As we continue to lack a decent search engine on this blog and as we don't use a "tag cloud" ... This post could help navigate through the updated content on | rblg (as of 09.2023), via all its tags!
FIND BELOW ALL THE TAGS THAT CAN BE USED TO NAVIGATE IN THE CONTENTS OF | RBLG BLOG:
(to be seen just below if you're navigating on the blog's html pages or here for rss readers)
--
Note that we had to hit the "pause" button on our reblogging activities a while ago (mainly because we ran out of time, but also because we received complaints from a major image stock company about some images that were displayed on | rblg, an activity that we felt was still "fair use" - we've never made any money or advertised on this site).
Nevertheless, we continue to publish from time to time information on the activities of fabric | ch, or content directly related to its work (documentation).
The show constitutes a continuation of Beyond Matter that took place at the ZKMin 2022/23, and is curated by Lívia Nolasco-Rószás and Esteban Guttiérez Jiménez.
The exhibition will be open between the 13th of March and 15th of June 2025.
Atomized (re-)Staging (2022), by fabric | ch. Exhibited during Summing the Ghosts of Modernity at the Museo de Arte Moderno de Medellin (MAMM). March 13 to June 15 2025.
Long introductory note: we all know how data have become important and how we're currently in need of open tools to declare and use static or dynamic data ...
There was once a community data service named Pachube, but it has been sold and its community commodified... There has been initiatives by designers like the one of Berg around the idea of electronic tools, cloud and data services (Berg Cloud), but it was funded by venture capitalists and went bankrupt, unfortunately bringing down the design studio as well. There are some good, simple and interesting online services as well, like Dweet.io, but these are companies that will finally need to make money out of your data (either ways by targeted publicity or by later commodification of the community), as this is one of their main product ...
So we were in need of a tool for our own work at fabric | ch that would remain just what it is supposed to be: a tool... As we are using a lot of dynamic and static data - any kind of data - in our own architectural & interaction works, we needed one. Something simple to use, that we could manage ourselves, that would hopefully not cost much to keep running ...
Following what we already did for many previous projects, for which we designed soft technologies and then publicly released them - and yet never tried to sell them in any manner, we should stress it in this case - (Rhizoreality, I-Weather v. 2001, I-Weather v. 2009 and related apps, Deterritorialized Living), we've designed our own data service: Datadroppers - http://www.datadroppers.org -, first for our own needs, and then just released it online as well. Free to use ...
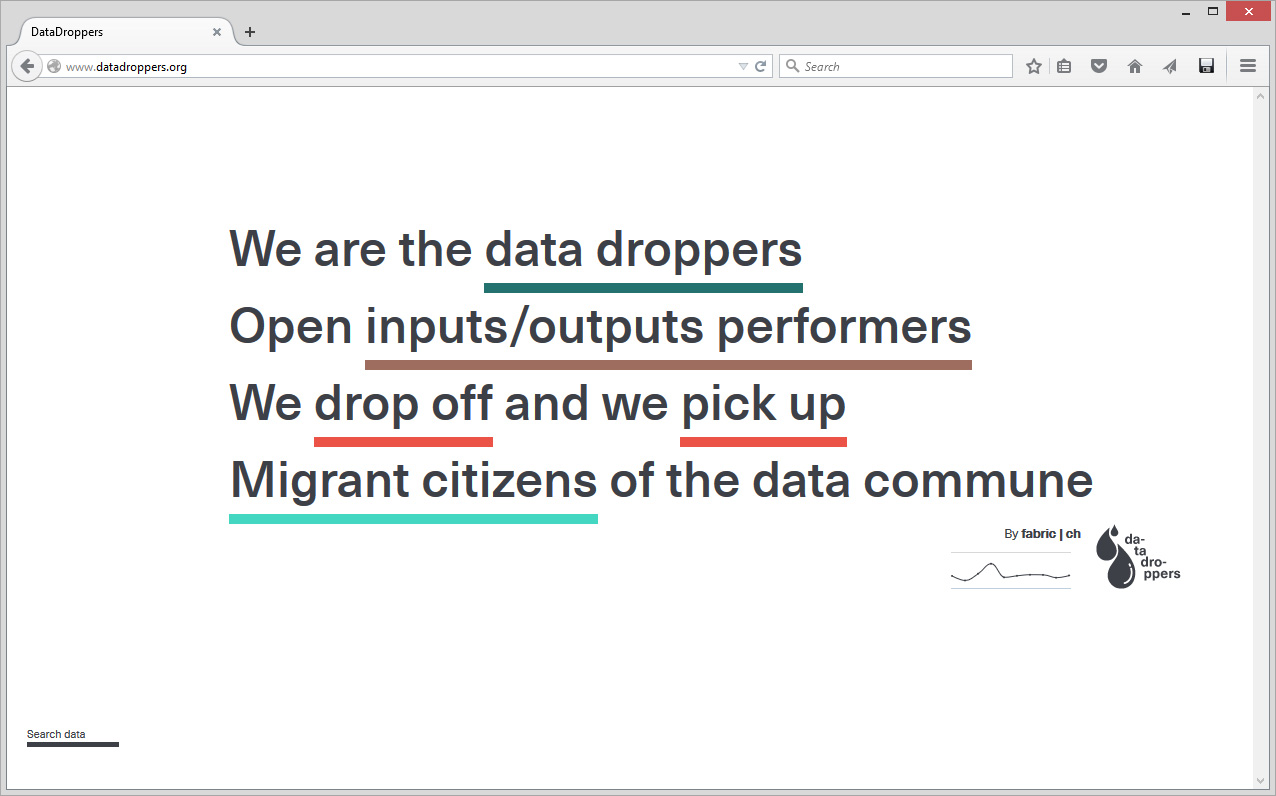
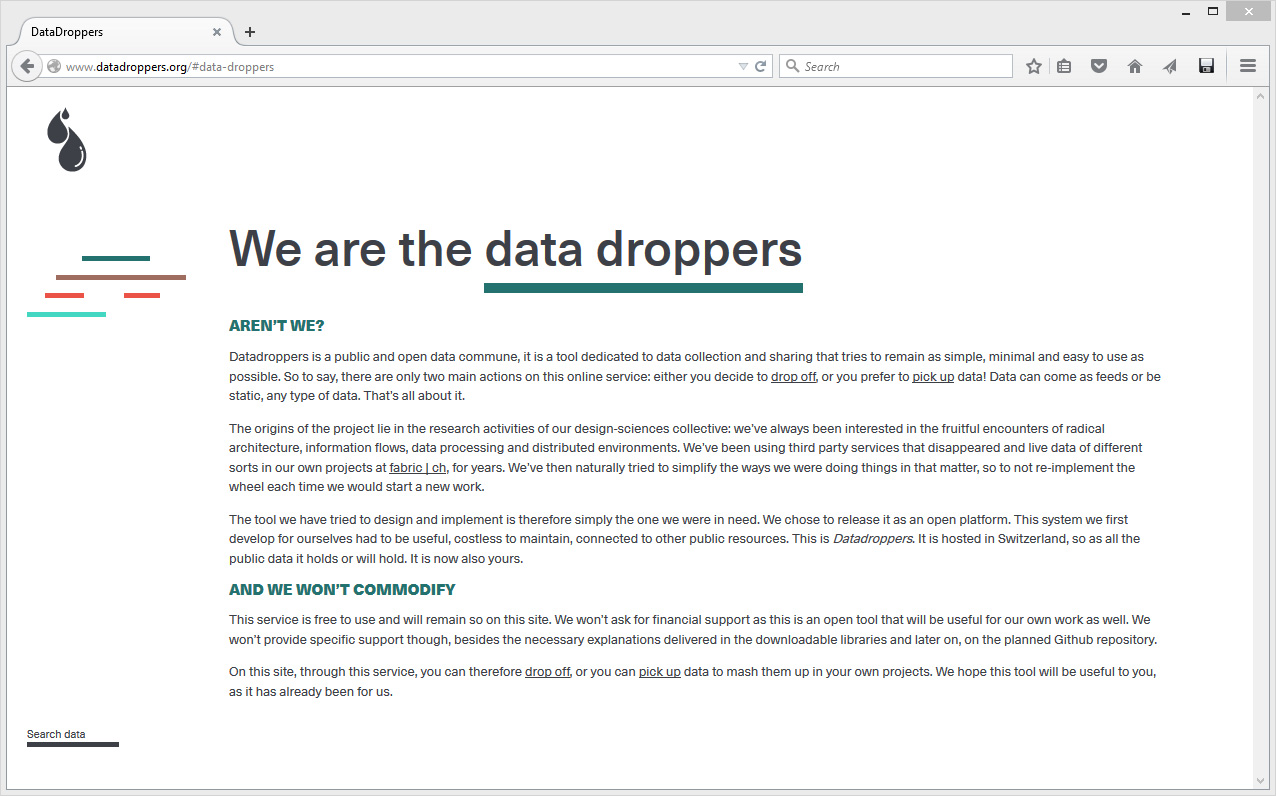
We thought of it as a data commune... trying to keep it as "socially flat" as possible: there are no login, no password, no terms of service, no community, no profiles, no "friends", almost no rules, etc., ... only one statement: "We are the data droppers / Open inputs-outputs performers / We drop off an we pick up / Migrant citizens of the data commune", which also becomes the interface of the service ...
It is a data commune, but not a "community". It is from a "market product" point of view "unsocial", almost uninteresting to later commodify. Yet there is still one single rule (so to keep the service simple and costless to handle): once you publish your data on the site, they'll become public (for everybody, including third party services that won't necessary follow the same open rules) and you won't be able to erase them, as they'll be part of the commune and will possibly be used by other "data communards" as well. They'll be online as long as the service will (i.e. I-Weather is online for 14 years now). So just declare on Datadroppers raw data that you consider for yourself public ...
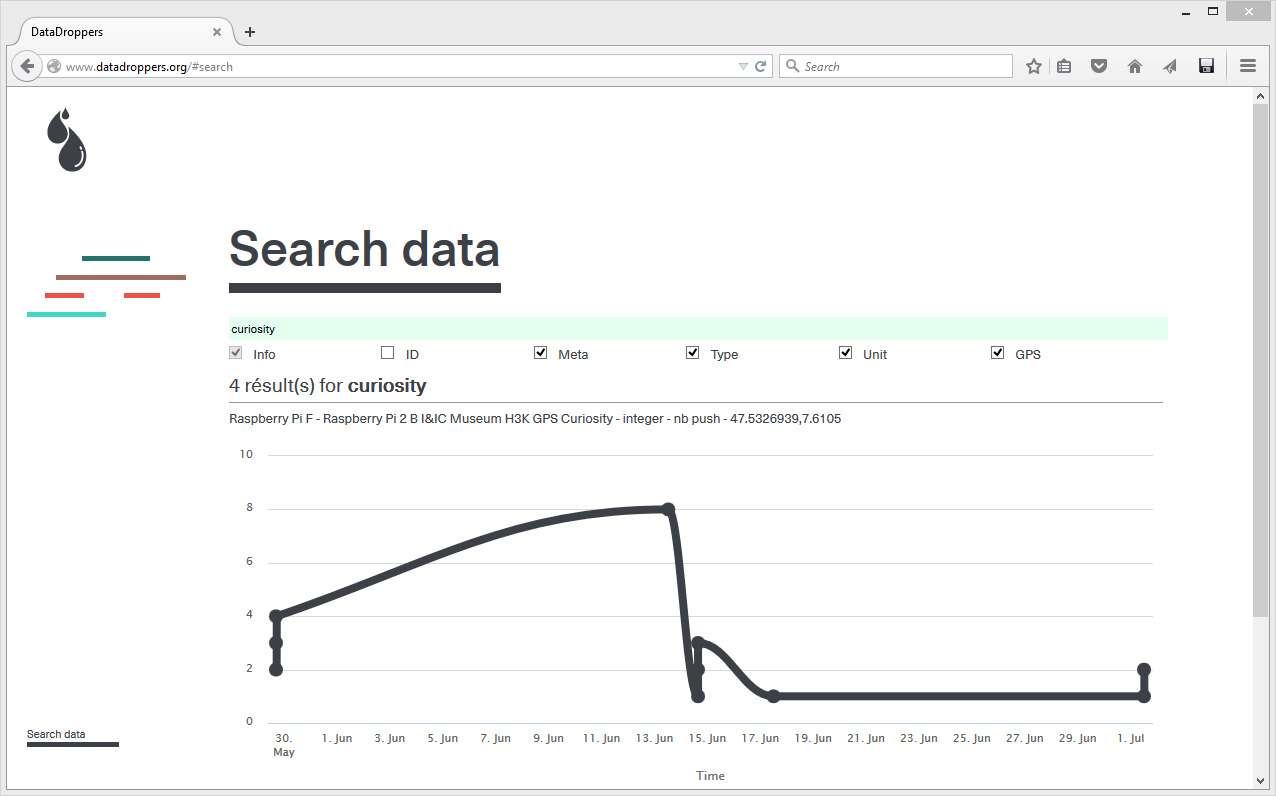
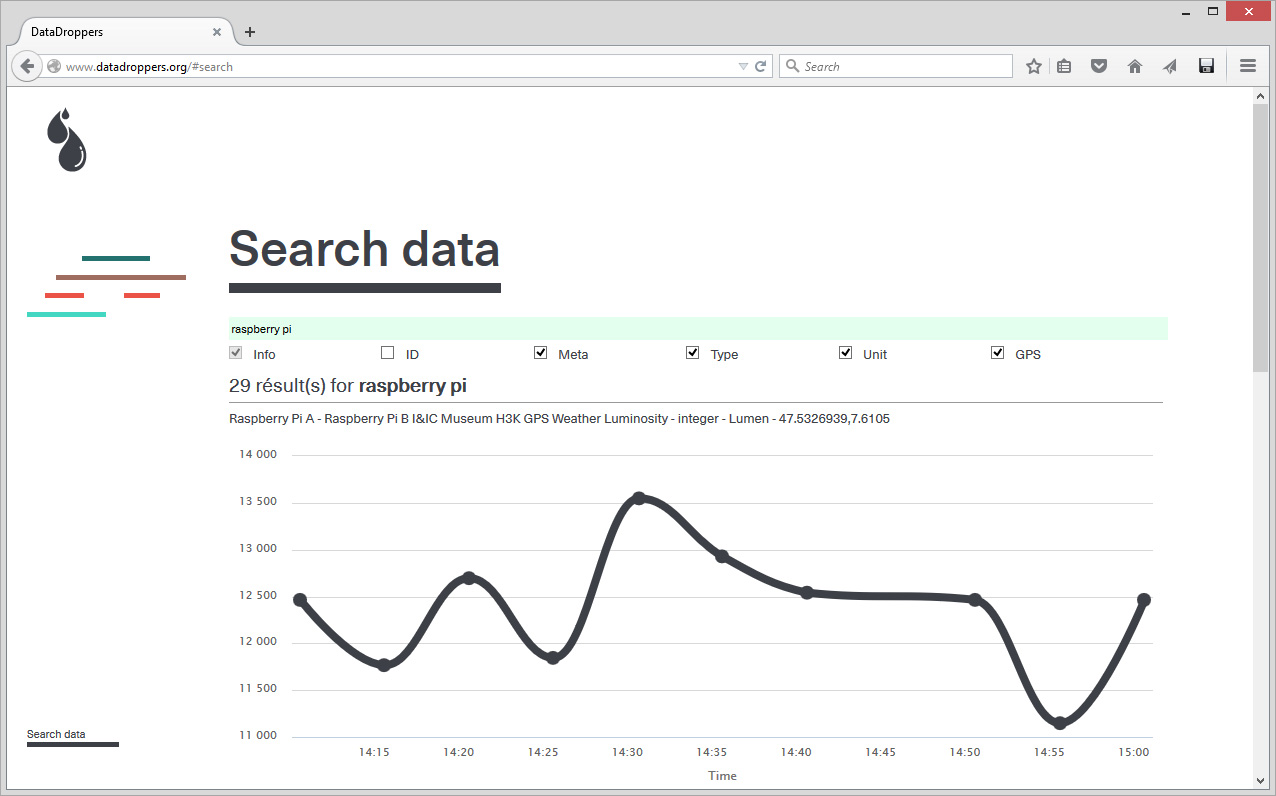
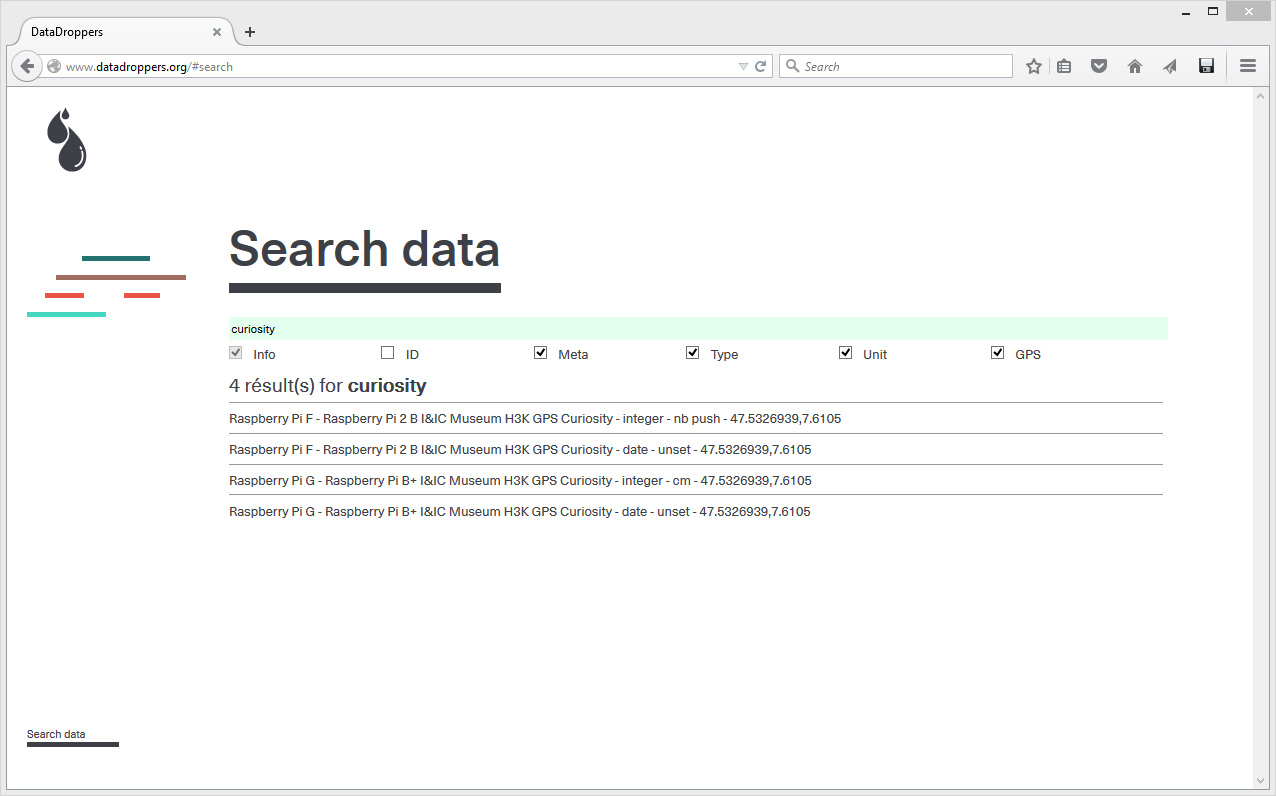
The service, directly developed on the basis of previous projects we did, was first published and used last June, for an exhibition at the Haus der elektronische Künste in Basel (Switzerland). It is hosted in Switzerland / Lausanne under strict laws when it comes to data. There are very few data on the site at this time, only the ones we published from the exhibition (as a test, you can for exemple try a data search using "Raspberry Pi" as a string in the Search data section, which will bring live sensors data as a result). We will now certainly continue to use the service for future works at fabric | ch, maybe will it be also usefull for you? ...
The tool is fully functional at this time, but not entirely completed yet. We expect to release Javascript and Processing libraries later on, so to ease the use of the service when developing applications ...
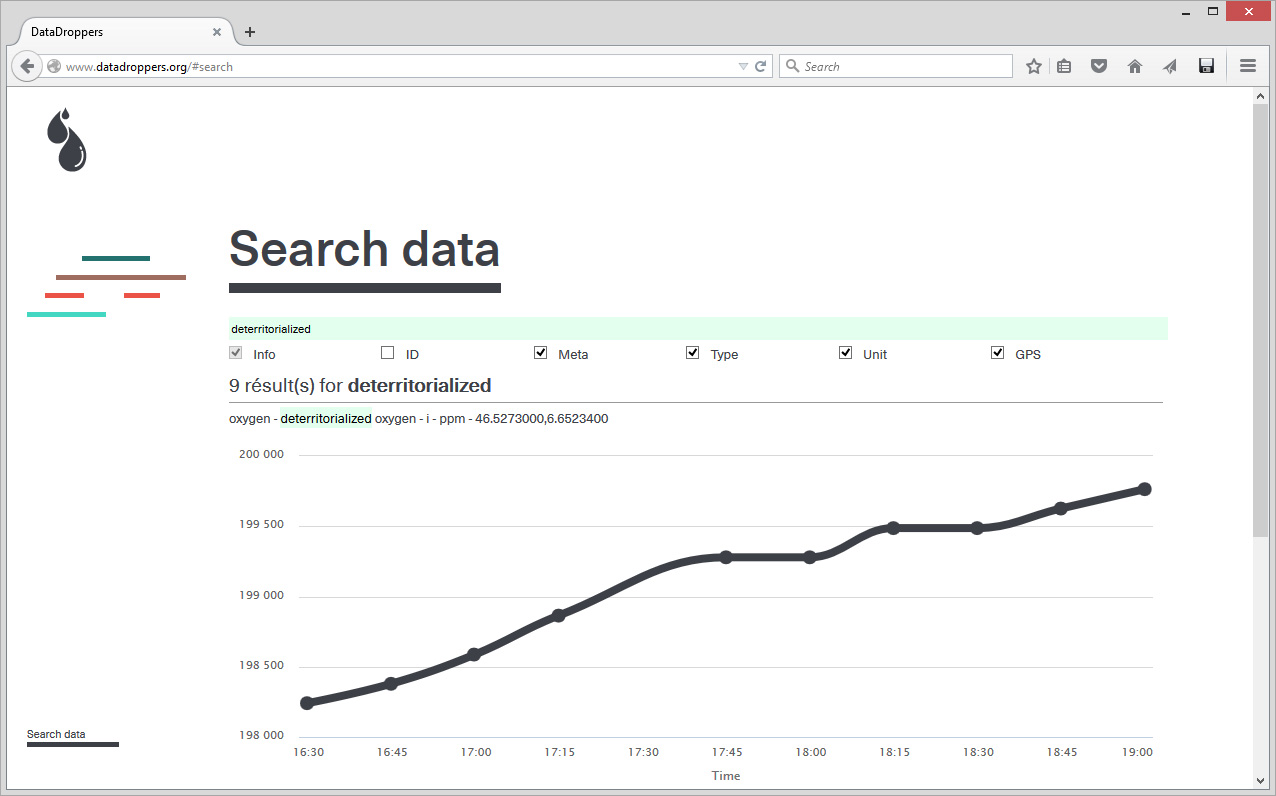
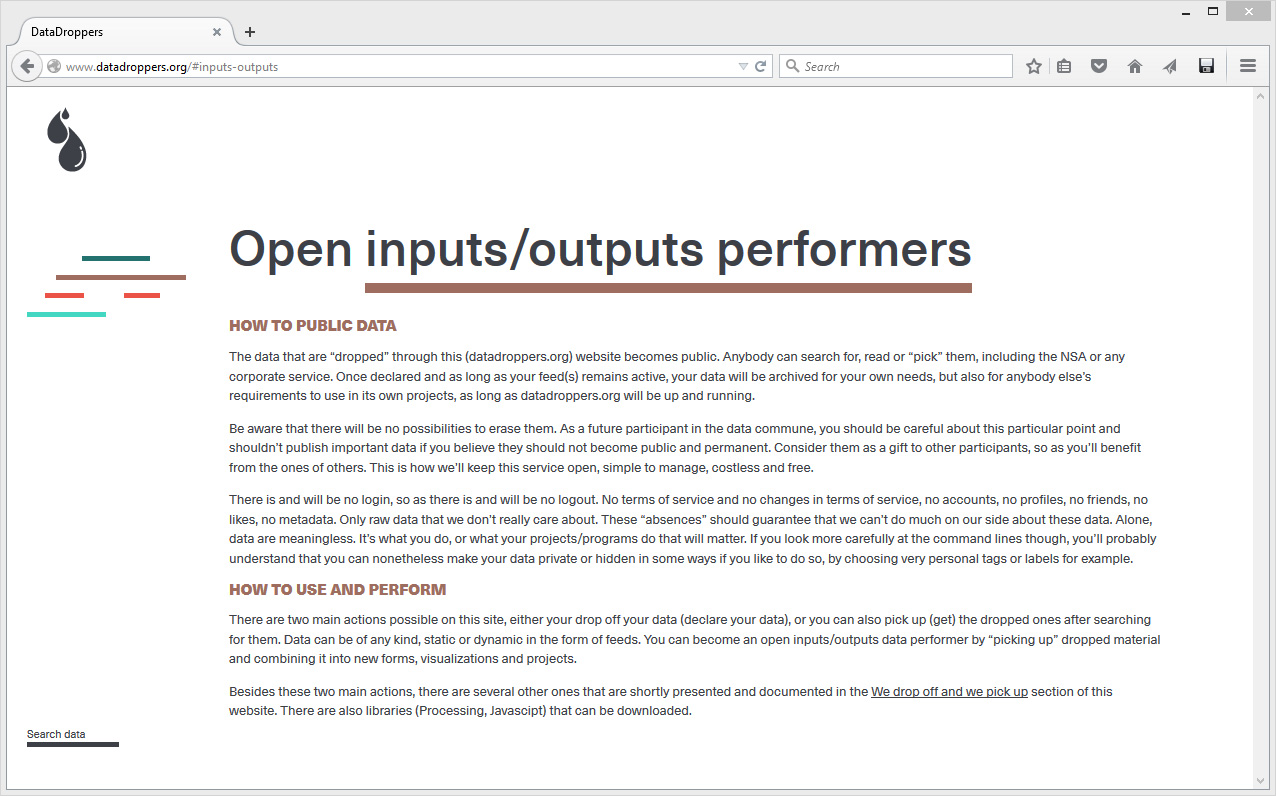
The "communal service" is in fact a statement, the statement becomes the navigation interface. The two main sections of the website are composed by the parts in which you can play with or search for data.
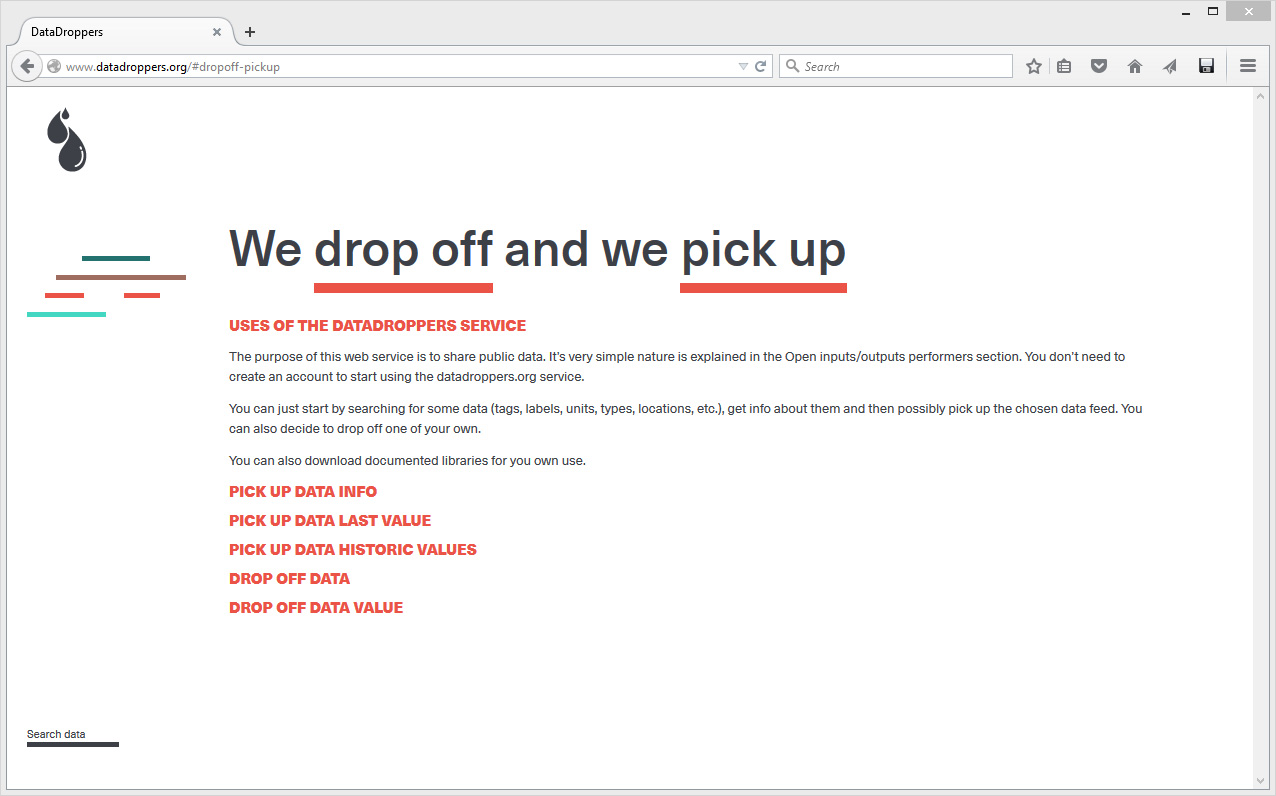
We drop off and we pick up is the area where one can see what can be achieved with data. Obviously, it is either possible to declare (drop off) data and tag them, or retrieve them (pick up) - image above -. You can also Search data following different criteria -below-.
Usual data will certainly be live feeds from sensors, like the one in the top image (i.e. value: lumen). But you could certainly go for more interesting things, either when you'll create data or when you'll use them. The two images above are about "curiosity" data. They were captured within an exhibition (see below) and are already partially interpreted data (i.e. you can leave a connected button with no explanation in the exhibition space, if people press it, well... they are curious). As another exemple, we also recorded data about "transgression" in the same exhibition: a small digital screen says "don't touch" and blinks in red, while an attached sensor obviously connected to the screen can indeed be touched. Childish transgression and slightly meaningless I must admit... It was just a test.
But you could also declare other type of data, any type, while using complementary tools. You could for exemple declare each new image or file within an open cloud service and start cascading things. Or you could start thinking about data as "built" artifacts... like we did in a recent project (see below, Deterritorialized Living) that is delivered in the form of data. Or you could also and of course drop off static data that you would like to store and make accessible for a larger community.
Possibilities seems in fact to be quite large.
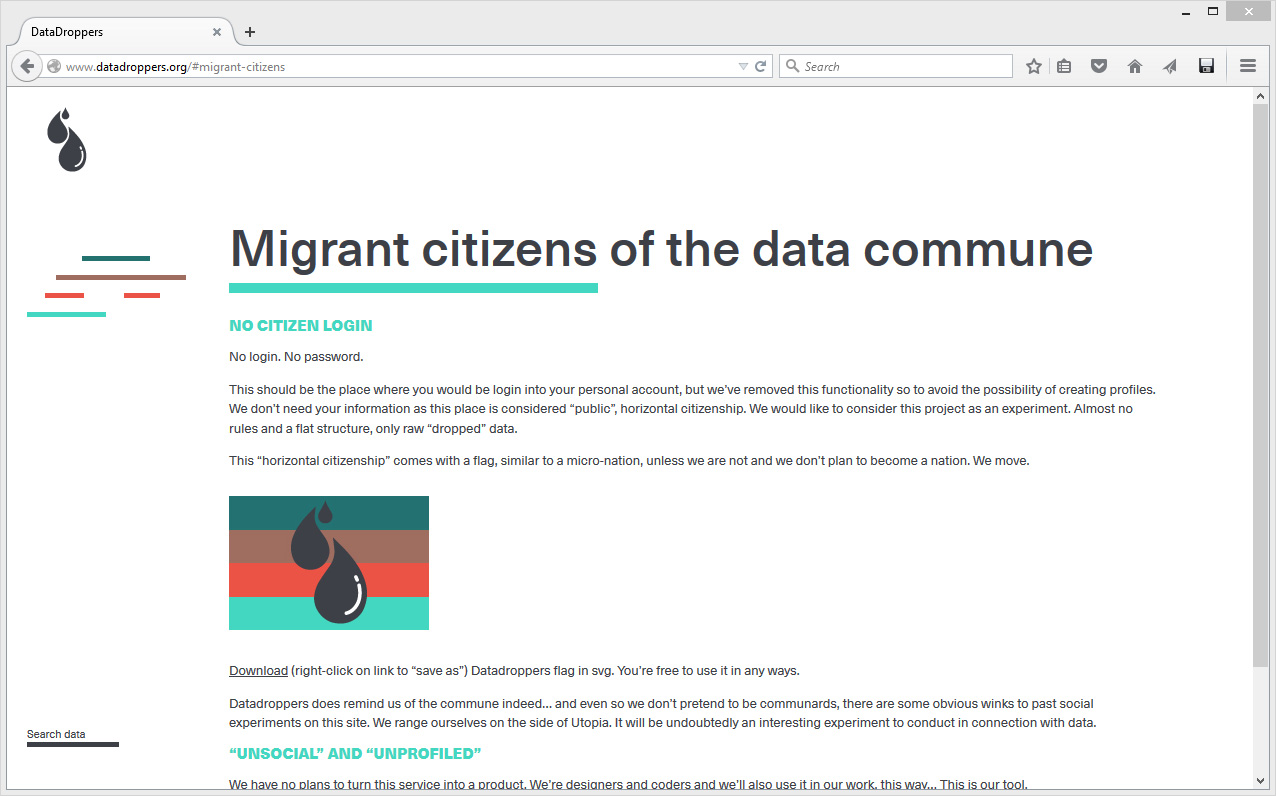
Datadroppers as a commune could even be considered as a micro-society or nation. It comes with a dowloadable "flag", if you desire to manifest your attachment to its philosophy or plant it in your datacenter!
Finally, I must mention the project that initiated Datadroppers, both because we developed the rules of the data sharing service during this latter project (Link > follow "Access to open data feeds"), but also because it is probably one of the most interesting use of Datadroppers so far...
Deterritorialized Living is an artificial, yet livable troposphere that is delivered in the form of data. Just like if we indeed install atmospheric sensors in a real environment, unless the environment doesn't exist in this case (yet), it is the project. The process is therefore reversed within this almost geo-engineered climate that follows different rules than our earth/cosmos driven everyday atmosphere. We have the open data feed to later set it up. fabric | ch or another designer as the feed is open. We plan to use this feed and materialized it through different installations, like we already started to do.
So, for now, this fictive data flow of a designed atmosphere is also delivered as a feed (again: Search data > Deterritorialized), among other ones (some "real", some not), within the webservice offered by Datadroppers .
Note: we often complain on this blog about the centralization in progress (through the actions of corporations) within the "networked world", which is therefore less and less "horizontal" or distributed (and then more pyramidal, proprietary, etc.)
Here comes an interesting initiative by BitTorrent, following their previous distributed file storage/"cloud" system (Sync): a new browser, Maelstrom. This is interesting indeed, because instead of the "web image" --indexed web content-- being hosted in proprietary servers (i.e. the ones of Google), so as your browsing history and everything else, it seems that it will distribute this "web image" on as many "personal" devices as possible. Keeping it fully decentralized therefore. Well... let's wait and see, as the way it will really work has not been explained very well so far (we can speculate that the copy of the content will be distributed indeed, but we don't know much about their business model --what about the metadata aggregated by all the user's web searches and usages? this could still be centralized... Yet note even so they state that it will not be).
Undoubtedly, the BitTorrent architecture is an interesting one when it comes to speak about networked content and decentralization. Yet it is now also a big company... with several venture capital partners (including the ones of Facebook, Spotify, Dropbox, Jawbone, etc.). "Techno-capitalism" (as Eric Sadin names it) is unfortunately one of the biggest force of centralization and commodification. So this is a bit puzzling, but let's not be pessimistic and trust their words for now, until we don't?
Back in December, we reported on the alpha for BitTorrent’s Maelstrom, a browser that uses BitTorrent’s P2P technology in order to place some control of the Web back in users’ hands by eliminating the need for centralized servers.
Maelstrom is now in beta, bring it one step closer to official release. BitTorrent says more than 10,000 developers and 3,500 publishers signed up for the alpha, and it’s using their insights to launch a more stable public beta.
Along with the beta comes the first set of developer tools for the browser, helping publishers and programmers to build their websites around Maelstrom’s P2P technology. And they need to – Maelstrom can’t decentralize the Internet if there isn’t any native content for the platform.
It’s only available on Windows at the moment but if you’re interested and on Microsoft’s OS, you can download the beta from BitTorrent now.
Note: while I'm rather against too much security (therefore, not "Imposing security") and probably reticent to the fact that we, as human beings, are "delegating" too far our daily routines and actions to algorithms (which we wrote), this article stresses the importance of code in our everyday life as well as the fact that it goes down to the language which is used to code a program. Interesting to know that some coding languages are more likely to produce mistakes and errors.
Three computer bugs this year exposed passwords, e-mails, financial data, and other kinds of sensitive information connected to potentially billions of people. The flaws cropped up in different places—the software running on Web servers, iPhones, the Windows operating system—but they all had the same root cause: careless mistakes by programmers.
Each of these bugs—the “Heartbleed” bug in a program called OpenSSL, the “goto fail” bug in Apple’s operating systems, and a so-called “zero-day exploit” discovered in Microsoft’s Internet Explorer—was created years ago by programmers writing in C, a language known for its power, its expressiveness, and the ease with which it leads programmers to make all manner of errors. Using C to write critical Internet software is like using a spring-loaded razor to open boxes—it’s really cool until you slice your fingers.
Alas, as dangerous as it is, we won’t eliminate C anytime soon—programs written in C and the related language C++ make up a large portion of the software that powers the Internet. New projects are being started in these languages all the time by programmers who think they need C’s speed and think they’re good enough to avoid C’s traps and pitfalls.
But even if we can’t get rid of that language, we can force those who use it to do a better job. We would borrow a concept used every day in the physical world.
Obvious in retrospect
Of the three flaws, Heartbleed was by far the most significant. It is a bug in a program that implements a protocol called Secure Sockets Layer/Transport Layer Security (SSL/TLS), which is the fundamental encryption method used to protect the vast majority of the financial, medical, and personal information sent over the Internet. The original SSL protocol made Internet commerce possible back in the 1990s. OpenSSL is an open-source implementation of SSL/TLS that’s been around nearly as long. The program has steadily grown and been extended over the years.
Today’s cryptographic protocols are thought to be so strong that there is, in practice, no way to break them. But Heartbleed made SSL’s encryption irrelevant. Using Heartbleed, an attacker anywhere on the Internet could reach into the heart of a Web server’s memory and rip out a little piece of private data. The name doesn’t come from this metaphor but from the fact that Heartbleed is a flaw in the “heartbeat” protocol Web browsers can use to tell Web servers that they are still connected. Essentially, the attacker could ping Web servers in a way that not only confirmed the connection but also got them to spill some of their contents. It’s like being able to check into a hotel that occasionally forgets to empty its rooms’ trash cans between guests. Sometimes these contain highly valuable information.
Heartbleed resulted from a combination of factors, including a mistake made by a volunteer working on the OpenSSL program when he implemented the heartbeat protocol. Although any of the mistakes could have happened if OpenSSL had been written in a modern programming language like Java or C#, they were more likely to happen because OpenSSL was written in C.
Many developers design their own reliability tests and then run the tests themselves. Even in large companies, code that seems to work properly is frequently not tested for lurking flaws.
Apple’s flaw came about because some programmer inadvertently duplicated a line of code that, appropriately, read “goto fail.” The result was that under some conditions, iPhones and Macs would silently ignore errors that might occur when trying to ascertain the legitimacy of a website. With knowledge of this bug, an attacker could set up a wireless access point that might intercept Internet communications between iPhone users and their banks, silently steal usernames and passwords, and then reëncrypt the communications and send them on their merry way. This is called a “man-in-the-middle” attack, and it’s the very sort of thing that SSL/TLS was designed to prevent.
Remarkably, “goto fail” happened because of a feature in the C programming language that was known to be problematic before C was even invented! The “goto” statement makes a computer program jump from one place to another. Although such statements are common inside the computer’s machine code, computer scientists have tried for more than 40 years to avoid using “goto” statements in programs that they write in so-called “high-level language.” Java (designed in the early 1990s) doesn’t have a “goto” statement, but C (designed in the early 1970s) does. Although the Apple programmer responsible for the “goto fail” problem could have made a similar mistake without using the “goto” statement, it would have been much less probable.
We know less about the third bug because the underlying source code, part of Microsoft’s Internet Explorer, hasn’t been released. What we do know is that it was a “use after free” error: the program tells the operating system that it is finished using a piece of memory, and then it goes ahead and uses that memory again. According to the security firm FireEye, which tracked down the bug after hackers started using it against high-value targets, the flaw had been in Internet Explorer since August 2001 and affected more than half of those who got on the Web through traditional PCs. The bug was so significant that the Department of Homeland Security took the unusual step of telling people to temporarily stop running Internet Explorer. (Microsoft released a patch for the bug on May 1.)
Automated inspectors
There will always be problems in anything designed or built by humans, of course. That’s why we have policies in the physical world to minimize the chance for errors to occur and procedures designed to catch the mistakes that slip through.
Home builders must follow building codes, which regulate which construction materials can be used and govern certain aspects of the building’s layout—for example, hallways must reach a minimum width, and fire exits are required. Building inspectors visit the site throughout construction to review the work and make sure that it meets the codes. Inspectors will make contractors open up walls if they’ve installed them before getting the work inside inspected.
The world of software development is completely different. It’s common for developers to choose the language they write in and the tools they use. Many developers design their own reliability tests and then run the tests themselves! Big companies can afford separate quality–assurance teams, but many small firms go without. Even in large companies, code that seems to work properly is frequently not tested for lurking security flaws, because manual testing by other humans is incredibly expensive—sometimes more expensive than writing the original software, given that testing can reveal problems the developers then have to fix. Such flaws are sometimes called “technical debt,” since they are engineering costs borrowed against the future in the interest of shipping code now.
The solution is to establish software building codes and enforce those codes with an army of unpaid inspectors.
Crucially, those unpaid inspectors should not be people, or at least not only people. Some advocates of open-source software subscribe to the “many eyes” theory of software development: that if a piece of code is looked at by enough people, the security vulnerabilities will be found. Unfortunately, Heartbleed shows the fallacy in this argument: though OpenSSL is one of the most widely used open-source security programs, it took paid security engineers at Google and the Finnish IT security firm Codenomicon to find the bug—and they didn’t find it until two years after many eyes on the Internet first got access to the code.
Instead, this army of software building inspectors should be software development tools—the programs that developers use to create programs. These tools can needle, prod, and cajole programmers to do the right thing.
This has happened before. For example, back in 1988 the primary infection vector for the world’s first Internet worm was another program written in C. It used a function called “gets()” that was common at the time but is inherently insecure. After the worm was unleashed, the engineers who maintained the core libraries of the Unix operating system (which is now used by Linux and Mac OS) modified the gets() function to make it print the message “Warning: this program uses gets(), which is unsafe.” Soon afterward, developers everywhere removed gets() from their programs.
The same sort of approach can be used to prevent future bugs. Today many software development tools can analyze programs and warn of stylistic sloppiness (such as the use of a “goto” statement), memory bugs (such as the “use after free” flaw), or code that doesn’t follow established good-programming standards. Often, though, such warnings are disabled by default because many of them can be merely annoying: they require that code be rewritten and cleaned up with no corresponding improvement in security. Other bug–finding tools aren’t even included in standard development tool sets but must instead be separately downloaded, installed, and run. As a result, many developers don’t even know about them, let alone use them.
To make the Internet safer, the most stringent checking will need to be enabled by default. This will cause programmers to write better code from the beginning. And because program analysis tools work better with modern languages like C# and Java and less well with programs written in C, programmers should avoid starting new projects in C or C++—just as it is unwise to start construction projects using old-fashioned building materials and techniques.
Programmers are only human, and everybody makes mistakes. Software companies need to accept this fact and make bugs easier to prevent.
Simson L. Garfinkel is a contributing editor to MIT Technology Review and a professor of computer science at the Naval Postgraduate School.
In the nineteen-seventies, the Internet was a small, decentralized collective of computers. The personal-computer revolution that followed built upon that foundation, stoking optimism encapsulated by John Perry Barlow’s 1996 manifesto “A Declaration of the Independence of Cyberspace.” Barlow described a chaotic digital utopia, where “netizens” self-govern and the institutions of old hold no sway. “On behalf of the future, I ask you of the past to leave us alone,” he writes. “You are not welcome among us. You have no sovereignty where we gather.”
This is not the Internet we know today. Nearly two decades later, a staggering percentage of communications flow through a small set of corporations—and thus, under the profound influence of those companies and other institutions. Google, for instance, now comprises twenty-five per cent of all North American Internet traffic; an outage last August caused worldwide traffic to plummet by around forty per cent.
Engineers anticipated this convergence. As early as 1967, one of the key architects of the system for exchanging small packets of data that gave birth to the Internet, Paul Baran, predicted the rise of a centralized “computer utility” that would offer computing much the same way that power companies provide electricity. Today, that model is largely embodied by the information empires of Amazon, Google, and other cloud-computing companies. Like Baran anticipated, they offer us convenience at the expense of privacy.
Internet users now regularly submit to terms-of-service agreements that give companies license to share their personal data with other institutions, from advertisers to governments. In the U.S., the Electronic Communications Privacy Act, a law that predates the Web, allows law enforcement to obtain without a warrant private data that citizens entrust to third parties—including location data passively gathered from cell phones and the contents of e-mails that have either been opened or left unattended for a hundred and eighty days. As Edward Snowden’s leaks have shown, these vast troves of information allow intelligence agencies to focus on just a few key targets in order to monitor large portions of the world’s population.
One of those leaks, reported by the Washington Post in late October (2013), revealed that the National Security Agency secretly wiretapped the connections between data centers owned by Google and Yahoo, allowing the agency to collect users’ data as it flowed across the companies’ networks. Google engineers bristled at the news, and responded by encrypting those connections to prevent future intrusions; Yahoo has said it plans to do so by next year. More recently, Microsoft announced it would do the same, as well as open “transparency centers” that will allow some of its software’s source code to be inspected for hidden back doors. (However, that privilege appears to only extend to “government customers.”) On Monday, eight major tech firms, many of them competitors, united to demand an overhaul of government transparency and surveillance laws.
Still, an air of distrust surrounds the U.S. cloud industry. The N.S.A. collects data through formal arrangements with tech companies; ingests Web traffic as it enters and leaves the U.S.; and deliberately weakens cryptographic standards. A recently revealed document detailing the agency’s strategy specifically notes its mission to “influence the global commercial encryption market through commercial relationships” with companies developing and deploying security products.
One solution, espoused by some programmers, is to make the Internet more like it used to be—less centralized and more distributed. Jacob Cook, a twenty-three-year-old student, is the brains behind ArkOS, a lightweight version of the free Linux operating system. It runs on the credit-card-sized Raspberry Pi, a thirty-five dollar microcomputer adored by teachers and tinkerers. It’s designed so that average users can create personal clouds to store data that they can access anywhere, without relying on a distant data center owned by Dropbox or Amazon. It’s sort of like buying and maintaining your own car to get around, rather than relying on privately owned taxis. Cook’s mission is to “make hosting a server as easy as using a desktop P.C. or a smartphone,” he said.
Like other privacy advocates, Cook’s goal isn’t to end surveillance, but to make it harder to do en masse. “When you couple a secure, self-hosted platform with properly implemented cryptography, you can make N.S.A.-style spying and network intrusion extremely difficult and expensive,” he told me in an e-mail.
Persuading consumers to ditch the convenience of the cloud has never been an easy sell, however. In 2010, a team of young programmers announced Diaspora, a privacy-centric social network, to challenge Facebook’s centralized dominance. A year later, Eben Moglen, a law professor and champion of the Free Software movement, proposed a similar solution called the Freedom Box. The device he envisioned was to be a small computer that plugs into your home network, hosting files, enabling secure communication, and connecting to other boxes when needed. It was considered a call to arms—you alone would control your data.
But, while both projects met their fund-raising goals and drummed up a good deal of hype, neither came to fruition. Diaspora’s team fell into disarray after a disappointing beta launch, personal drama, and the appearance of new competitors such as Google+; apart from some privacy software released last year, Moglen’s Freedom Box has yet to materialize at all.
“There is a bigger problem with why so many of these efforts have failed” to achieve mass adoption, said Brennan Novak, a user-interface designer who works on privacy tools. The challenge, Novak said, is to make decentralized alternatives that are as secure, convenient, and seductive as a Google account. “It’s a tricky thing to pin down,” he told me in an encrypted online chat. “But I believe the problem exists somewhere between the barrier to entry (user-interface design, technical difficulty to set up, and over-all user experience) versus the perceived value of the tool, as seen by Joe Public and Joe Amateur Techie.”
One of Novak’s projects, Mailpile, is a crowd-funded e-mail application with built-in security tools that are normally too onerous for average people to set up and use—namely, Phil Zimmermann’s revolutionary but never widely adopted Pretty Good Privacy. “It’s a hard thing to explain…. A lot of peoples’ eyes glaze over,” he said. Instead, Mailpile is being designed in a way that gives users a sense of their level of privacy, without knowing about encryption keys or other complicated technology. Just as important, the app will allow users to self-host their e-mail accounts on a machine they control, so it can run on platforms like ArkOS.
“There already exist deep and geeky communities in cryptology or self-hosting or free software, but the message is rarely aimed at non-technical people,” said Irina Bolychevsky, an organizer for Redecentralize.org, an advocacy group that provides support for projects that aim to make the Web less centralized.
Several of those projects have been inspired by Bitcoin, the math-based e-money created by the mysterious Satoshi Nakamoto. While the peer-to-peer technology that Bitcoin employs isn’t novel, many engineers consider its implementation an enormous technical achievement. The network’s “nodes”—users running the Bitcoin software on their computers—collectively check the integrity of other nodes to ensure that no one spends the same coins twice. All transactions are published on a shared public ledger, called the “block chain,” and verified by “miners,” users whose powerful computers solve difficult math problems in exchange for freshly minted bitcoins. The system’s elegance has led some to wonder: if money can be decentralized and, to some extent, anonymized, can’t the same model be applied to other things, like e-mail?
Bitmessage is an e-mail replacement proposed last year that has been called the “the Bitcoin of online communication.” Instead of talking to a central mail server, Bitmessage distributes messages across a network of peers running the Bitmessage software. Unlike both Bitcoin and e-mail, Bitmessage “addresses” are cryptographically derived sequences that help encrypt a message’s contents automatically. That means that many parties help store and deliver the message, but only the intended recipient can read it. Another option obscures the sender’s identity; an alternate address sends the message on her behalf, similar to the anonymous “re-mailers” that arose from the cypherpunk movement of the nineteen-nineties.
Another ambitious project, Namecoin, is a P2P system almost identical to Bitcoin. But instead of currency, it functions as a decentralized replacement for the Internet’s Domain Name System. The D.N.S. is the essential “phone book” that translates a Web site’s typed address (www.newyorker.com) to the corresponding computer’s numerical I.P. address (192.168.1.1). The directory is decentralized by design, but it still has central points of authority: domain registrars, which buy and lease Web addresses to site owners, and the U.S.-based Internet Corporation for Assigned Names and Numbers, or I.C.A.N.N., which controls the distribution of domains.
The infrastructure does allow for large-scale takedowns, like in 2010, when the Department of Justice tried to seize ten domains it believed to be hosting child pornography, but accidentally took down eighty-four thousand innocent Web sites in the process. Instead of centralized registrars, Namecoin uses cryptographic tokens similar to bitcoins to authenticate ownership of “.bit” domains. In theory, these domain names can’t be hijacked by criminals or blocked by governments; no one except the owner can surrender them.
Solutions like these follow a path different from Mailpile and ArkOS. Their peer-to-peer architecture holds the potential for greatly improved privacy and security on the Internet. But existing apart from commonly used protocols and standards can also preclude any possibility of widespread adoption. Still, Novak said, the transition to an Internet that relies more extensively on decentralized, P2P technology is “an absolutely essential development,” since it would make many attacks by malicious actors—criminals and intelligence agencies alike—impractical.
Though Snowden has raised the profile of privacy technology, it will be up to engineers and their allies to make that technology viable for the masses. “Decentralization must become a viable alternative,” said Cook, the ArkOS developer, “not just to give options to users that can self-host, but also to put pressure on the political and corporate institutions.”
“Discussions about innovation, resilience, open protocols, data ownership and the numerous surrounding issues,” said Redecentralize’s Bolychevsky, “need to become mainstream if we want the Internet to stay free, democratic, and engaging.”
“Connected devices are central to our long-term strategy of injecting sophisticated computation and knowledge into everything. With the Wolfram Language we now have a way to describe and compute about things in the world. Connected devices are what we need to measure and interface with those things.
“In the end, we want every type of connected device to be seamlessly integrated with the Wolfram Language. And this will have all sorts of important consequences. But as we work toward this, there’s an obvious first step: we have to know what types of connected devices there actually are.
“So to have a way to answer that question, today we’re launching the Wolfram Connected Devices Project—whose goal is to work with device manufacturers and the technical community to provide a definitive, curated, source of systematic knowledge about connected devices….”
Lev Manovich is a leading theorist of cultural objects produced with digital technology, perhaps best known for The Language of New Media (MIT Press, 2001). I interviewed him about his most recent book, Software Takes Command (Bloomsbury Academic, July 2014).
Photograph published in Alan Kay and Adele Goldberg, "Personal Dynamic Media" with the caption, "Kids learning to use the interim Dynabook."
MICHAEL CONNOR: I want to start with the question of methodology. How does one study software? In other words, what is the object of study—do you focus more on the interface, or the underlying code, or some combination of the two?
LEV MANOVICH: The goal of my book is to understand media software—its genealogy (where does it come from), its anatomy (the key features shared by all media viewing and editing software), and its effects in the world (pragmatics). Specifically, I am concerned with two kinds of effects:
1) How media design software shapes the media being created, making some design choices seem natural and easy to execute, while hiding other design possibilities;
2) How media viewing / managing / remixing software shapes our experience of media and the actions we perform on it.
I devote significant space to the analysis of After Effects, Photoshop and Google Earth—these are my primary case studies.
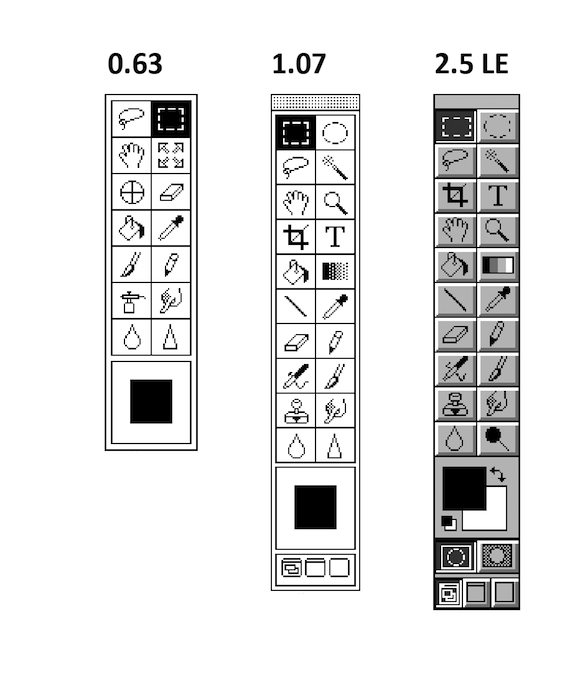
Photoshop Toolbox from version 0.63 (1988) to 7.0 (2002).
I also want to understand what media is today conceptually, after its "softwarization." Do the concepts of media developed to account for industrial-era technologies, from photography to video, still apply to media that is designed and experienced with software? Do they need to be updated, or completely replaced by new more appropriate concepts? For example: do we still have different media or did they merge into a single new meta-medium? Are there some structural features which motion graphics, graphic designs, web sites, product designs, buildings, and video games all share, since they are all designed with software?
In short: does "media" still exist?
For me, "software studies" is about asking such broad questions, as opposed to only focusing on code or interface. Our world, media, economy, and social relations all run on software. So any investigation of code, software architectures, or interfaces is only valuable if it helps us to understand how these technologies are reshaping societies and individuals, and our imaginations.
MC: In order to ask these questions, your book begins by delving into some early ideas from the 1960s and 1970s that had a profound influence on later developers. In looking at these historical precedents, to what extent were you able to engage with the original software or documentation thereof? And to what extent were you relying on written texts by these early figures?
Photograph published in Kay and Goldberg with the caption, "The interim Dynabook system consists of processor, disk drive, display, keyboard, and pointing devices."
LM: In my book I only discuss the ideas of a few of the most important people, and for this, I could find enough sources. I focused on the theoretical ideas from the 1960s and 1970s which led to the development of modern media authoring environment, and the common features of their interfaces. My primary documents were published articles by J. C. R. Licklider, Ivan Sutherland, Ted Nelson, Douglas Engelbart, Alan Kay, and their collaborators, and also a few surviving film clips—Sutherland demonstrating Sketchpad (the first interactive drawing system seen by the public), a tour of Xerox Alto, etc. I also consulted manuals for a few early systems which are available online.
While I was doing this research, I was shocked to realize how little visual documentation of the key systems and software (Sketchpad, Xerox Parc's Alto, first paint programs from late 1960s and 1970s) exists. We have original articles published about these systems with small black-and-white illustrations, and just a few low resolution film clips. And nothing else. None of the historically important systems exist in emulation, so you can't get a feeling of what it was like to use them.
This situation is quite different with other media technologies. You can go to a film museum and experience the real Panoroma from early 1840s, camera obscura, or another pre-cinematic technology. Painters today use the same "new media" as Impressionists in the 1870s—paints in tubes. With computer systems, most of the ideas behind contemporary media software come directly from the 1960s and 1970s—but the original systems are not accessible. Given the number of artists and programmers working today in "software art" and "creative coding," it should be possible to create emulations of at least a few most fundamental early systems. It's good to take care of your parents!
MC: One of the key early examples in your book is Alan Kay's concept of the "Dynabook," which posited the computer as "personal dynamic media" which could be used by all. These ideas were spelled out in his writing, and brought to some fruition in the Xerox Alto computer. I'd like to ask you about the documentation of these systems that does survive. What importance can we attach to these images of users, interfaces and the cultural objects produced with these systems?
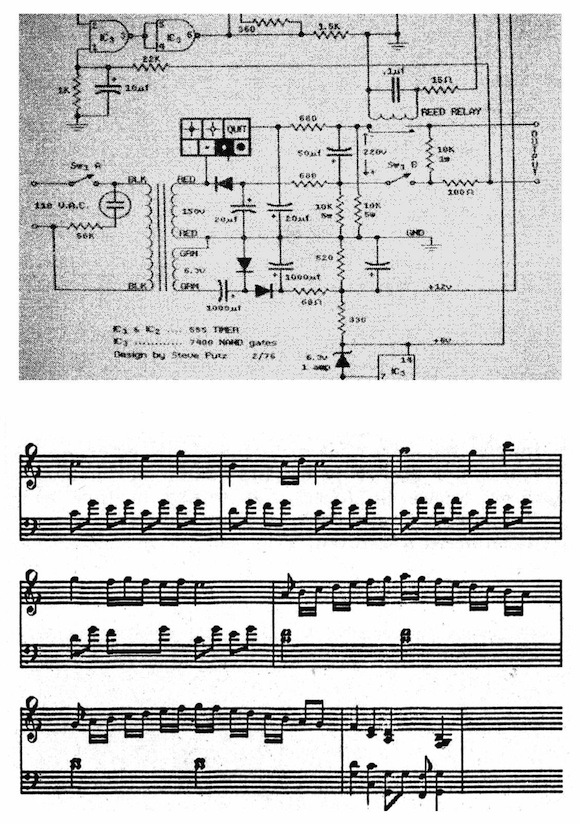
Top and center: Images published in Kay and Goldberg with the captions, "An electronic circuit layout system programmed by a 15-year- old student" and "Data for this score was captured on a musical keyboard. A program then converts the data to standard musical notation." Bottom: The Alto Screen showing windows with graphics drawn using commands in Smalltalk programming language.
LM: The most informative sets of images of Alan Kay's "Dynabook" (Xerox Alto) appears in the article he wrote with his collaborator Adele Goldberg in 1977. In my book I analyze this article in detail, interpreting it as "media theory" (as opposed to just documentation of the system). Kay said that reading McLuhan convinced him that computer can be a medium for personal expression. The article presents theoretical development of this idea and reports on its practical implementation (Xerox Alto).
Alan Turing theoretically defined a computer as a machine that can simulate a very large class of other machines, and it is this simulation ability that is largely responsible for the proliferation of computers in modern society. But it was only Kay and his generation that extended the idea of simulation to media—thus turning the Universal Turing Machine into a Universal Media Machine, so to speak. Accordingly, Kay and Goldberg write in the article: "In a very real sense, simulation is the central notion of the Dynabook." However, as I suggest in the book, simulating existing media become a chance to extend and add new functions. Kay and Goldberg themselves are clear about this—here is, for example, what they say about an electronic book: "It need not be treated as a simulated paper book since this is a new medium with new properties. A dynamic search may be made for a particular context. The non-sequential nature of the file medium and the use of dynamic manipulation allow a story to have many accessible points of view."
The many images of media software developed both by Xerox team and other Alto users which appear in the article illustrate these ideas. Kay and Goldberg strategically give us examples of how their "interim 'Dynabook'" can allow users to paint, draw, animate, compose music, and compose text. This maked Alto first Universal Media Machine—the first computer offering ability to compose and create cultural experiences and artifacts for all senses.
MC: I'm a bit surprised to hear you say the words "just documentation!" In the case of Kay, his theoretical argument was perhaps more important than any single prototype. But, in general, one of the things I find compelling about your approach is your analysis of specific elements of interfaces and computer operations. So when you use the example of Ivan Sutherland's Sketchpad, wasn't it the documentation (the demo for a television show produced by MIT in 1964) that allowed you to make the argument that even this early software wasn't merely a simulation of drawing, but a partial reinvention of it?
Frames from Sketchpad demo video illustrating the program’s use of constraints. Left column: a user selects parts of a drawing. Right column: Sketchpad automatically adjusts the drawing. (The captured frames were edited in Photoshop to show the Sketchpad screen more clearly.)
LM: The reason I said "just documentation" is that normally people dont think about Sutherland, Engelbart or Kay as "media theorists," and I think it's more common to read their work as technical reports.
On to to Sutherland. Sutherland describes the new features of his system in his Ph.D. thesis and the published article, so in principle you can just read them and get these ideas. But at the same time, the short film clip which demonstrates the Sketchpad is invaluable—it helps you to better understand how these new features (such as "contraints satisfaction") actually worked, and also to "experience" them emotionally. Since I have seen the film clip years before I looked at Sutherland's PhD thesis (now available online), I can't really say what was more important. Maybe it was not even the original film clip, but its use in one of Alan Kay's lectures. In the lecture Alan Kay shows the clip, and explains how important these new features were.
MC: The Sketchpad demo does have a visceral impact. You began this interview by asking, "does media still exist?" Along these lines, the Sutherland clip raises the question of whether drawing, for one, still exists. The implications of this seem pretty enormous. Now that you have established the principle that all media are contingent on the software that produces, do we need to begin analyzing all media (film, drawing or photography) from the point of view of software studies? Where might that lead?
LM: The answer which I arrive to the question "does media still exist?" after 200 pages is relevant to all media which is designed or accessed with software tools. What we identify by conceptual inertia as "properties" of different mediums are actually the properties of media software—their interfaces, the tools, and the techniques they make possible for navigating, creating, editing, and sharing media documents. For example, the ability to automatically switch between different views of a document in Acrobat Reader or Microsoft Word is not a property of “text documents,” but as a result of software techniques whose heritage can be traced to Engelbart’s “view control.” Similarly, "zoom" or "pan" is not exclusive to digital images or texts or 3D scenes—its the properly of all modern media software.
Along with these and a number of other "media-independent" techniques (such as "search") which are build into all media software, there are also "media-specific" techniques which can only be used with particular data types. For example, we can extrude a 2-D shape to make a 3D model, but we can't extrude a text. Or, we can change contrast and saturation on a photo, but these operations do not make sense in relation to 3D models, texts, or sound.
So when we think of photography, film or any other medium, we can think of it as a combination of "media-independent" techniques which it shares with all other mediums, and also techniques which are specific to it.
MC: I'd proposed the title, "Don't Study Media, Study Software" for this article. But it sounds like you are taking a more balanced view?
LM: Your title makes me nervous, because some people are likely to misinterpret it. I prefer to study software such as Twitter, Facebook, Instagram, Photoshop, After Effects, game engines, etc., and use this understanding in interpreting the content created with this software—tweets, messages, social media photos, professional designs, video games, etc. For example, just this morning I was looking at a presentation by one of Twitter's engineers about the service, and learned that sometimes the responses to tweets can arrive before the tweet itself. This is important to know if we are to analyze the content of Twitter communication between people, for example.
Today, all cultural forms which require a user to click even once on their device to access and/or participate run on software. We can't ignore technology any longer. In short: "software takes command."
[Image: The World Trade Center towers, photographer unknown].
Amongst many other interesting moments in Siobhan Roberts's new biography of Alan Davenport, the "father of modern wind engineering," is the incredible story of a room in Eugene, Oregon.
In August 1965, Roberts explains, "ads in the local newspaper... promised complimentary checkups at the new Oregon Research Institute Vision Research Center." But these promised eye exams were not all that they seemed.
The office was, in fact, a model—a disguised simulation—including a "stereotypical waiting room" where respondents to the ad would be "greeted by a receptionist" who could escort them into a fake "examination room" that turned out to be examining something else entirely.
While members of the public were led through a series of eye tests, looking at "some triangles," in Roberts words, that had been projected onto the wall, they were, in fact, being jostled back and forth, silently and unannounced, by motors installed on tracks below the floor. The room swayed, rocking side to side, shifting imperceptibly—or so the experiment was testing—beneath the feet of the volunteers and the actor-nurses who, without breaking character, took care of them.
It turns out that the whole thing was actually a wind-condition simulator for a pair of buildings that had not yet been publicly announced, let alone constructed: the future twin towers of New York City's World Trade Center. This quiet office in Oregon, paid for by the Port Authority, was an unpublicized test-run for the high winds and other complicated atmospheric effects that would soon rock the two towers back and forth at their unprecedented height in southern Manhattan.
The room, "mounted on a wheeled platform driven by hydraulic actuators," thus tested unsuspecting members of the public for their physiological reaction to the swaying of the floor—testing whether "conflicting brain inputs" from the moving architecture "would cause synaptic confusion, or motion sickness—nausea, dizziness, fatigue," as Roberts writes.
Unbeknownst to them, then, people in Eugene, Oregon, in 1965, were helping to test the aerodynamic flexibility of two buildings that had not yet been announced and that would soon come to dominate the skyline of New York City—leaving at least me to wonder if some room today somewhere, some doctor's office or other nondescript chamber, whether a classroom or a restaurant, is actually a testing ground for as-yet unrealized architectures to come, be it in New York City, Dubai, Mexico City, or, who knows, even for future travelers to the moon.
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.





.jpg)
.jpg)
.jpg)