Sticky Postings
By fabric | ch
-----
As we continue to lack a decent search engine on this blog and as we don't use a "tag cloud" ... This post could help navigate through the updated content on | rblg (as of 09.2023), via all its tags!
FIND BELOW ALL THE TAGS THAT CAN BE USED TO NAVIGATE IN THE CONTENTS OF | RBLG BLOG:
(to be seen just below if you're navigating on the blog's html pages or here for rss readers)
--
Note that we had to hit the "pause" button on our reblogging activities a while ago (mainly because we ran out of time, but also because we received complaints from a major image stock company about some images that were displayed on | rblg, an activity that we felt was still "fair use" - we've never made any money or advertised on this site).
Nevertheless, we continue to publish from time to time information on the activities of fabric | ch, or content directly related to its work (documentation).
Friday, February 01. 2019
Note: Yet another dive into history of computer programming and algorithms, used for visual outputs ...
Via The New York Times (on Medium)
-----
By Siobhan Roberts

Donald Knuth at his home in Stanford, Calif. He is a notorious perfectionist and has offered to pay a reward to anyone who finds a mistake in any of his books. Photo: Brian Flaherty
For half a century, the Stanford computer scientist Donald Knuth, who bears a slight resemblance to Yoda — albeit standing 6-foot-4 and wearing glasses — has reigned as the spirit-guide of the algorithmic realm.
He is the author of “The Art of Computer Programming,” a continuing four-volume opus that is his life’s work. The first volume debuted in 1968, and the collected volumes (sold as a boxed set for about $250) were included by American Scientist in 2013 on its list of books that shaped the last century of science — alongside a special edition of “The Autobiography of Charles Darwin,” Tom Wolfe’s “The Right Stuff,” Rachel Carson’s “Silent Spring” and monographs by Albert Einstein, John von Neumann and Richard Feynman.
With more than one million copies in print, “The Art of Computer Programming” is the Bible of its field. “Like an actual bible, it is long and comprehensive; no other book is as comprehensive,” said Peter Norvig, a director of research at Google. After 652 pages, volume one closes with a blurb on the back cover from Bill Gates: “You should definitely send me a résumé if you can read the whole thing.”
The volume opens with an excerpt from “McCall’s Cookbook”:
Here is your book, the one your thousands of letters have asked us to publish. It has taken us years to do, checking and rechecking countless recipes to bring you only the best, only the interesting, only the perfect.
Inside are algorithms, the recipes that feed the digital age — although, as Dr.Knuth likes to point out, algorithms can also be found on Babylonian tablets from 3,800 years ago. He is an esteemed algorithmist; his name is attached to some of the field’s most important specimens, such as the Knuth-Morris-Pratt string-searching algorithm. Devised in 1970, it finds all occurrences of a given word or pattern of letters in a text — for instance, when you hit Command+F to search for a keyword in a document.
Now 80, Dr. Knuth usually dresses like the youthful geek he was when he embarked on this odyssey: long-sleeved T-shirt under a short-sleeved T-shirt, with jeans, at least at this time of year. In those early days, he worked close to the machine, writing “in the raw,” tinkering with the zeros and ones.
“Knuth made it clear that the system could actually be understood all the way down to the machine code level,” said Dr. Norvig. Nowadays, of course, with algorithms masterminding (and undermining) our very existence, the average programmer no longer has time to manipulate the binary muck, and works instead with hierarchies of abstraction, layers upon layers of code — and often with chains of code borrowed from code libraries. But an elite class of engineers occasionally still does the deep dive.
“Here at Google, sometimes we just throw stuff together,” Dr. Norvig said, during a meeting of the Google Trips team, in Mountain View, Calif. “But other times, if you’re serving billions of users, it’s important to do that efficiently. A 10-per-cent improvement in efficiency can work out to billions of dollars, and in order to get that last level of efficiency, you have to understand what’s going on all the way down.”

Dr. Knuth at the California Institute of Technology, where he received his Ph.D. in 1963. Photo: Jill Knuth
Or, as Andrei Broder, a distinguished scientist at Google and one of Dr. Knuth’s former graduate students, explained during the meeting: “We want to have some theoretical basis for what we’re doing. We don’t want a frivolous or sloppy or second-rate algorithm. We don’t want some other algorithmist to say, ‘You guys are morons.’”
The Google Trips app, created in 2016, is an “orienteering algorithm” that maps out a day’s worth of recommended touristy activities. The team was working on “maximizing the quality of the worst day” — for instance, avoiding sending the user back to the same neighborhood to see different sites. They drew inspiration from a 300-year-old algorithm by the Swiss mathematician Leonhard Euler, who wanted to map a route through the Prussian city of Königsberg that would cross each of its seven bridges only once. Dr. Knuth addresses Euler’s classic problem in the first volume of his treatise. (He once applied Euler’s method in coding a computer-controlled sewing machine.)
Following Dr. Knuth’s doctrine helps to ward off moronry. He is known for introducing the notion of “literate programming,” emphasizing the importance of writing code that is readable by humans as well as computers — a notion that nowadays seems almost twee. Dr. Knuth has gone so far as to argue that some computer programs are, like Elizabeth Bishop’s poems and Philip Roth’s “American Pastoral,” works of literature worthy of a Pulitzer.
He is also a notorious perfectionist. Randall Munroe, the xkcd cartoonist and author of “Thing Explainer,” first learned about Dr. Knuth from computer-science people who mentioned the reward money Dr. Knuth pays to anyone who finds a mistake in any of his books. As Mr. Munroe recalled, “People talked about getting one of those checks as if it was computer science’s Nobel Prize.”
Dr. Knuth’s exacting standards, literary and otherwise, may explain why his life’s work is nowhere near done. He has a wager with Sergey Brin, the co-founder of Google and a former student (to use the term loosely), over whether Mr. Brin will finish his Ph.D. before Dr. Knuth concludes his opus.
The dawn of the algorithm
At age 19, Dr. Knuth published his first technical paper, “The Potrzebie System of Weights and Measures,” in Mad magazine. He became a computer scientist before the discipline existed, studying mathematics at what is now Case Western Reserve University in Cleveland. He looked at sample programs for the school’s IBM 650 mainframe, a decimal computer, and, noticing some inadequacies, rewrote the software as well as the textbook used in class. As a side project, he ran stats for the basketball team, writing a computer program that helped them win their league — and earned a segment by Walter Cronkite called “The Electronic Coach.”
During summer vacations, Dr. Knuth made more money than professors earned in a year by writing compilers. A compiler is like a translator, converting a high-level programming language (resembling algebra) to a lower-level one (sometimes arcane binary) and, ideally, improving it in the process. In computer science, “optimization” is truly an art, and this is articulated in another Knuthian proverb: “Premature optimization is the root of all evil.”
Eventually Dr. Knuth became a compiler himself, inadvertently founding a new field that he came to call the “analysis of algorithms.” A publisher hired him to write a book about compilers, but it evolved into a book collecting everything he knew about how to write for computers — a book about algorithms.


Left: Dr. Knuth in 1981, looking at the 1957 Mad magazine issue that contained his first technical article. He was 19 when it was published. Photo: Jill Knuth. Right: “The Art of Computer Programming,” volumes 1–4. “Send me a résumé if you can read the whole thing,” Bill Gates wrote in a blurb. Photo: Brian Flaherty
“By the time of the Renaissance, the origin of this word was in doubt,” it began. “And early linguists attempted to guess at its derivation by making combinations like algiros [painful] + arithmos [number].’” In fact, Dr. Knuth continued, the namesake is the 9th-century Persian textbook author Abū ‘Abd Allāh Muhammad ibn Mūsā al-Khwārizmī, Latinized as Algorithmi. Never one for half measures, Dr. Knuth went on a pilgrimage in 1979 to al-Khwārizmī’s ancestral homeland in Uzbekistan.
When Dr. Knuth started out, he intended to write a single work. Soon after, computer science underwent its Big Bang, so he reimagined and recast the project in seven volumes. Now he metes out sub-volumes, called fascicles. The next installation, “Volume 4, Fascicle 5,” covering, among other things, “backtracking” and “dancing links,” was meant to be published in time for Christmas. It is delayed until next April because he keeps finding more and more irresistible problems that he wants to present.
In order to optimize his chances of getting to the end, Dr. Knuth has long guarded his time. He retired at 55, restricted his public engagements and quit email (officially, at least). Andrei Broder recalled that time management was his professor’s defining characteristic even in the early 1980s.
Dr. Knuth typically held student appointments on Friday mornings, until he started spending his nights in the lab of John McCarthy, a founder of artificial intelligence, to get access to the computers when they were free. Horrified by what his beloved book looked like on the page with the advent of digital publishing, Dr. Knuth had gone on a mission to create the TeX computer typesetting system, which remains the gold standard for all forms of scientific communication and publication. Some consider it Dr. Knuth’s greatest contribution to the world, and the greatest contribution to typography since Gutenberg.
This decade-long detour took place back in the age when computers were shared among users and ran faster at night while most humans slept. So Dr. Knuth switched day into night, shifted his schedule by 12 hours and mapped his student appointments to Fridays from 8 p.m. to midnight. Dr. Broder recalled, “When I told my girlfriend that we can’t do anything Friday night because Friday night at 10 I have to meet with my adviser, she thought, ‘This is something that is so stupid it must be true.’”
When Knuth chooses to be physically present, however, he is 100-per-cent there in the moment. “It just makes you happy to be around him,” said Jennifer Chayes, a managing director of Microsoft Research. “He’s a maximum in the community. If you had an optimization function that was in some way a combination of warmth and depth, Don would be it.”

Dr. Knuth discussing typefaces with Hermann Zapf, the type designer. Many consider Dr. Knuth’s work on the TeX computer typesetting system to be the greatest contribution to typography since Gutenberg. Photo: Bettmann/Getty Images
Sunday with the algorithmist
Dr. Knuth lives in Stanford, and allowed for a Sunday visitor. That he spared an entire day was exceptional — usually his availability is “modulo nap time,” a sacred daily ritual from 1 p.m. to 4 p.m. He started early, at Palo Alto’s First Lutheran Church, where he delivered a Sunday school lesson to a standing-room-only crowd. Driving home, he got philosophical about mathematics.
“I’ll never know everything,” he said. “My life would be a lot worse if there was nothing I knew the answers about, and if there was nothing I didn’t know the answers about.” Then he offered a tour of his “California modern” house, which he and his wife, Jill, built in 1970. His office is littered with piles of U.S.B. sticks and adorned with Valentine’s Day heart art from Jill, a graphic designer. Most impressive is the music room, built around his custom-made, 812-pipe pipe organ. The day ended over beer at a puzzle party.
Puzzles and games — and penning a novella about surreal numbers, and composing a 90-minute multimedia musical pipe-dream, “Fantasia Apocalyptica” — are the sorts of things that really tickle him. One section of his book is titled, “Puzzles Versus the Real World.” He emailed an excerpt to the father-son team of Martin Demaine, an artist, and Erik Demaine, a computer scientist, both at the Massachusetts Institute of Technology, because Dr. Knuth had included their “algorithmic puzzle fonts.”
“I was thrilled,” said Erik Demaine. “It’s an honor to be in the book.” He mentioned another Knuth quotation, which serves as the inspirational motto for the biannual “FUN with Algorithms” conference: “Pleasure has probably been the main goal all along.”
But then, Dr. Demaine said, the field went and got practical. Engineers and scientists and artists are teaming up to solve real-world problems — protein folding, robotics, airbags — using the Demaines’s mathematical origami designs for how to fold paper and linkages into different shapes.
Of course, all the algorithmic rigmarole is also causing real-world problems. Algorithms written by humans — tackling harder and harder problems, but producing code embedded with bugs and biases — are troubling enough. More worrisome, perhaps, are the algorithms that are not written by humans, algorithms written by the machine, as it learns.
Programmers still train the machine, and, crucially, feed it data. (Data is the new domain of biases and bugs, and here the bugs and biases are harder to find and fix). However, as Kevin Slavin, a research affiliate at M.I.T.’s Media Lab said, “We are now writing algorithms we cannot read. That makes this a unique moment in history, in that we are subject to ideas and actions and efforts by a set of physics that have human origins without human comprehension.” As Slavin has often noted, “It’s a bright future, if you’re an algorithm.”

Dr. Knuth at his desk at home in 1999. Photo: Jill Knuth

A few notes. Photo: Brian Flaherty
All the more so if you’re an algorithm versed in Knuth. “Today, programmers use stuff that Knuth, and others, have done as components of their algorithms, and then they combine that together with all the other stuff they need,” said Google’s Dr. Norvig.
“With A.I., we have the same thing. It’s just that the combining-together part will be done automatically, based on the data, rather than based on a programmer’s work. You want A.I. to be able to combine components to get a good answer based on the data. But you have to decide what those components are. It could happen that each component is a page or chapter out of Knuth, because that’s the best possible way to do some task.”
Lucky, then, Dr. Knuth keeps at it. He figures it will take another 25 years to finish “The Art of Computer Programming,” although that time frame has been a constant since about 1980. Might the algorithm-writing algorithms get their own chapter, or maybe a page in the epilogue? “Definitely not,” said Dr. Knuth.
“I am worried that algorithms are getting too prominent in the world,” he added. “It started out that computer scientists were worried nobody was listening to us. Now I’m worried that too many people are listening.”
Tuesday, March 07. 2017
Note: I recently found out about this curious rosettacode.org projects that presents brief solutions of the same task in "as many languages as possible" (rem.: programming languages in this case). Therefore this name, Rosetta Code. Pointing of course to the Rosetta stone that was key to understand hieroglyphs.
The project presents itself as a "programming chrestomathy" site and counts 648 programing languages so far! (839 tasks done... and counting). Babelian (programming) task ... that could possibly help restore old coded pieces.
Via Rosetta Code
-----

(From the site:)
Rosetta Code
Rosetta Code is a programming chrestomathy site. The idea is to present solutions to the same task in as many different languages as possible, to demonstrate how languages are similar and different, and to aid a person with a grounding in one approach to a problem in learning another. Rosetta Code currently has 839 tasks, 202 draft tasks, and is aware of 648 languages, though we do not (and cannot) have solutions to every task in every language.
Monday, February 06. 2017
Note: following the two previous posts about algorythms and bots ("how do they ... ?), here comes a third one.
Slighty different and not really dedicated to bots per se, but which could be considered as related to "machinic intelligence" nonetheless. This time it concerns techniques and algoritms developed to understand the brain (BRAIN initiative, or in Europe the competing Blue Brain Project).
In a funny reversal, scientists applied techniques and algorythms developed to track human intelligence patterns based on data sets to the computer itself. How do a simple chip "compute information"? And the results are surprising: the computer doesn't understand how the computer "thinks" (or rather works in this case)!
This to confirm that the brain is certainly not a computer (made out of flesh)...
Via MIT Technology Review
-----
Neuroscience Can’t Explain How an Atari Works
By Jamie Condlife
When you apply tools used to analyze the human brain to a computer chip that plays Donkey Kong, can they reveal how the hardware works?
Many research schemes, such as the U.S. government’s BRAIN initiative, are seeking to build huge and detailed data sets that describe how cells and neural circuits are assembled. The hope is that using algorithms to analyze the data will help scientists understand how the brain works.
But those kind of data sets don’t yet exist. So Eric Jonas of the University of California, Berkeley, and Konrad Kording from the Rehabilitation Institute of Chicago and Northwestern University wondered if they could use their analytical software to work out how a simpler system worked.

They settled on the iconic MOS 6502 microchip, which was found inside the Apple I, the Commodore 64, and the Atari Video Game System. Unlike the brain, this slab of silicon is built by humans and fully understood, down to the last transistor.
The researchers wanted to see how accurately their software could describe its activity. Their idea: have the chip run different games—including Donkey Kong, Space Invaders, and Pitfall, which have already been mastered by some AIs—and capture the behavior of every single transistor as it did so (creating about 1.5 GB per second of data in the process). Then they would turn their analytical tools loose on the data to see if they could explain how the microchip actually works.

For instance, they used algorithms that could probe the structure of the chip—essentially the electronic equivalent of a connectome of the brain—to establish the function of each area. While the analysis could determine that different transistors played different roles, the researchers write in PLOS Computational Biology, the results “still cannot get anywhere near an understanding of the way the processor really works.”
Elsewhere, Jonas and Kording removed a transistor from the microchip to find out what happened to the game it was running—analogous to so-called lesion studies where behavior is compared before and after the removal of part of the brain. While the removal of some transistors stopped the game from running, the analysis was unable to explain why that was the case.

In these and other analyses, the approaches provided interesting results—but not enough detail to confidently describe how the microchip worked. “While some of the results give interesting hints as to what might be going on,” explains Jonas, “the gulf between what constitutes ‘real understanding’ of the processor and what we can discover with these techniques was surprising.”
It’s worth noting that chips and brains are rather different: synapses work differently from logic gates, for instance, and the brain doesn’t distinguish between software and hardware like a computer. Still, the results do, according to the researchers, highlight some considerations for establishing brain understanding from huge, detailed data sets.
First, simply amassing a handful of high-quality data sets of the brains may not be enough for us to make sense of neural processes. Second, without many detailed data sets to analyze just yet, neuroscientists ought to remain aware that their tools may provide results that don’t fully describe the brain’s function.
As for the question of whether neuroscience can explain how an Atari works? At the moment, not really.
(Read more: “Google's AI Masters Space Invaders (But It Still Stinks at Pac-Man),” “Government Seeks High-Fidelity ‘Brain-Computer’ Interface”)
Thursday, January 26. 2017
Note: I just read this piece of news last day about Echo (Amazon's "robot assistant"), who accidentally attempted to buy large amount of toys by (always) listening and misunderstanding a phrase being told on TV by a presenter (and therefore captured by Echo in the living room and so on)... It is so "stupid" (I mean, we can see how the act of buying linked to these so-called "A.I"s is automatized by default configuration), but revealing of the kind of feedback loops that can happen with automatized decision delegated to bots and machines.
Interesting word appearing in this context is, btw, "accidentally".
Via Endgadget
-----
By Jon Fingas
Amazon's Echo attempted a TV-fueled shopping spree

It's nothing new for voice-activated devices to behave badly when they misinterpret dialogue -- just ask anyone watching a Microsoft gaming event with a Kinect-equipped Xbox One nearby. However, Amazon's Echo devices is causing more of that chaos than usual. It started when a 6-year-old Dallas girl inadvertently ordered cookies and a dollhouse from Amazon by saying what she wanted. It was a costly goof ($170), but nothing too special by itself. However, the response to that story sent things over the top. When San Diego's CW6 discussed the snafu on a morning TV show, one of the hosts made the mistake of saying that he liked when the girl said "Alexa ordered me a dollhouse." You can probably guess what happened next.
Sure enough, the channel received multiple reports from viewers whose Echo devices tried to order dollhouses when they heard the TV broadcast. It's not clear that any of the purchases went through, but it no doubt caused some panic among people who weren't planning to buy toys that day.
It's easy to avoid this if you're worried: you can require a PIN code to make purchases through the Echo or turn off ordering altogether. You can also change the wake word so that TV personalities won't set off your speaker in the first place. However, this comedy of errors also suggests that there's a lot of work to be done on smart speakers before they're truly trustworthy. They may need to disable purchases by default, for example, and learn to recognize individual voices so that they won't respond to everyone who says the magic words. Until then, you may see repeats in the future.
Tuesday, July 05. 2016
Note: in the continuity of my previous post/documentation concerning the project Platform of Future-Past (fabric | ch's recent winning competition proposal), I publish additional images (several) and explanations about the second phase of the Platform project, for which we were mandated by Canton de Vaud (SiPAL).
The first part of this article gives complementary explanations about the project, but I also take the opportunity to post related works and researches we've done in parallel about particular implications of the platform proposal. This will hopefully bring a neater understanding to the way we try to combine experimentations-exhibitions, the creation of "tools" and the design of larger proposals in our open and process of work.
Notably, these related works concerned the approach to data, the breaking of the environment into computable elements and the inevitable questions raised by their uses as part of a public architecture project.

The information pavilion was potentially a slow, analog and digital "shape/experience shifter", as it was planned to be built in several succeeding steps over the years and possibly "reconfigure" to sense and look at its transforming surroundings.
The pavilion conserved therefore an unfinished flavour as part of its DNA, inspired by these old kind of meshed constructions (bamboo scaffoldings), almost sketched. This principle of construction was used to help "shift" if/when necessary.
 
 
In a general sense, the pavilion answered the conventional public program of an observation deck about a construction site. It also served the purpose of documenting the ongoing building process that often comes along. By doing so, we turned the "monitoring dimension" (production of data) of such a program into a base element of our proposal. That's where a former experimental installation helped us: Heterochrony.
As it can be noticed, the word "Public" was added to the title of the project between the two phases, to become Public Platform of Future-Past (PPoFP) ... which we believe was important to add. This because it was envisioned that the PPoFP would monitor and use environmental data concerning the direct surroundings of the information pavilion (but NO DATA about uses/users). Data that we stated in this case Public, while the treatment of the monitored data would also become part of the project, "architectural" (more below about it).
For these monitored data to stay public, so as for the space of the pavilion itself that would be part of the public domain and physically extends it, we had to ensure that these data wouldn't be used by a third party private service. We were in need to keep an eye on the algorithms that would treat the spatial data. Or best, write them according to our design goals (more about it below).
That's were architecture meets code and data (again) obviously...
By fabric | ch
-----

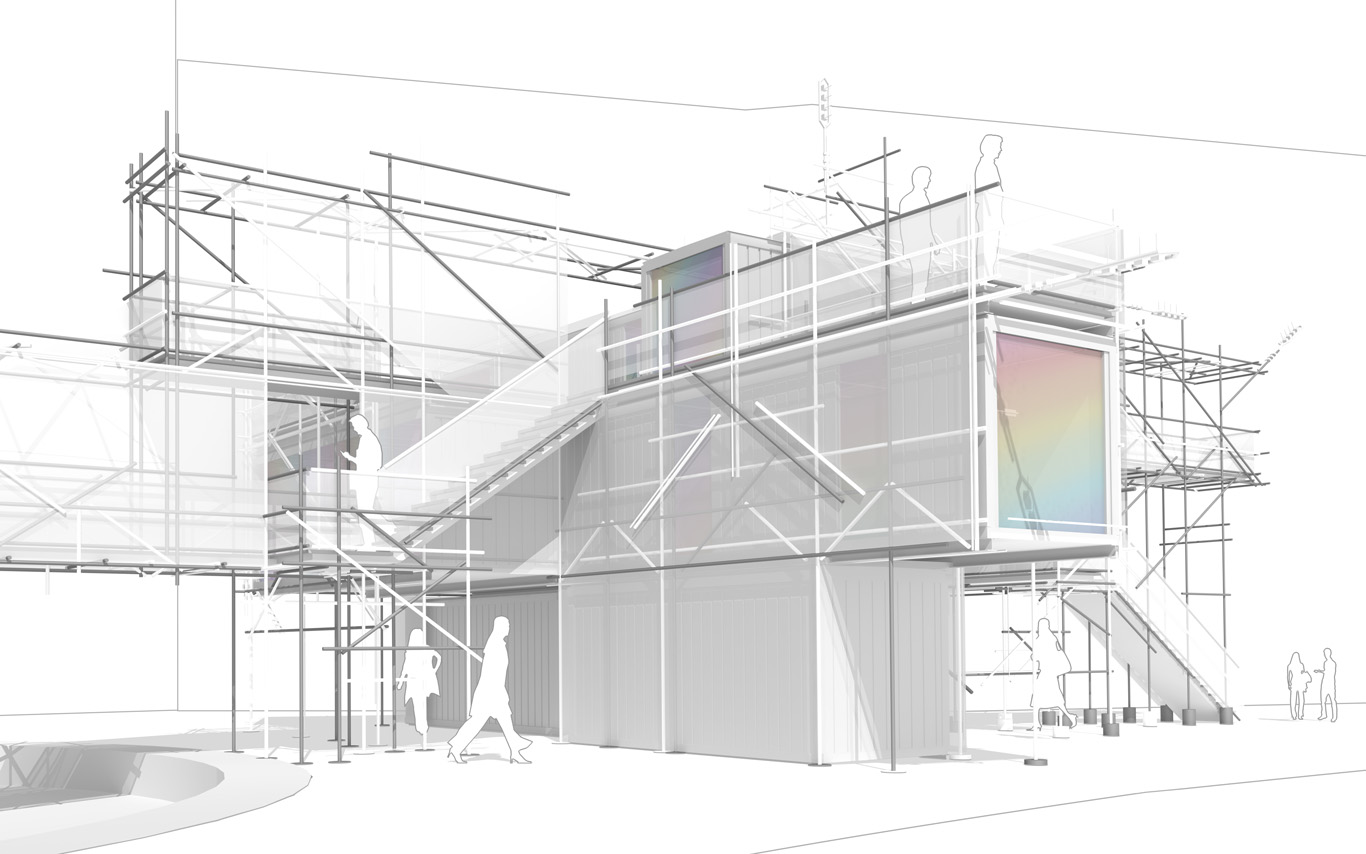
The Public Platform of Future-Past is a structure (an information and sightseeing pavilion), a Platform that overlooks an existing Public site while basically taking it as it is, in a similar way to an archeological platform over an excavation site.
The asphalt ground floor remains virtually untouched, with traces of former uses kept as they are, some quite old (a train platform linked to an early XXth century locomotives hall), some less (painted parking spaces). The surrounding environment will move and change consideralby over the years while new constructions will go on. The pavilion will monitor and document these changes. Therefore the last part of its name: "Future-Past".
By nonetheless touching the site in a few points, the pavilion slightly reorganizes the area and triggers spaces for a small new outdoor cafe and a bikes parking area. This enhanced ground floor program can work by itself, seperated from the upper floors.
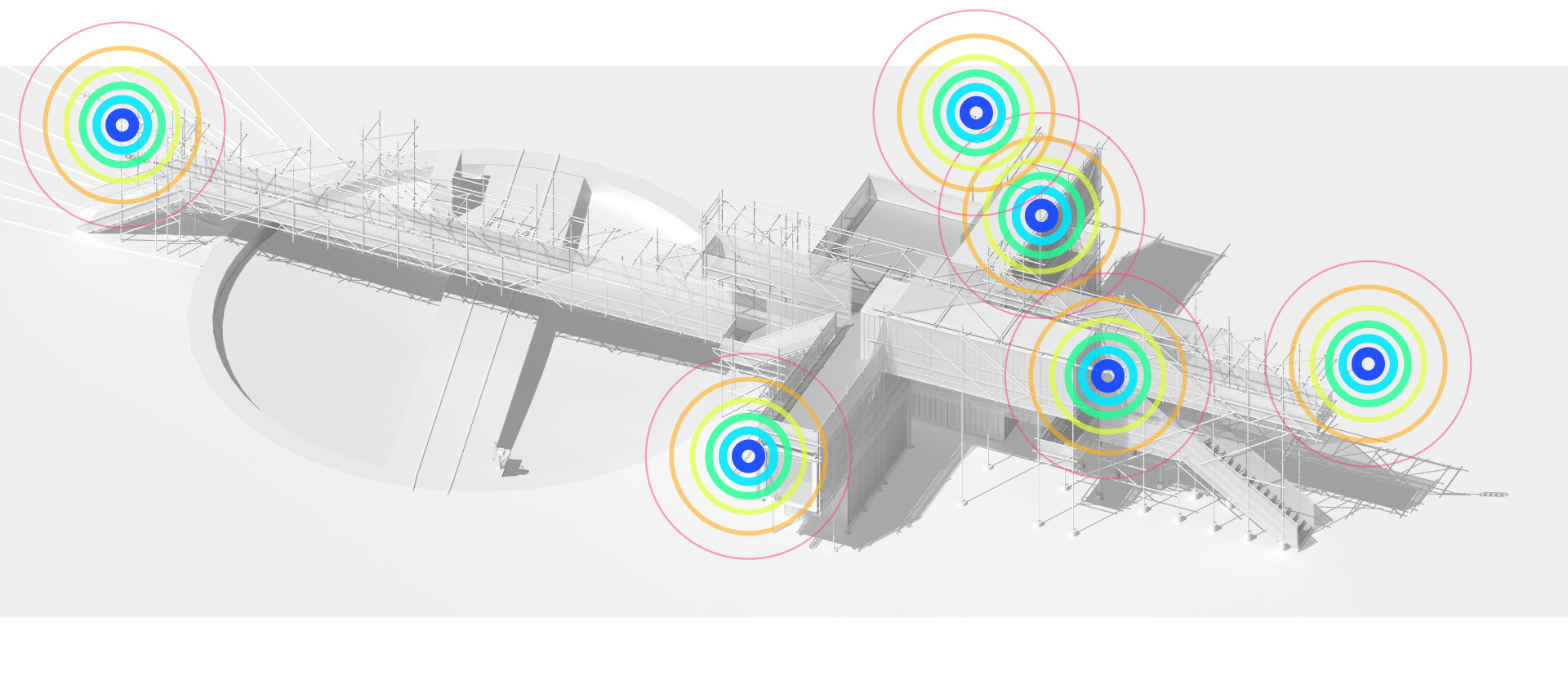
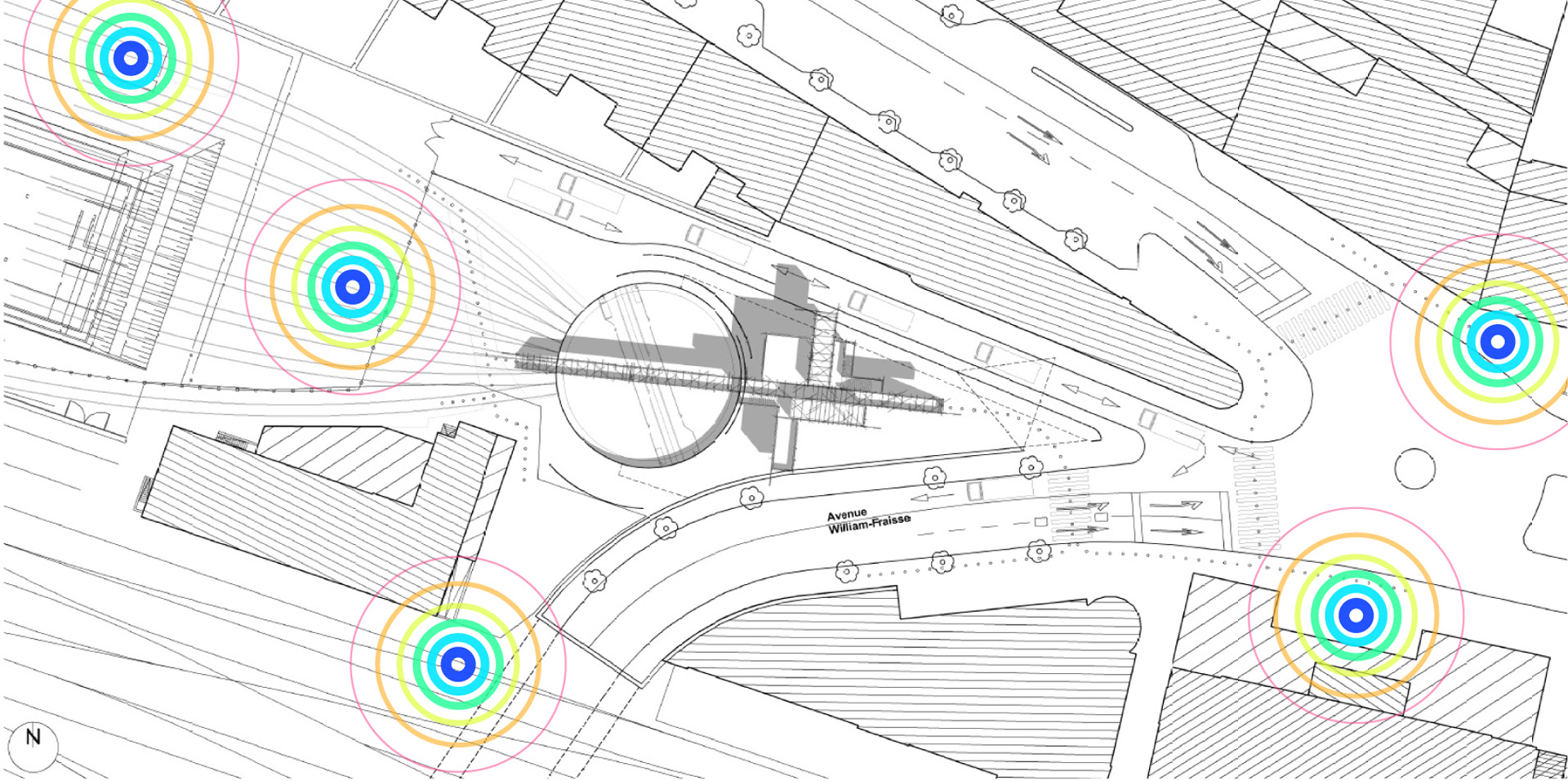 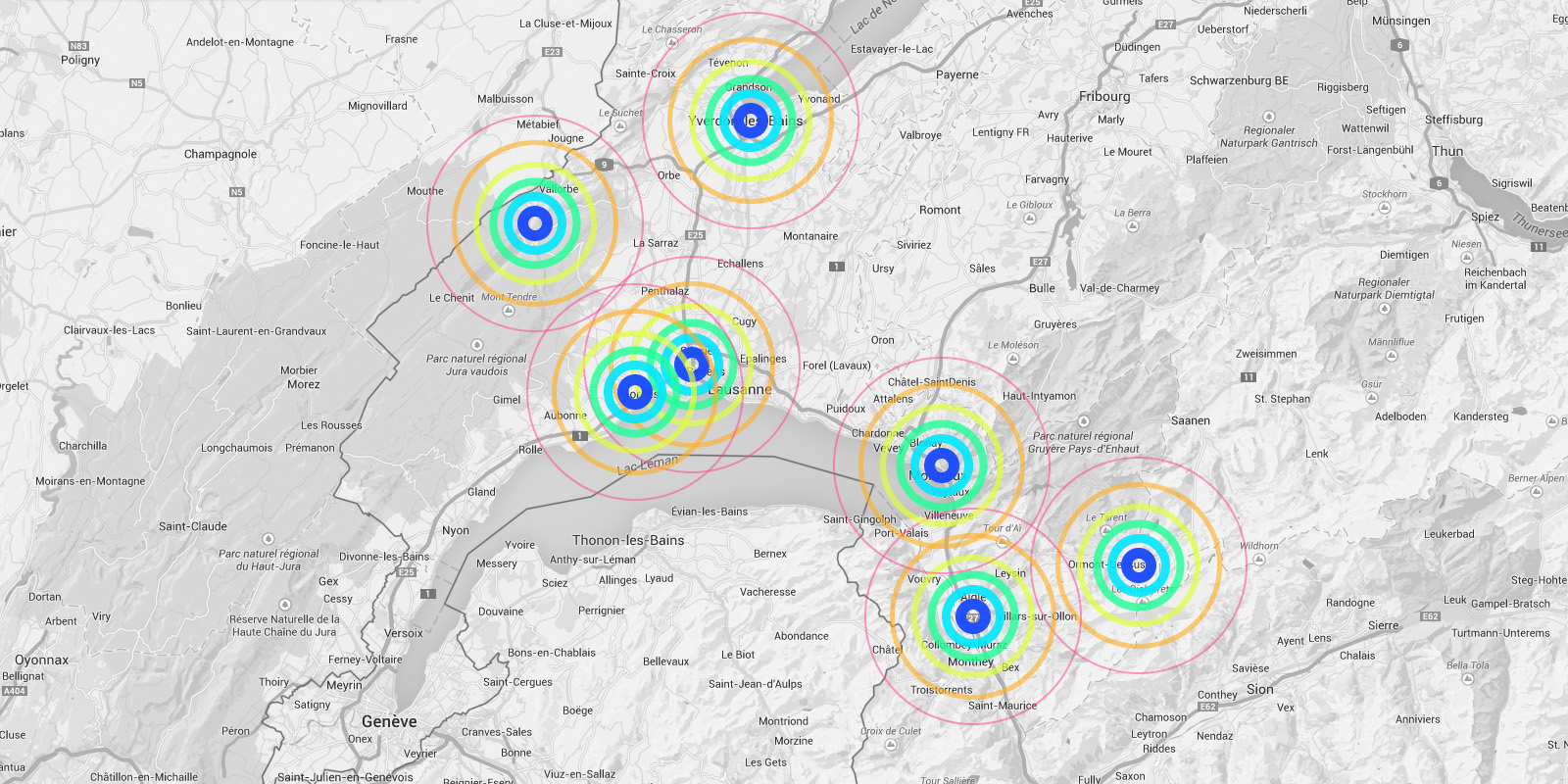

Several areas are linked to monitoring activities (input devices) and/or displays (in red, top -- that concern interests points and views from the platform or elsewhere --). These areas consist in localized devices on the platform itself (5 locations), satellite ones directly implented in the three construction sites or even in distant cities of the larger political area --these are rather output devices-- concerned by the new constructions (three museums, two new large public squares, a new railway station and a new metro). Inspired by the prior similar installation in a public park during a festival -- Heterochrony (bottom image) --, these raw data can be of different nature: visual, audio, integers from sensors (%, °C, ppm, db, lm, mb, etc.), ...

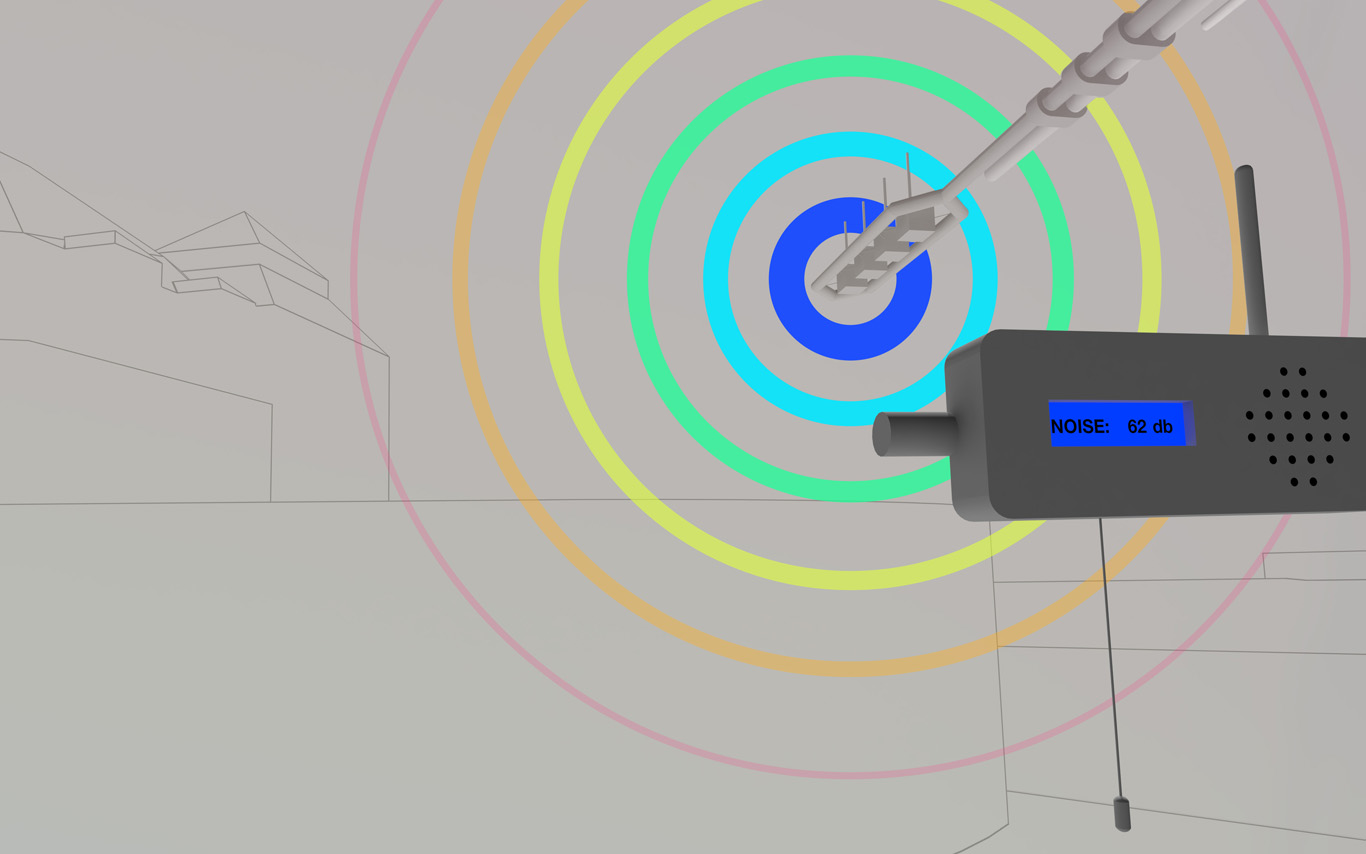

Input and output devices remain low-cost and simple in their expression: several input devices / sensors are placed outside of the pavilion in the structural elements and point toward areas of interest (construction sites or more specific parts of them). Directly in relation with these sensors and the sightseeing spots but on the inside are placed output devices with their recognizable blue screens. These are mainly voice interfaces: voice outputs driven by one bot according to architectural "scores" or algorithmic rules (middle image). Once the rules designed, the "architectural system" runs on its own. That's why we've also named the system based on automated bots "Ar.I." It could stand for "Architectural Intelligence", as it is entirely part of the architectural project.
The coding of the "Ar.I." and use of data has the potential to easily become something more experimental, transformative and performative along the life of PPoFT.
Observers (users) and their natural "curiosity" play a central role: preliminary observations and monitorings are indeed the ones produced in an analog way by them (eyes and ears), in each of the 5 interesting points and through their wanderings. Extending this natural interest is a simple cord in front of each "output device" that they can pull on, which will then trigger a set of new measures by all the related sensors on the outside. This set new data enter the database and become readable by the "Ar.I."
The whole part of the project regarding interaction and data treatments has been subject to a dedicated short study (a document about this study can be accessed here --in French only--). The main design implications of it are that the "Ar.I." takes part in the process of "filtering" which happens between the "outside" and the "inside", by taking part to the creation of a variable but specific "inside atmosphere" ("artificial artificial", as the outside is artificial as well since the anthropocene, isn't it ?) By doing so, the "Ar.I." bot fully takes its own part to the architecture main program: triggering the perception of an inside, proposing patterns of occupations.
"Ar.I." computes spatial elements and mixes times. It can organize configurations for the pavilion (data, displays, recorded sounds, lightings, clocks). It can set it to a past, a present, but also a future estimated disposition. "Ar.I." is mainly a set of open rules and a vocal interface, at the exception of the common access and conference space equipped with visual displays as well. "Ar.I." simply spells data at some times while at other, more intriguingly, it starts give "spatial advices" about the environment data configuration.
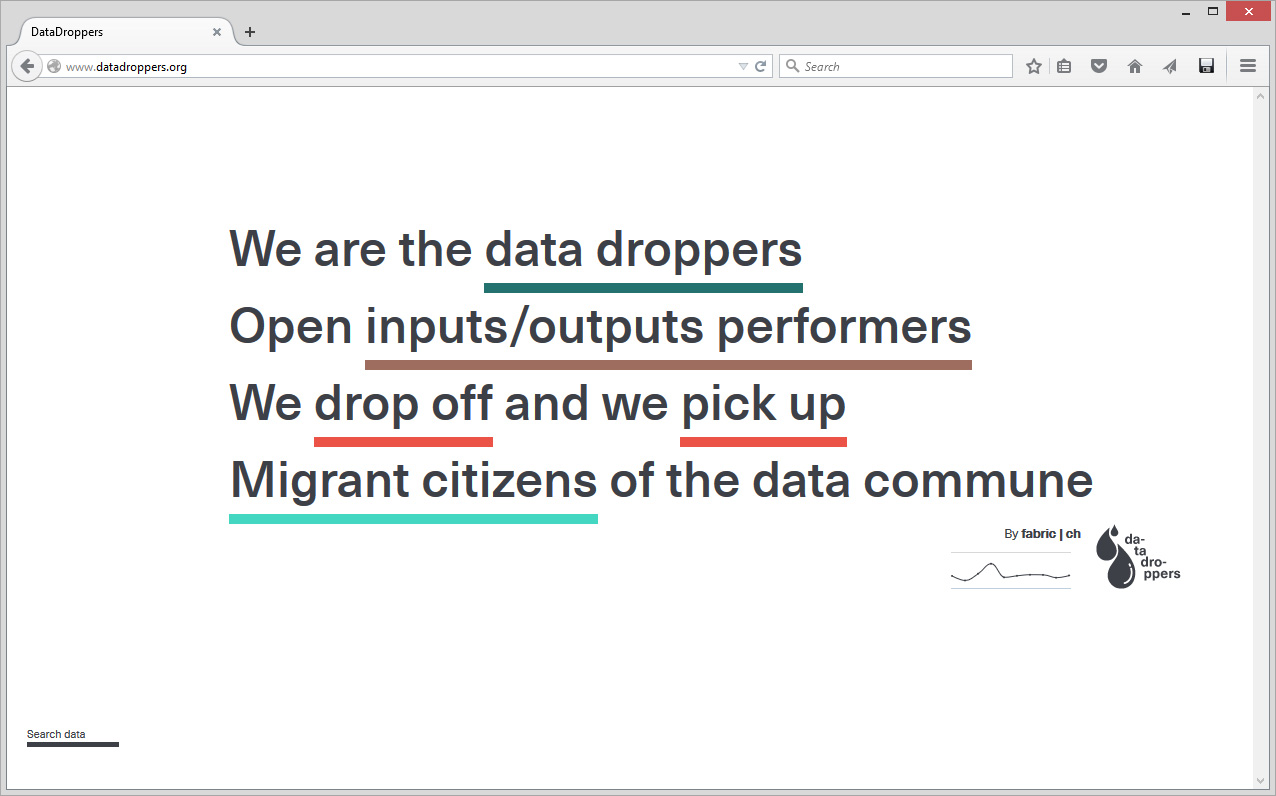


In parallel to Public Platform of Future Past and in the frame of various research or experimental projects, scientists and designers at fabric | ch have been working to set up their own platform for declaring and retrieving data (more about this project, Datadroppers, here). A platform, simple but that is adequate to our needs, on which we can develop as desired and where we know what is happening to the data. To further guarantee the nature of the project, a "data commune" was created out of it and we plan to further release the code on Github.
In tis context, we are turning as well our own office into a test tube for various monitoring systems, so that we can assess the reliability and handling of different systems. It is then the occasion to further "hack" some basic domestic equipments and turn them into sensors, try new functions as well, with the help of our 3d printer in tis case (middle image). Again, this experimental activity is turned into a side project, Studio Station (ongoing, with Pierre-Xavier Puissant), while keeping the general background goal of "concept-proofing" the different elements of the main project.


A common room (conference room) in the pavilion hosts and displays the various data. 5 small screen devices, 5 voice interfaces controlled for the 5 areas of interests and a semi-transparent data screen. Inspired again by what was experimented and realized back in 2012 during Heterochrony (top image).
----- ----- -----
PPoFP, several images. Day, night configurations & few comments
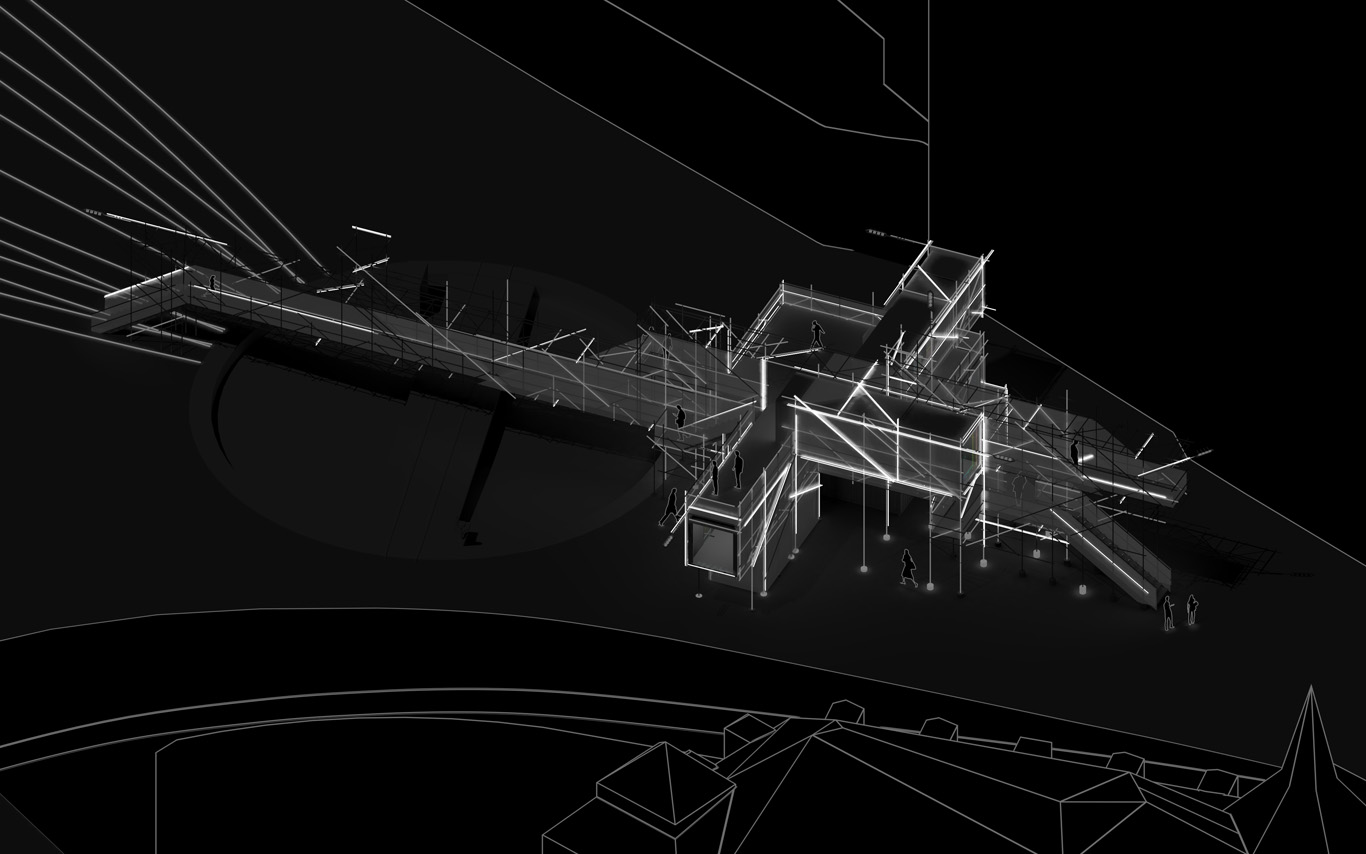
Public Platform of Future-Past, axonometric views day/night.
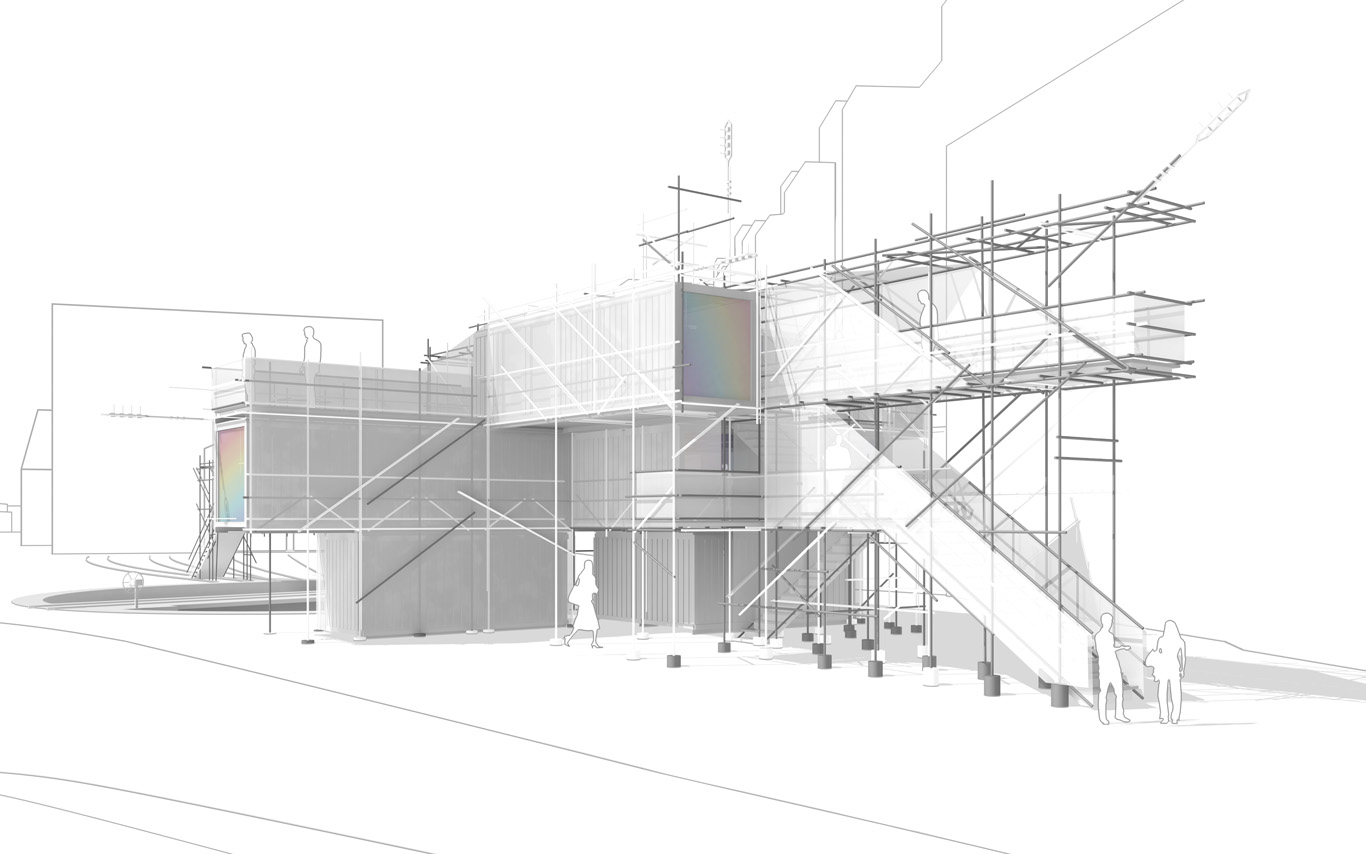
.jpg)

An elevated walkway that overlook the almost archeological site (past-present-future). The circulations and views define and articulate the architecture and the five main "points of interests". These mains points concentrates spatial events, infrastructures and monitoring technologies. Layer by layer, the suroundings are getting filtrated by various means and become enclosed spaces.
.jpg)
.jpg)
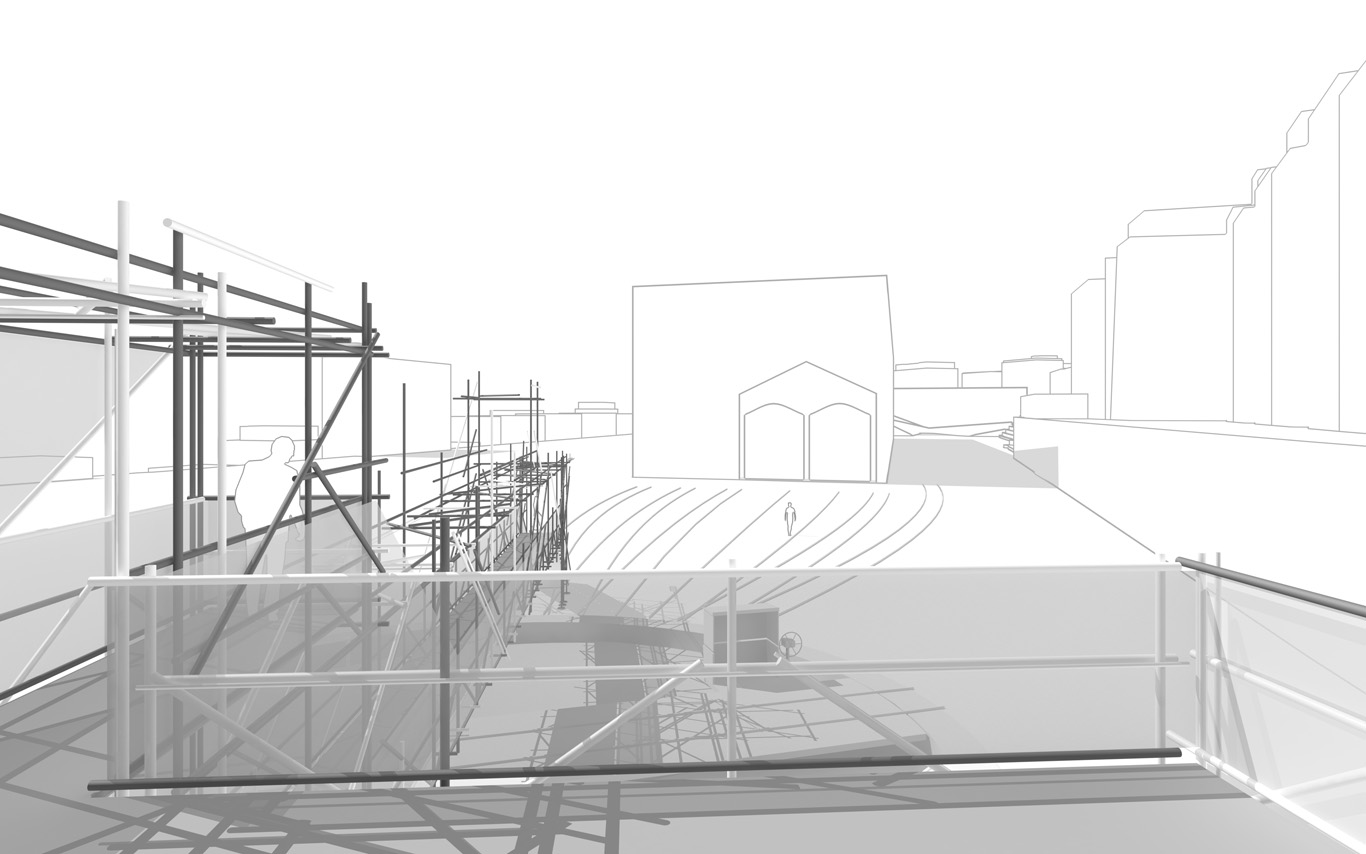
Walks, views over transforming sites, ...
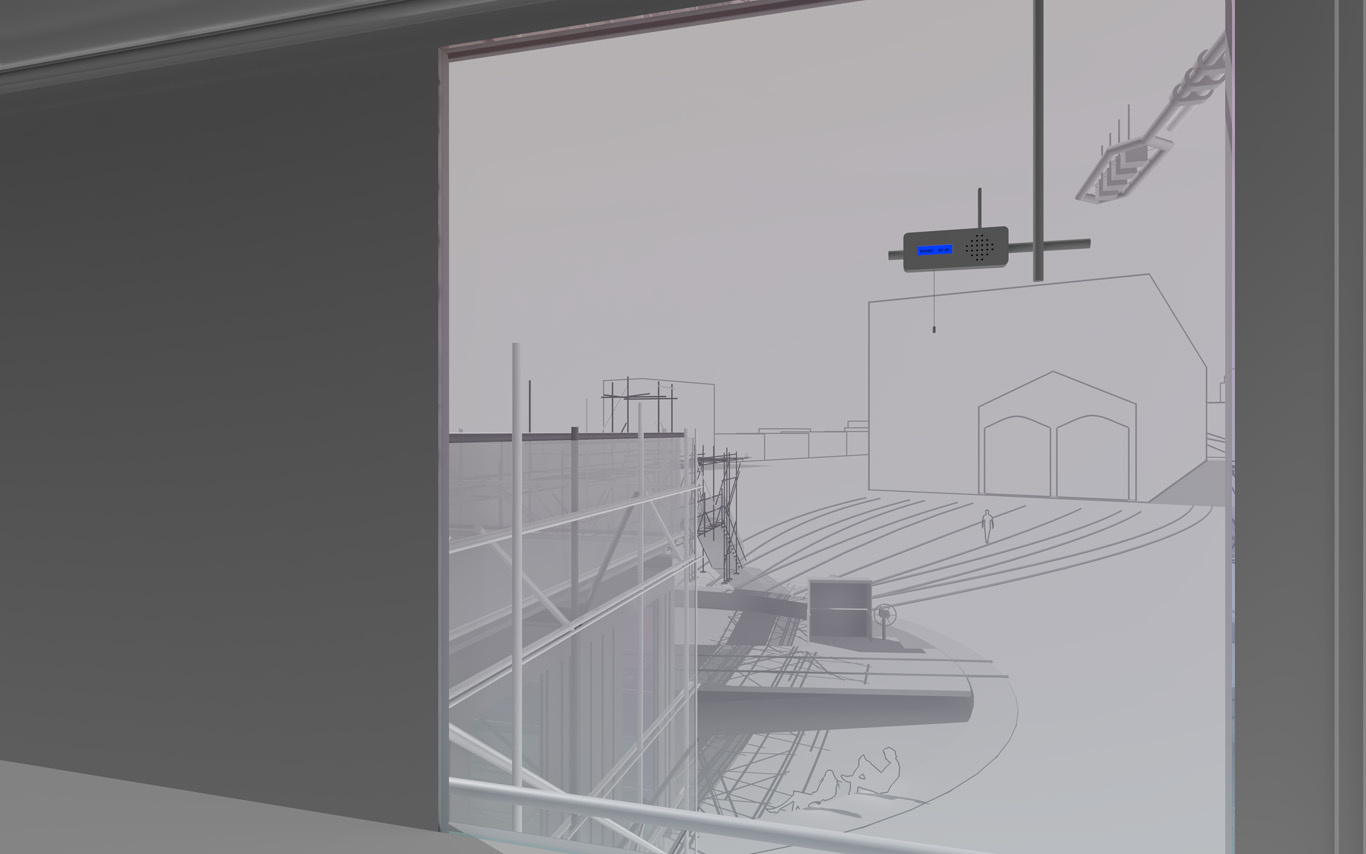

Data treatment, bots, voice and minimal visual outputs.

.jpg)

.jpg)
Night views, circulations, points of view.


Night views, ground.
.jpg)
Random yet controllable lights at night. Underlined areas of interests, points of "spatial densities".
Project: fabric | ch
Team: Patrick Keller, Christophe Guignard, Christian Babski, Sinan Mansuroglu, Yves Staub, Nicolas Besson.
Friday, May 27. 2016
Note: "(...) For example, technologists might be held responsible if they use poor quality data to train AI systems, or fossilize prejudices based on race, age, or gender into the algorithms they design."
Mind your data and the ones you'll use to "fossilize", so to say (and as long as you'll already know what's in your data)... It is then no more about "if" you're collecting data, but "which" data you'll use to feed your AIs, and "how". Now that we clearly see that large corporations plan to use more and more of these kind of techs to also drive "domestic" applications (and by extension as we already know "personal" applications of all sorts), it will be important to understand the stakes behind them as it will become part of our social and design context.
An important problem that I can see for designers and architects is that if you don't agree with the principles --commercial, social, ethical and almost conceptual-- implied by the technologies (i.e. any "homekit" like platforms controlled by bots), you won't find many if any counter propositions/techs to work with (all large diffusion products will support iOS, Android and the likes). It is almost a dictatorship of products hidden behind a "participate" paradigma. Either you'll be in and accept the conditions (you might use an API provided with the service --FB, Twitter, IFTTT, Apple, Google, Wolfram, Siemens, MS, etc.--, but then feed the central company nonetheless), or out... or possibly develop you own solution(s) that will probably be a pain in the ass to use for your client because it/they will clearly be side products hard to maintain, update, etc.
"Some" open source projects driven by "some" communities could be/become (should be) alternative solutions of course, but for now these are good for prototyping and teaching, not for consistent "domestic" applications... And when they'll possibly do so, they might likely be bought. So we'll have "difficulties" as (interaction) designers, so to say: you'll work for your client(s) ... and the corp. that provides the services you'll use!
Via MIT Technology Review
----
The Obama administration is vowing not to get left behind in the rush to artificial intelligence, but determining how to regulate it isn’t easy.
By Mark Harris
Should the government regulate artificial intelligence? That was the central question of the first White House workshop on the legal and governance implications of AI, held in Seattle on Tuesday.
“We are observing issues around AI and machine learning popping up all over the government,” said Ed Felten, White House deputy chief technology officer. “We are nowhere near the point of broadly regulating AI … but the challenge is how to ensure AI remains safe, controllable, and predictable as it gets smarter.”
One of the key aims of the workshop, said one of its organizers, University of Washington law professor Ryan Calo, was to help the public understand where the technology is now and where it’s headed. “The idea is not for the government to step in and regulate AI but rather to use its many other levers, like coördination among the agencies and procurement power,” he said. Attendees included technology entrepreneurs, academics, and members of the public.
In a keynote speech, Oren Etzioni, CEO of the Allen Institute for Artificial Intelligence, noted that we are still in the Dark Ages of machine learning, with AI systems that generally only work well on well-structured problems like board games and highway driving. He championed a collaborative approach where AI can help humans to become safer and more efficient. “Hospital errors are the third-leading cause of death in the U.S.,” he said. “AI can help here. Every year, people are dying because we’re not using AI properly in hospitals.”

Oren Etzioni, CEO of the Allen Institute for Artificial Intelligence, left, speaks with attendees at the White House workshop on artificial intelligence.
Nevertheless, Etzioni considers it far too early to talk about regulating AI: “Deep learning is still 99 percent human work and human ingenuity. ‘My robot did it’ is not an excuse. We have to take responsibility for what our robots, AI, and algorithms do.”
A panel on “artificial wisdom” focused on when these human-AI interactions go wrong, such as the case of an algorithm designed to predict future criminal offenders that appears to be racially biased. “The problem is not about the AI agents themselves, it’s about humans using technological tools to oppress other humans in finance, criminal justice, and education,” said Jack Balkin of Yale Law School.
Several academics supported the idea of an “information fiduciary”: giving people who collect big data and use AI the legal duties of good faith and trustworthiness. For example, technologists might be held responsible if they use poor quality data to train AI systems, or fossilize prejudices based on race, age, or gender into the algorithms they design.
As government institutions increasingly rely on AI systems for decision making, those institutions will need personnel who understand the limitations and biases inherent in data and AI technology, noted Kate Crawford, a social scientist at Microsoft Research. She suggested that students be taught ethics alongside programming skills.
Bryant Walker Smith from the University of South Carolina proposed regulatory flexibility for rapidly evolving technologies, such as driverless cars. “Individual companies should make a public case for the safety of their autonomous vehicles,” he said. “They should establish measures and then monitor them over the lifetime of their systems. We need a diversity of approaches to inform public debate.”
This was the first of four workshops planned for the coming months. Two will address AI for social good and issues around safety and control, while the last will dig deeper into the technology’s social and economic implications. Felten also announced that the White House would shortly issue a request for information to give the general public an opportunity to weigh in on the future of AI.
The elephant in the room, of course, was November’s presidential election. In a blog post earlier this month, Felten unveiled a new National Science and Technology Council Subcommittee on Machine Learning and Artificial Intelligence, focused on using AI to improve government services “between now and the end of the Administration.”
Tuesday, May 24. 2016
Note: even people developing automation will be automated, so to say...
Do you want to change this existing (and predictable) future? This would be the right time to come with counter-proposals then...
But I'm quite surprized by the absence of nuanced analysis in the Wired article btw (am I? further than "make the workd a better place" I mean): indeed, this is a scientific achievement, but then what? no stakes? no social issues? It seems to be the way things should go then... (and some people know pretty well how "The Way Things Go", always wrong ;)), to the point that " No, Asimo isn’t quite as advanced—or as frightening—as Skynet." Good to know!
Via Wired
-----
By Cade Metz

Deep neural networks are remaking the Internet. Able to learn very human tasks by analyzing vast amounts of digital data, these artificially intelligent systems are injecting online services with a power that just wasn’t viable in years past. They’re identifying faces in photos and recognizing commands spoken into smartphones and translating conversations from one language to another. They’re even helping Google choose its search results. All this we know. But what’s less discussed is how the giants of the Internet go about building these rather remarkable engines of AI.
Part of it is that companies like Google and Facebook pay top dollar for some really smart people. Only a few hundred souls on Earth have the talent and the training needed to really push the state-of-the-art forward, and paying for these top minds is a lot like paying for an NFL quarterback. That’s a bottleneck in the continued progress of artificial intelligence. And it’s not the only one. Even the top researchers can’t build these services without trial and error on an enormous scale. To build a deep neural network that cracks the next big AI problem, researchers must first try countless options that don’t work, running each one across dozens and potentially hundreds of machines.
“It’s almost like being the coach rather than the player,” says Demis Hassabis, co-founder of DeepMind, the Google outfit behind the history-making AI that beat the world’s best Go player. “You’re coaxing these things, rather than directly telling them what to do.”
That’s why many of these companies are now trying to automate this trial and error—or at least part of it. If you automate some of the heavily lifting, the thinking goes, you can more rapidly push the latest machine learning into the hands of rank-and-file engineers—and you can give the top minds more time to focus on bigger ideas and tougher problems. This, in turn, will accelerate the progress of AI inside the Internet apps and services that you and I use every day.
In other words, for computers to get smarter faster, computers themselves must handle even more of the grunt work. The giants of the Internet are building computing systems that can test countless machine learning algorithms on behalf of their engineers, that can cycle through so many possibilities on their own. Better yet, these companies are building AI algorithms that can help build AI algorithms. No joke. Inside Facebook, engineers have designed what they like to call an “automated machine learning engineer,” an artificially intelligent system that helps create artificially intelligent systems. It’s a long way from perfection. But the goal is to create new AI models using as little human grunt work as possible.
Feeling the Flow
After Facebook’s $104 billion IPO in 2012, Hussein Mehanna and other engineers on the Facebook ads team felt an added pressure to improve the company’s ad targeting, to more precisely match ads to the hundreds of millions of people using its social network. This meant building deep neural networks and other machine learning algorithms that could make better use of the vast amounts of data Facebook collects on the characteristics and behavior of those hundreds of millions of people.
According to Mehanna, Facebook engineers had no problem generating ideas for new AI, but testing these ideas was another matter. So he and his team built a tool called Flow. “We wanted to build a machine-learning assembly line that all engineers at Facebook could use,” Mehanna says. Flow is designed to help engineers build, test, and execute machine learning algorithms on a massive scale, and this includes practically any form of machine learning—a broad technology that covers all services capable of learning tasks largely on their own.
Basically, engineers could readily test an endless stream of ideas across the company’s sprawling network of computer data centers. They could run all sorts of algorithmic possibilities—involving not just deep learning but other forms of AI, including logistic regression to boosted decision trees—and the results could feed still more ideas. “The more ideas you try, the better,” Mehanna says. “The more data you try, the better.” It also meant that engineers could readily reuse algorithms that others had built, tweaking these algorithms and applying them to other tasks.
Soon, Mehanna and his team expanded Flow for use across the entire company. Inside other teams, it could help generate algorithms that could choose the links for your Faceboook News Feed, recognize faces in photos posted to the social network, or generate audio captions for photos so that the blind can understand what’s in them. It could even help the company determine what parts of the world still need access to the Internet.
With Flow, Mehanna says, Facebook trains and tests about 300,000 machine learning models each month. Whereas it once rolled a new AI model onto its social network every 60 days or so, it can now release several new models each week.
The Next Frontier
The idea is far bigger than Facebook. It’s common practice across the world of deep learning. Last year, Twitter acquired a startup, WhetLab, that specializes in this kind of thing, and recently, Microsoft described how its researchers use a system to test a sea of possible AI models. Microsoft researcher Jian Sun calls it “human-assisted search.”
Mehanna and Facebook want to accelerate this. The company plans to eventually open source Flow, sharing it with the world at large, and according to Mehanna, outfits like LinkedIn, Uber, and Twitter are already interested in using it. Mehanna and team have also built a tool called AutoML that can remove even more of the burden from human engineers. Running atop Flow, AutoML can automatically “clean” the data needed to train neural networks and other machine learning algorithms—prepare it for testing without any human intervention—and Mehanna envisions a version that could even gather the data on its own. But more intriguingly, AutoML uses artificial intelligence to help build artificial intelligence.
As Mehana says, Facebook trains and tests about 300,000 machine learning models each month. AutoML can then use the results of these tests to train another machine learning model that can optimize the training of machine learning models. Yes, that can be a hard thing to wrap your head around. Mehanna compares it to Inception. But it works. The system can automatically chooses algorithms and parameters that are likely to work. “It can almost predict the result before the training,” Mehanna says.
Inside the Facebook ads team, engineers even built that automated machine learning engineer, and this too has spread to the rest of the company. It’s called Asimo, and according to Facebook, there are cases where it can automatically generate enhanced and improved incarnations of existing models—models that human engineers can then instantly deploy to the net. “It cannot yet invent a new AI algorithm,” Mehanna says. “But who knows, down the road…”
It’s an intriguing idea—indeed, one that has captivated science fiction writers for decades: an intelligent machine that builds itself. No, Asimo isn’t quite as advanced—or as frightening—as Skynet. But it’s a step toward a world where so many others, not just the field’s sharpest minds, will build new AI. Some of those others won’t even be human.
Monday, April 04. 2016
Note: in a time when we'll soon have for the first time a national vote in Switzeralnd about the Revenu de Base Inconditionnel ("Universal Basic Income") --next June, with a low chance of success this time, let's face it--, when people start to speak about the fact that they should get incomes to fuel global corporations with digital data and content of all sorts, when some new technologies could modify the current digital deal, this is a manifesto that is certainly more than interesting to consider. So as its criticism in this paper, as it appears truly complementary.
More generally, thinking the Future in different terms than liberalism is an absolute necessity. Especially in a context where, also as stated, "Automation and unemployment are the future, regardless of any human intervention".
Via Los Angeles Review of Books
-----
By Ian Lowrie

January 8th, 2016
IN THE NEXT FEW DECADES, your job is likely to be automated out of existence. If things keep going at this pace, it will be great news for capitalism. You’ll join the floating global surplus population, used as a threat and cudgel against those “lucky” enough to still be working in one of the few increasingly low-paying roles requiring human input. Existing racial and geographical disparities in standards of living will intensify as high-skill, high-wage, low-control jobs become more rarified and centralized, while the global financial class shrinks and consolidates its power. National borders will continue to be used to control the flow of populations and place migrant workers outside of the law. The environment will continue to be the object of vicious extraction and the dumping ground for the negative externalities of capitalist modes of production.
It doesn’t have to be this way, though. While neoliberal capitalism has been remarkably successful at laying claim to the future, it used to belong to the left — to the party of utopia. Nick Srnicek and Alex Williams’s Inventing the Future argues that the contemporary left must revive its historically central mission of imaginative engagement with futurity. It must refuse the all-too-easy trap of dismissing visions of technological and social progress as neoliberal fantasies. It must seize the contemporary moment of increasing technological sophistication to demand a post-scarcity future where people are no longer obliged to be workers; where production and distribution are democratically delegated to a largely automated infrastructure; where people are free to fish in the afternoon and criticize after dinner. It must combine a utopian imagination with the patient organizational work necessary to wrest the future from the clutches of hegemonic neoliberalism.
Strategies and Tactics
In making such claims, Srnicek and Williams are definitely preaching to the leftist choir, rather than trying to convert the masses. However, this choir is not just the audience for, but also the object of, their most vituperative criticism. Indeed, they spend a great deal of the book arguing that the contemporary left has abandoned strategy, universalism, abstraction, and the hard work of building workable, global alternatives to capitalism. Somewhat condescendingly, they group together the highly variegated field of contemporary leftist tactics and organizational forms under the rubric of “folk politics,” which they argue characterizes a commitment to local, horizontal, and immediate actions. The essentially affective, gestural, and experimental politics of movements such as Occupy, for them, are a retreat from the tradition of serious militant politics, to something like “politics-as-drug-experience.”
Whatever their problems with the psychodynamics of such actions, Srnicek and Williams argue convincingly that localism and small-scale, prefigurative politics are simply inadequate to challenging the ideological dominance of neoliberalism — they are out of step with the actualities of the global capitalist system. While they admire the contemporary left’s commitment to self-interrogation, and its micropolitical dedication to the “complete removal of all forms of oppression,” Srnicek and Williams are ultimately neo-Marxists, committed to the view that “[t]he reality of complex, globalised capitalism is that small interventions consisting of relatively non-scalable actions are highly unlikely to ever be able to reorganise our socioeconomic system.” The antidote to this slow localism, however, is decidedly not fast revolution.
Instead, Inventing the Future insists that the left must learn from the strategies that ushered in the currently ascendant neoliberal hegemony. Inventing the Future doesn’t spend a great deal of time luxuriating in pathos, preferring to learn from their enemies’ successes rather than lament their excesses. Indeed, the most empirically interesting chunk of their book is its careful chronicle of the gradual, stepwise movement of neoliberalism from the “fringe theory” of a small group of radicals to the dominant ideological consensus of contemporary capitalism. They trace the roots of the “neoliberal thought collective” to a diverse range of trends in pre–World War II economic thought, which came together in the establishment of a broad publishing and advocacy network in the 1950s, with the explicit strategic aim of winning the hearts and minds of economists, politicians, and journalists. Ultimately, this strategy paid off in the bloodless neoliberal revolutions during the international crises of Keynesianism that emerged in the 1980s.
What made these putsches successful was not just the neoliberal thought collective’s ability to represent political centrism, rational universalism, and scientific abstraction, but also its commitment to organizational hierarchy, internal secrecy, strategic planning, and the establishment of an infrastructure for ideological diffusion. Indeed, the former is in large part an effect of the latter: by the 1980s, neoliberals had already spent decades engaged in the “long-term redefinition of the possible,” ensuring that the institutional and ideological architecture of neoliberalism was already well in place when the economic crises opened the space for swift, expedient action.
Demands
Srnicek and Williams argue that the left must abandon its naïve-Marxist hopes that, somehow, crisis itself will provide the space for direct action to seize the hegemonic position. Instead, it must learn to play the long game as well. It must concentrate on building institutional frameworks and strategic vision, cultivating its own populist universalism to oppose the elite universalism of neoliberal capital. It must also abandon, in so doing, its fear of organizational closure, hierarchy, and rationality, learning instead to embrace them as critical tactical components of universal politics.
There’s nothing particularly new about Srnicek and Williams’s analysis here, however new the problems they identify with the collapse of the left into particularism and localism may be. For the most part, in their vituperations, they are acting as rather straightforward, if somewhat vernacular, followers of the Italian politician and Marxist theorist Antonio Gramsci. As was Gramsci’s, their political vision is one of slow, organizationally sophisticated, passive revolution against the ideological, political, and economic hegemony of capitalism. The gradual war against neoliberalism they envision involves critique and direct action, but will ultimately be won by the establishment of a post-work counterhegemony.
In putting forward their vision of this organization, they strive to articulate demands that would allow for the integration of a wide range of leftist orientations under one populist framework. Most explicitly, they call for the automation of production and the provision of a basic universal income that would provide each person the opportunity to decide how they want to spend their free time: in short, they are calling for the end of work, and for the ideological architecture that supports it. This demand is both utopian and practical; they more or less convincingly argue that a populist, anti-work, pro-automation platform might allow feminist, antiracist, anticapitalist, environmental, anarchist, and postcolonial struggles to become organized together and reinforce one another. Their demands are universal, but designed to reflect a rational universalism that “integrates difference rather than erasing it.” The universal struggle for the future is a struggle for and around “an empty placeholder that is impossible to fill definitively” or finally: the beginning, not the end, of a conversation.
In demanding full automation of production and a universal basic income, Srnicek and Williams are not being millenarian, not calling for a complete rupture with the present, for a complete dismantling and reconfiguration of contemporary political economy. On the contrary, they argue that “it is imperative […] that [the left’s] vision of a new future be grounded upon actually existing tendencies.” Automation and unemployment are the future, regardless of any human intervention; the momentum may be too great to stop the train, but they argue that we can change tracks, can change the meaning of a future without work. In demanding something like fully automated luxury communism, Srnicek and Williams are ultimately asserting the rights of humanity as a whole to share in the spoils of capitalism.
Criticisms
Inventing the Future emerged to a relatively high level of fanfare from leftist social media. Given the publicity, it is unsurprising that other more “engagé” readers have already advanced trenchant and substantive critiques of the future imagined by Srnicek and Williams. More than a few of these critics have pointed out that, despite their repeated insistence that their post-work future is an ecologically sound one, Srnicek and Williams evince roughly zero self-reflection with respect either to the imbrication of microelectronics with brutally extractive regimes of production, or to their own decidedly antiquated, doctrinaire Marxist understanding of humanity’s relationship towards the nonhuman world. Similarly, the question of what the future might mean in the Anthropocene goes largely unexamined.
More damningly, however, others have pointed out that despite the acknowledged counterintuitiveness of their insistence that we must reclaim European universalism against the proliferation of leftist particularisms, their discussions of postcolonial struggle and critique are incredibly shallow. They are keen to insist that their universalism will embrace rather than flatten difference, that it will be somehow less brutal and oppressive than other forms of European univeralism, but do little of the hard argumentative work necessary to support these claims. While we see the start of an answer in their assertion that the rejection of universal access to discourses of science, progress, and rationality might actually function to cement certain subject-positions’ particularity, this — unfortunately — remains only an assertion. At best, they are being uncharitable to potential allies in refusing to take their arguments seriously; at worst, they are unreflexively replicating the form if not the content of patriarchal, racist, and neocolonial capitalist rationality.
For my part, while I find their aggressive and unapologetic presentation of their universalism somewhat off-putting, their project is somewhat harder to criticize than their book — especially as someone acutely aware of the need for more serious forms of organized thinking about the future if we’re trying to push beyond the horizons offered by the neoliberal consensus.
However, as an anthropologist of the computer and data sciences, it’s hard for me to ignore a curious and rather serious lacuna in their thinking about automaticity, algorithms, and computation. Beyond the automation of work itself, they are keen to argue that with contemporary advances in machine intelligence, the time has come to revisit the planned economy. However, in so doing, they curiously seem to ignore how this form of planning threatens to hive off economic activity from political intervention. Instead of fearing a repeat of the privations that poor planning produced in earlier decades, the left should be more concerned with the forms of control and dispossession successful planning produced. The past decade has seen a wealth of social-theoretical research into contemporary forms of algorithmic rationality and control, which has rather convincingly demonstrated the inescapable partiality of such systems and their tendency to be employed as decidedly undemocratic forms of technocratic management.
Srnicek and Williams, however, seem more or less unaware of, or perhaps uninterested in, such research. At the very least, they are extremely overoptimistic about the democratization and diffusion of expertise that would be required for informed mass control over an economy planned by machine intelligence. I agree with their assertion that “any future left must be as technically fluent as it is politically fluent.” However, their definition of technical fluency is exceptionally narrow, confined to an understanding of the affordances and internal dynamics of technical systems rather than a comprehensive analysis of their ramifications within other social structures and processes. I do not mean to suggest that the democratic application of machine learning and complex systems management is somehow a priori impossible, but rather that Srnicek and Williams do not even seem to see how such systems might pose a challenge to human control over the means of production.
In a very real sense, though, my criticisms should be viewed as a part of the very project proposed in the book. Inventing the Future is unapologetically a manifesto, and a much-overdue clarion call to a seriously disorganized metropolitan left to get its shit together, to start thinking — and arguing — seriously about what is to be done. Manifestos, like demands, need to be pointed enough to inspire, while being vague enough to promote dialogue, argument, dissent, and ultimately action. It’s a hard tightrope to walk, and Srnicek and Williams are not always successful. However, Inventing the Future points towards an altogether more coherent and mature project than does their #ACCELERATE MANIFESTO. It is hard to deny the persuasiveness with which the book puts forward the positive contents of a new and vigorous populism; in demanding full automation and universal basic income from the world system, they also demand the return of utopian thinking and serious organization from the left.
Wednesday, December 23. 2015
Note: ... and while I'm talking about the gallery Circuit in Lausanne, don't forget that there is still Kazuko Miyamoto's exhibition going on for a few more weeks. For the record, Ms Miyamoto was one of the first assistant of Sol Lewitt and was involved on his early wall drawings. Their collaboration lasted for almost three decades. She was also founder of the A.I.R. Gallery in NYC.
Her works are undoubtedly related to the ones of Lewitt as one can feel the rules behind them. Yet they are probably more fragile and aerial. Literally for many of them, as they are made out of yarn strings...
Via Circuit
-----

Kazuko Miyamoto
Une proposition de Matthieu Poirier
Vernissage le vendredi 13 novembre 2015 à 18h00
Ouverture du 14 novembre au 19 décembre 2015
je-ve-sa de 14h-18h et sur rendez-vous
Exposition prolongée jusqu'au 10 janvier 2016
uniquement sur rendez-vous du 19.12 au 10.01.2016
il.: sans titre (String Construction), 1977, vue d’installation, Chrystie Street studio, New York
texte de présentation
liste des pièces
Circuit bénéficie des soutiens de la Ville de Lausanne, de l’État de Vaud, de la Fondation Alfred Richterich, Ernst und Olga Gubler-Hablützel Stiftung, du Pour-cent culturel Migros, de la Banque Cantonale Vaudoise, de la Loterie Romande, de la Fondation Casino Barrière de Montreux
et de Profiducia Conseils SA
Remerciements : Christian Siekmeier
|


