact of its control. I was the co-founder. When I began conceiving of the journal, no one really knew precisely what I was getting at because my ideas about it were at an inchoate stage of development, making for loose coherency. The idea was for individuals to be able to communicate interactively without the filters of broadcast media. Even at a more formalized stage the process superseded any formulaic views. Perhaps asking non-hierarchical questions could materialize the structures leading to a two-way network for communicative exchange. Our choices were no longer determined by traditions and customs. I don't often look, but when I do, I notice so much misinformation, both printed and online, about the origins of Radical Software. I‘d like to clarify what my role was then and what my inspiration was in conceiving of it. It is important to set the background and tone of events. In order to accurately tell the tale I will weave in some personal life anecdotes from the time. It's all one story to me, as the vicissitudes of life often direct our fates.
(...)
Read more about it HERE.
Related Links:Tuesday, October 26. 2010Christian Marclay: The Clock
As engaging as it is an excellent concept, The Clock is the latest video installation by Christian Marclay now on at the White Cube Mason’s Yard. A chronological collage that pieces film footage into a twenty-four hour clock, using the illusionary devices that carry you through the duration of a cinematic narrative – characters checking watches, dramatic shots of a clock on the mantle piece, etc – by localising the time zone of a fictional event, it’s as if fantasy is replaced with real time. Related Links:Friday, June 04. 2010Surveillance Software Knows What a Camera Sees or Searching into surveillance video content.-----
Software offers a running commentary to ease video searching and analysis.
By Tom Simonite
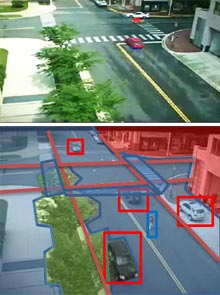
"You can see from the existence of YouTube and all the other growing sources of video around us that being able to search video is a major problem," says Song-Chun Zhu, lead researcher and professor of statistics and computer science at UCLA. "Almost all search for images or video is still done using the surrounding text," he says. Zhu and UCLA colleagues Benjamin Yao and Haifeng Gong developed a new system, called I2T (Image to Text), which is intended to change that. It puts a series of computer vision algorithms into a system that takes images or video frames as input, and spits out summaries of what they depict. "That can be searched using simple text search, so it's very human-friendly," says Zhu. The team applied the software to surveillance footage in collaboration with Mun Wai Lee of ObjectVideo to demonstrate the strength of I2T. Systems like it might help address the fact that there are more and more surveillance cameras--on the streets and in military equipment, for instance--while the number of people working with them remains about the same, says Zhu. The first part of I2T is an image parser that decomposes an image--meaning it removes the background, and objects like vehicles, trees, and people. Some objects can be broken down further; for example, the limbs of a person or wheels of a car can be separated from the object they belong to. Next, the meaning of that collection of shapes is determined. "This knowledge representation step is the most important part of the system," says Zhu, explaining that this knowledge comes from human smarts. In 2005, Zhu established the nonprofit Lotus Hill Institute in Ezhou, China, and, with some support from the Chinese government, recruited about 20 graduates of local art colleges to work full-time to annotate a library of images to aid computer vision systems. The result is a database of more than two million images containing objects that have been identified and classified into more than 500 categories. To ensure that workers annotate images in a standard way, software guides them as they work. It uses versions of the algorithms that will eventually benefit from the final data to pick out the key objects for a person to classify, and it suggests how they might be classified based on previous data. The objects inside images are classified into a hierarchy of categories based on Princeton's WordNet database, which organizes English words into groups according to their meanings. "Once you have the image parsed using that system that also includes the meaning, transcription into the natural language is not too hard," says Zhu, who makes some of the data available for free to other researchers. "It is high-quality data and we hope that more people are going to use this," he says. The video-processing system also uses algorithms that can describe the movement of objects in successive frames. It generates sentences like "boat1 follows boat2 between 35:56 and 37:23" or "boat3 approaches maritime marker at 40:01." "Sometimes it can do a match on an object that has left and reentered a scene," says Zhu, "and say, for example, this is probably a certain car again." It is also possible to define virtual "trip wires" to help it describe certain events, like a car running a stop sign (see video). Although the system demonstrates a step toward what Zhu calls a "grand vision in computer science," I2T is not yet ready for commercialization. Processing surveillance footage is relatively easy for the software because the camera--and hence the background in a scene--is static; I2T is far from capable of recognizing the variety of objects or situations a human could. If set loose on random images or videos found online, for example, I2T would struggle to perform so well. Improving the system's knowledge of how to identify objects and scenes by adding to the number of images in the Lotus Hill Institute training set should help, says Zhu. The I2T system underlying the surveillance prototype is powerful, says Zu Kim, a researcher at the University of California, Berkeley, who researches the use of computer vision to aid traffic surveillance and vehicle tracking. "It's a really nice piece of work," he says, even if it can't come close to matching human performance. Kim explains that better image parsing is relevant to artificial intelligence work of all kinds. "There are very many possibilities for a good image parser--for example, allowing a blind person to understand an image on the Web." Kim can see other uses for generating text from video, pointing out that it could be fed into a speech synthesizer. "It could be helpful if someone was driving and needed to know what a surveillance camera was seeing." But humans are visual creatures, he adds, and in many situations could be expected to prefer to decide what's happening in an image or a video for themselves. Copyright Technology Review 2010. Personal comment:
That's nothing new that surveillance camera are being driven by softwares that analyses the content of the image. The "interesting" point here is that the software creates a text based commentary (a sort of text based substitution of the image and its software analysis) upon which text based search algorythms can be applied to find specific content in a video. Tuesday, March 16. 2010Chatroulette + Improv Piano Player = Love! [VIDEO]
The webcam network has quickly ascended to become one of the web’s biggest phenomenons. The anonymous webcam network, estimated to be made up of 71% males, 15% females, and 14% perverts, has gained huge traffic that has attracted venture capital interest and, of course, funny viral videos. The Chatroulette improv piano player, who we found via the Huffington Post, uses only his playing prowess and freestyle vocal to entertain random dudes and win the hearts of teenage girls in hilarious fashion. It’s no wonder this video’s already going viral. Watch and listen to the improv piano man himself; you won’t regret it: ----- Via Mashable Personal comment: Funny behaviours and mode of communication generated by "the chatroulette"... At least one post about it on this blog... Wednesday, January 20. 2010Rainforests Destroyed as Fast as a Field of Matches
Photo via Greenpeace While the rate of deforestation in the Amazon rainforest may be declining, it and other rainforests around the world continue to be cleared at an alarming rate. Figures that are quite alarming, like the fact that 17 percent of the Amazon rainforest has been decimated and 74 million hectares of Indonesian forests were completely destroyed, tend to lose their potency due to their unimaginable scope. Put in more manageable terms, every two seconds an area of forest the size of a soccer field is being destroyed in the world--a fact brought to life by this intriguing animation. The video was produced by Greenpeace in Switzerland, and illustrates just how quickly the world is losing its rainforests, like the oldest in Indonesia and the largest in the Amazon. But, more than just losing forest cover, deforestation devastates habitats and unique ecosystems--threatening a multitude of species found nowhere else on earth. For example, according to Greenpeace, the number of Sumatran orangutans has decreased 91% since 1991. A similar fate awaits countless other species if the rate of deforestation does not drop dramatically. In most cases, agricultural development and logging are the biggest threats to the world's forests--practices policies have been put in place to curb. Nevertheless, it continues and progress has come in fits and starts. It would benefit the concerned spectator of environmental affairs to bear in the mind the video when deciding what action should be taken to combat the problem, for there is much more at stake than a soccer field made of matchsticks. More on Deforestation ----- Via Treehugger Personal comment: Vidéo édifiante... Tuesday, January 05. 2010Expanded space7th December 09 - 18th December 09
HOLGER MADER, ALEXANDER STUBLIC & HEIKE WIERMANN in collaboration with the Municipality of Hvidovre and DONG Energy  © Mader, Stublic, Wiermann
PLAYFUL URBAN SPACE – ENERGY IN MOVEMENT The art group Mader Stublic Wiermann transforms DONG Energy’s power station Avedøreværket into a 145 metre tall screen for spectacular light and video installations following the movement of the wind. An extraordinary image of the energy of the future and a showcase for wind power and the highly efficient and flexible power plants, which will reduce CO2 emissions and provide everyone with sufficient energy and heating. Travellers to and from Copenhagen will be met with a sensational sight when the 145 metre tall projections light up the dark hours. The projections will be visible from the air if flying in and out of Kastrup Airport; from Sjællandsbroen and Kalvebodbroen if travelling by car on the way to or from work; from the S-Train stations Avedøre and Friheden and in and around the Hvidovre area.
Via Lyslyd.com Related Links: |
fabric | rblgThis blog is the survey website of fabric | ch - studio for architecture, interaction and research. We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings. Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations. This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.
QuicksearchCategoriesCalendar
Syndicate This BlogArchivesBlog Administration |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
