Friday, June 04. 2010
Surveillance Software Knows What a Camera Sees or Searching into surveillance video content.
 |
||
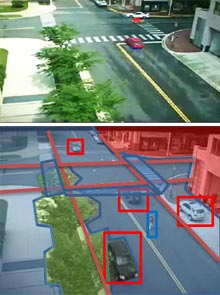
| Picture this: The objects in a surveillance footage scene (top) are annotated by computer vision software (below). Credit: Song-Chun Zhu/UCLA |
||
|
Multimedia
|

"You can see from the existence of YouTube and all the other growing sources of video around us that being able to search video is a major problem," says Song-Chun Zhu, lead researcher and professor of statistics and computer science at UCLA.
"Almost all search for images or video is still done using the surrounding text," he says. Zhu and UCLA colleagues Benjamin Yao and Haifeng Gong developed a new system, called I2T (Image to Text), which is intended to change that.
It puts a series of computer vision algorithms into a system that takes images or video frames as input, and spits out summaries of what they depict. "That can be searched using simple text search, so it's very human-friendly," says Zhu.
The team applied the software to surveillance footage in collaboration with Mun Wai Lee of ObjectVideo to demonstrate the strength of I2T. Systems like it might help address the fact that there are more and more surveillance cameras--on the streets and in military equipment, for instance--while the number of people working with them remains about the same, says Zhu.
The first part of I2T is an image parser that decomposes an image--meaning it removes the background, and objects like vehicles, trees, and people. Some objects can be broken down further; for example, the limbs of a person or wheels of a car can be separated from the object they belong to.
Next, the meaning of that collection of shapes is determined. "This knowledge representation step is the most important part of the system," says Zhu, explaining that this knowledge comes from human smarts. In 2005, Zhu established the nonprofit Lotus Hill Institute in Ezhou, China, and, with some support from the Chinese government, recruited about 20 graduates of local art colleges to work full-time to annotate a library of images to aid computer vision systems. The result is a database of more than two million images containing objects that have been identified and classified into more than 500 categories.
To ensure that workers annotate images in a standard way, software guides them as they work. It uses versions of the algorithms that will eventually benefit from the final data to pick out the key objects for a person to classify, and it suggests how they might be classified based on previous data. The objects inside images are classified into a hierarchy of categories based on Princeton's WordNet database, which organizes English words into groups according to their meanings. "Once you have the image parsed using that system that also includes the meaning, transcription into the natural language is not too hard," says Zhu, who makes some of the data available for free to other researchers. "It is high-quality data and we hope that more people are going to use this," he says.
The video-processing system also uses algorithms that can describe the movement of objects in successive frames. It generates sentences like "boat1 follows boat2 between 35:56 and 37:23" or "boat3 approaches maritime marker at 40:01." "Sometimes it can do a match on an object that has left and reentered a scene," says Zhu, "and say, for example, this is probably a certain car again." It is also possible to define virtual "trip wires" to help it describe certain events, like a car running a stop sign (see video).
Although the system demonstrates a step toward what Zhu calls a "grand vision in computer science," I2T is not yet ready for commercialization. Processing surveillance footage is relatively easy for the software because the camera--and hence the background in a scene--is static; I2T is far from capable of recognizing the variety of objects or situations a human could. If set loose on random images or videos found online, for example, I2T would struggle to perform so well.
Improving the system's knowledge of how to identify objects and scenes by adding to the number of images in the Lotus Hill Institute training set should help, says Zhu.
The I2T system underlying the surveillance prototype is powerful, says Zu Kim, a researcher at the University of California, Berkeley, who researches the use of computer vision to aid traffic surveillance and vehicle tracking. "It's a really nice piece of work," he says, even if it can't come close to matching human performance.
Kim explains that better image parsing is relevant to artificial intelligence work of all kinds. "There are very many possibilities for a good image parser--for example, allowing a blind person to understand an image on the Web."
Kim can see other uses for generating text from video, pointing out that it could be fed into a speech synthesizer. "It could be helpful if someone was driving and needed to know what a surveillance camera was seeing." But humans are visual creatures, he adds, and in many situations could be expected to prefer to decide what's happening in an image or a video for themselves.
Copyright Technology Review 2010.
Personal comment:
That's nothing new that surveillance camera are being driven by softwares that analyses the content of the image. The "interesting" point here is that the software creates a text based commentary (a sort of text based substitution of the image and its software analysis) upon which text based search algorythms can be applied to find specific content in a video.
Applied to surveillance camera, this could trigger powerfull surveillance. Applied to other projects, this could be interesting to get text based descriptiond of real time actions in public or private space. Of course, with all the questions about the nature of space that come along with this type of project...
fabric | rblg
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.
Quicksearch
Categories
Calendar
|
|
July '25 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 | |||
