As we continue to lack a decent search engine on this blog and as we don't use a "tag cloud" ... This post could help navigate through the updated content on | rblg (as of 09.2023), via all its tags!
FIND BELOW ALL THE TAGS THAT CAN BE USED TO NAVIGATE IN THE CONTENTS OF | RBLG BLOG:
(to be seen just below if you're navigating on the blog's html pages or here for rss readers)
--
Note that we had to hit the "pause" button on our reblogging activities a while ago (mainly because we ran out of time, but also because we received complaints from a major image stock company about some images that were displayed on | rblg, an activity that we felt was still "fair use" - we've never made any money or advertised on this site).
Nevertheless, we continue to publish from time to time information on the activities of fabric | ch, or content directly related to its work (documentation).
The exhibition Beneath the Skin, Between the Machines just opened at HOW Art Museum (Hao Art Gallery) and fabric | ch was keen to be invited to create a large installation for the show, also intented to be used during a symposium that will be entirely part of the exhibition (panels and talks as part of the installation therefore). The exhibition will be open between January 15 - April 24 2022 in Shanghai.
Along with a selection of chinese and international artists, curator Liaoliao Fu asked us to develop a proposal based on a former architectural device, Public Platform of Future-Past, which in itself was inspired by an older installation of ours... Heterochrony.
This new work, entitled Platform of Future-Past, deals with the temporal oddity that can be produced and induced by the recording, accumulation and storage of monitoring data, which contributes to leaving partial traces of "reality", functioning as spectres of the past.
We are proud to present this work along artists such as Hito Steyerl, Geumhyung Jeong, Lu Yang, Jon Rafman, Forensic Architecture, Lynn Hershman Leeson and Harun Farocki.
...
Last but not least and somehow a "sign of the times", this is the first exhibition in which we are participating and whose main financial backers are a blockchain and crypto-finance company, as well as a NFT platform. Both based in China.
More information about the symposium will be published.
"Man is only man at the surface. Remove the skin, dissect, and immediately you come to machinery.” When Paul Valéry wrote this down, he might not foresee that human beings – a biological organism – would indeed be incorporated into machinery at such a profound level in a highly informationized and computerized time and space. In a sense, it is just as what Marx predicted: a conscious connection of machine[1]. Today, machine is no longer confined to any material form; instead, it presents itself in the forms of data, coding and algorithm – virtually everything that is “operable”, “calculable” and “thinkable”. Ever since the idea of cyborg emerges, the man-machine relation has always been intertwined with our imagination, vision and fear of the past, present and future.
In a sense, machine represents a projection of human beings. We human beings transfer ideas of slavery and freedom to other beings, namely a machine that could replace human beings as technical entities or tools. Opposite (and similar, in a sense,) to the “embodiment” of machine, organic beings such as human beings are hurrying to move towards “disembodiment”. Everything pertinent to our body and behavior can be captured and calculated as data. In the meantime, the social system that human beings have created never stops absorbing new technologies. During the process of trial and error, the difference and fortuity accompanying the “new” are taken in and internalized by the system. “Every accident, every impulse, every error is productive (of the social system),”[2]and hence is predictable and calculable. Within such a system, differences tend to be obfuscated and erased, but meanwhile due to highly professional complexities embedded in different disciplines/fields, genuine interdisciplinary communication is becoming increasingly difficult, if not impossible.
As a result, technologies today are highly centralized, homogenized, sophisticated and commonized. They penetrate deeply into our skin, but beyond knowing, sensing and thinking. On the one hand, the exhibition probes into the reconfiguration of man by technologies through what’s “beneath the skin”; and on the other, encourages people to rethink the position and situation we’re in under this context through what’s “between the machines”. As an art institute located at Shanghai Zhangjiang Hi-Tech Industrial Development Zone, one of the most important hi-tech parks in China, HOW Art Museum intends to carve out an open rather than enclosed field through the exhibition, inviting the public to immerse themselves and ponder upon the questions such as “How people touch machines?”, “What the machines think of us?” and “Where to position art and its practice in the face of the overwhelming presence of technology and the intricate technological reality?”
Departing from these issues, the exhibition presents a selection of recent works of Revital Cohen & Tuur Van Balen, Simon Denny, Harun Farocki, Nicolás Lamas, Lynn Hershman Leeson, Lu Yang, Lam Pok Yin, David OReilly, Pakui Hardware, Jon Rafman, Hito Steyerl, Shi Zheng and Geumhyung Jeong. In the meantime, it intends to set up a “panel installation”, specially created byfabric | chfor this exhibition, trying to offer a space and occasion for decentralized observation and participation in the above discussions. Conversations and actions are to be activated as well as captured, observed and archived at the same time.
[1]Karl Marx, “Fragment on Machines”,Foundations of a Critique of Political Economy
Duration: January 15-April 24, 2022
Artists: Revital Cohen & Tuur Van Balen, Simon Denny, fabric | ch, Harun Farocki, Geumhyung Jeong, Nicolás Lamas, Lynn Hershman Leeson, Lu Yang, Lam Pok Yin, David OReilly, Pakui Hardware, Jon Rafman, Hito Steyerl, Shi Zheng
Curator: Fu Liaoliao
Organizer: HOW Art Museum, Shanghai
Lead Sponsor: APENFT Foundation
Swiss participation is supported by Pro Helvetia Shanghai, Swiss Arts Council.
(Swiss speakers and performers appearing in the educational events will be updated soon.)
-----
Work by fabric | ch
HOW Art Museum has invited Lausanne-based artist group fabric | ch to set up a “panel installation” based on their former project “Public Platform of Future Past” and adapted to the museum space, fostering insightful communication among practitioners from different fields and the audiences.
“Platform of Future-Past” is a temporary environmental device that consists in a twenty meters long walkway, or rather an observation deck, almost archaeological: a platform that overlooks an exhibition space and that, paradoxically, directly links its entrance to its exit. It thus offers the possibility of crossing this space without really entering it and of becoming its observer, as from archaeological observation decks. The platform opens- up contrasting atmospheres and offers affordances or potential uses on the ground.
The peculiarity of the work consists thus in the fact that it generates a dual perception and a potential temporal disruption, which leads to the title of the work, Platform of Future-Past: if the present time of the exhibition space and its visitors is, in fact, the “archeology” to be observed from the platform, and hence a potential “past,” then the present time of the walkway could be understood as a possible “future” viewed from the ground…
“Platform of Future-Past” is equipped in three zones with environmental monitoring devices. The sensors record as much data as possible over time, generated by the continuously changing conditions, presences and uses in the exhibition space. The data is then stored on Platform Future-Past’s servers and replayed in a loop on its computers. It is a “recorded moment”, “frozen” on the data servers, that could potentially replay itself forever or is waiting for someone to reactivate it. A “data center” on the deck, with its set of interfaces and visualizations screens, lets the visitors-observers follow the ongoing process of recording.
The work could be seen as an architectural proposal built on the idea of massive data production from our environment. Every second, our world produces massive amounts of data, stored “forever” in remote data centers, like old gas bubbles trapped in millennial ice.
As such, the project is attempting to introduce doubt about its true nature: would it be possible, in fact, that what is observed from the platform is already a present recorded from the past? A phantom situation? A present regenerated from the data recorded during a scientific experiment that was left abandoned? Or perhaps replayed by the machine itself ? Could it already, in fact, be running on a loop for years?
Platform of Future-Past, Scaffolding, projection screens, sensors, data storage, data flows, plywood panels, textile partitions
-----
Platform of Future-Past (2022)
-----
Beneath the Skin, Between the Machines (exhibition, 01.22 - 04.22)
-----
Platform of Future-Past was realized with the support of Pro Helvetia.
I like to believe that we tried on our side to address this question of public space - mediated and somehow "franchised" by technology - through many of our past works at fabric | ch. We even tried with our limited means to articulate or bring scaled answers to these questions...
A collection of essays by prominent creators collected by MIT explores the uncertain nature of common space in the contemporary world. And the answer to the question in the title is yes!
Gediminas Urbonas, Ann Lui and Lucas Freeman are the editors of a book that presents a wide range of intellectual reflections and artistic experimentations centred around the concept of public space. The title of the volume, Public Space? Lost and Found, immediately places the reader in a doubtful state: nothing should be taken for granted or as certain, given that we are asking ourselves if, in fact, public space still exists.
This question was originally the basis for a symposium and an exhibition hosted by MIT in 2014, as part of the work of ACT, the acronym for the Art, Culture and Technology programme. Contained within the incredibly well-oiled scientific and technological machine that is MIT, ACT is a strange creature, a hybrid where sometimes extremely different practices cross paths, producing exciting results: exhibitions; critical analyses, which often examine the foundations and the tendencies of the university itself, underpinned by an interest in the political role of research; actual inventions, developed in collaboration with other labs and university courses, that attract students who have a desire to exchange ideas with people from different paths and want the chance to take part in initiatives that operate free from educational preconceptions.
The book is one of the many avenues of communication pursued by ACT, currently directed by Gediminas Urbonas (a Lithuanian visual artist who has taught there since 2009) who succeeded the curator Ute Meta Bauer. The collection explores how the idea of public space is at the heart of what interests artists and designers and how, consequently, the conception, the creation and the use of collective spaces are a response to current-day transformations. These include the spread of digital technologies, climate change, the enforcement of austerity policies due to the reduction in available resources, and the emergence of political arguments that favour separation between people. The concluding conversation Reflexivity and Resistance in Communicative Capitalism between Urbonas and Jodi Dean, an American political scientist, summarises many of the book’s ideas: public space becomes the tool for resisting the growing privatisation of our lives.
The book, which features stupendous graphics by Node (a design studio based in Berlin and Oslo), is divided into four sections: paradoxes, ecologies, jurisdictions and signals.
The contents alternate essays (like Angela Vettese’s analysis of the role of national pavilions at the Biennale di Venezia or Beatriz Colomina’s reflections about the impact of social media on issues of privacy) with the presentation of architectural projects and artistic interventions designed by architects like Andrés Jaque, Teddy Cruz and Marjetica Potr or by historic MIT professors like the multimedia artist Antoni Muntadas. The republication of Art and Ecological Consciousness, a 1972 book by György Kepes, the multi-disciplinary genius who was the director of the Center for Advanced Visual Studies at MIT, proves that the institution has long been interested in these topics.
This collection of contributions supported by captivating iconography signals a basic optimism: the documented actions and projects and the consciousness that motivates the thinking of many creators proves there is a collective mobilisation, often starting from the bottom, that seeks out and creates the conditions for communal life. Even if it is never explicitly written, the answer to the question in the title is a resounding yes.
Public Space? Lost and Found Gediminas Urbonas, Ann Lui and Lucas Freeman
SA + P Press, MIT School of Architecture and Planning
Cambridge MA, 2017
300 pages, $40 mit.edu
Overview
“Public space” is a potent and contentious topic among artists, architects, and cultural producers. Public Space? Lost and Found considers the role of aesthetic practices within the construction, identification, and critique of shared territories, and how artists or architects—the “antennae of the race”—can heighten our awareness of rapidly changing formulations of public space in the age of digital media, vast ecological crises, and civic uprisings.
Public Space? Lost and Found combines significant recent projects in art and architecture with writings by historians and theorists. Contributors investigate strategies for responding to underrepresented communities and areas of conflict through the work of Marjetica Potrč in Johannesburg and Teddy Cruz on the Mexico-U.S. border, among others. They explore our collective stakes in ecological catastrophe through artisticresearch such as atelier d’architecture autogérée’s hubs for community action and recycling in Colombes, France, and Brian Holmes’s theoretical investigation of new forms of aesthetic perception in the age of the Anthropocene. Inspired by artist and MIT professor Antoni Muntadas’ early coining of the term “media landscape,” contributors also look ahead, casting a critical eye on the fraught impact of digital media and the internet on public space.
This book is the first in a new series of volumes produced by the MIT School of Architecture and Planning’s Program in Art, Culture and Technology.
Contributors atelier d'architecture autogérée, Dennis Adams, Bik Van Der Pol, Adrian Blackwell, Ina Blom, Christoph Brunner with Gerald Raunig, Néstor García Canclini, Colby Chamberlain, Beatriz Colomina, Teddy Cruz with Fonna Forman, Jodi Dean, Juan Herreros, Brian Holmes, Andrés Jaque, Caroline Jones, Coryn Kempster with Julia Jamrozik, György Kepes, Rikke Luther, Matthew Mazzotta, Metahaven, Timothy Morton, Antoni Muntadas, Otto Piene, Marjetica Potrč, Nader Tehrani, Troy Therrien, Gedminas and Nomeda Urbonas, Angela Vettese, Mariel Villeré, Mark Wigley, Krzysztof Wodiczko
With section openings from Ana María León, T. J. Demos, Doris Sommer, and Catherine D'Ignazio
Note: let's "start" this new (delusional?) year with this short video about the ways "they" see things, and us. They? The "machines" of course, the bots, the algorithms...
An interesting reassembled trailer that was posted by Matthew Plummer-Fernandez on his Tumblr #algopop that documents the "appearance of algorithms in popular culture". Matthew was with us back in 2014, to collaborate on a research project at ECAL that will soon end btw and worked around this idea of bots in design.
Will this technological future become "delusional" as well, if we don't care enough? As essayist Eric Sadin points it in his recent book, "La silicolonisation du monde" (in French only at this time)?
Possibly... It is with no doubt up to each of us (to act), so as regarding our everyday life in common with our fellow human beings!
Everything but the detected objects are removed from the trailer of The Wolf of Wall Street. The software is powered by Yolo object-detection, which has been used for similar experiments.
Note: j'aurai le plaisir d'être en entretien --en français-- ce vendredi 26.02 à 20h avec le journaliste Frédéric Pfyffer, de la Radio Télévision Suisse Romande, dans le cadre du programme Histoire Vivante qui traite cette semaine du sujet des "Big Data".
Cet entretien, qui a été enregistré en fin de semaine passée, nous verra évoquer la façon dont les artistes ou designers abordent aujourd'hui --mais aussi un peu hier-- cette question des données. En contrepoint ou complément peut-être des approches scientifiques. Pour ma part, aussi bien dans le contexte de ma pratique indépendante (fabric | ch où de nombreux projets réalisés ou en développement s'appuient sur des données) qu'académique (projet de recherche interdisciplinaire en cours autour des "nuages"... entre autres).
À noter encore qu'au terme de la semaine d'émissions thématiques sera diffusé sur la TSR (dimanche 28.02) le documentaire Citizenfour, qui relate toute l'aventure d'Edward Snowden et du journaliste Glenn Greenwald.
Une semaine d’Histoire Vivante consacrée à l’histoire de la recherche scientifique à la lumière de l’émergence de l’internet et des big data.
-
Dimanche 28 février 2016, vous pouvez découvrir sur RTS Deux: CitizenFour, un documentaire de Laura Poitras (Allemagne-USA/2014):
"Citizenfour est le pseudonyme utilisé par Edward Snowden pour contacter la réalisatrice de ce documentaire lorsqu'il décide de révéler les méthodes de surveillance de la NSA. Accompagnée d'un journaliste d'investigation, elle le rejoint dans une chambre d'hôtel à Hong Kong. La suite est un huis-clos digne des meilleurs thrillers."
I'm very happy to write that after several months of preparation, I'm leading a new design-research (that follows Variable Environment, dating back from 2007!) for the University of Art & design, Lausanne (ECAL), in partnership with Nicolas Nova (HEAD). The project will see the transversal collaboration of architects, interaction designers, ethnographers and scientists with the aim of re-investigating "cloud computing" and its infrastructures from a different point of view. The name of the project: Inhabiting and Interfacing the Cloud(s), which is now online under the form of a blog that will document our progresses. The project should last until 2016.
The main research team is composed of:
Patrick Keller, co-head (Prof. ECAL M&ID, fabric | ch) / Nicolas Nova, co-head (Prof. HEAD MD, Near Future Laboratory) / Christophe Guignard (Prof. ECAL M&ID, fabric | ch) / Lucien Langton (assistant ECAL M&ID) / Charles Chalas (assistant HEAD MD) / Dieter Dietz (Prof. EPFL - Alice) & Caroline Dionne (Post-doc EPFL - Alice) / Dr. Christian Babski (fabric | ch).
I&IC Workshops with students from the HEAD, ECAL (interaction design) and EPFL (architecture) will be conducted by:
James Auger (Prof. RCA, Auger - Loizeau) / Matthew Plummer-Fernandez (Visiting Tutor Goldsmiths College, Algopop) / Thomas Favre - Bulle (Lecturer EPFL).
Finally, a group of "advisors" will keep an eye on us and the research artifacts we may produce:
Babak Falsafi (Prof. EPFL - Ecocloud) / Prof. Zhang Ga (TASML, Tsinghua University) / Dan Hill (City of Sound, Future Cities Catapult) / Ludger Hovestadt (Prof. ETHZ - CAAD) / Geoff Manaugh (BLDGBLOG, Gizmodo).
Andrea Branzi, 1969, Research for "No-Stop City".
Google data center in Lenoir, North Carolina (USA), 2013.
As stated on the I&IC webiste:
The design research I&IC (Inhabiting and Interfacing the Clouds), explores the creation of counter-proposals to the current expression of “Cloud Computing”, particularly in its forms intended for private individuals and end users (“Personal Cloud”). It is led by Profs. Patrick Keller (ECAL) and Nicolas Nova (HEAD) and is documented online as a work in progress, 2014-2017.
I&IC is to offer an alternative point of view, a critical appraisal as well as to provide an “access to tools” about this iconic infrastructure of our modernity and its user interfaces, because to date their implementation has followed a logic chiefly of technical development, mainly governed by corporate interests, and continues therefore to be paradoxically envisioned as a purely functional, centralized setup.
However, the Personal Cloud holds a potential that is largely untapped in terms of design, novel uses and territorial strategies. Through its cross-disciplinary approach that links interaction design, the architectural and territorial dimensions as well as ethnographic studies, our project aims at producing alternative models resulting from a more contemporary approach, notably factoring in the idea of creolization (theorized by E. Glissant).
Many smartphone apps use a device’s sensors to try to measure people’s physical well-being, for example by counting every step they take. A new app developed by researchers at Dartmouth College suggests that a phone’s sensors can also be used to peek inside a person’s mind and gauge mental health.
When 48 students let the app collect information from their phones for an entire 10-week term, patterns in the data matched up with changes in stress, depression, and loneliness that showed up when they took the kind of surveys doctors use to assess their patients’ mood and mental health. Trends in the phone data also correlated with students’ grades.
The results suggest that smartphone apps could offer people and doctors new ways to manage mental well-being, says Andrew Campbell, the Dartmouth professor who led the research.
Previous studies have shown that custom-built mobile gadgets could indirectly gauge mental states. The Dartmouth study, however, used Android smartphones like those owned by millions of people, says Campbell. “We’re the first to use standard phones and sensors that are just carried without any user interaction,” he says. A paper on the research was presented last week at the ACM International Joint Conference on Pervasive and Ubiquitous Computing in Seattle.
Campbell’s app, called StudentLife, collects data including a phone’s motion and location and the timing of calls and texts, and occasionally activates the microphone on a device to run software that can tell if a conversation is taking place nearby. Algorithms process that information into logs of a person’s physical activity, communication patterns, sleeping patterns, visits to different places, and an estimate of how often they were involved in face-to-face conversation. Many changes in those patterns were found to correlate significantly with changes in measures of depression, loneliness, and stress. For example, decline in exposure to face-to-face conversations was indicative of depression.
The surveys used as a benchmark for mental health in the study are more normally used by doctors to assess patients who seek help for mental health conditions. In the future, data from a person’s phone could provide a richer picture to augment a one-off survey when a person seeks help, says Campbell. He is also planning further research into how data from his app might be used to tip off individuals or their caregivers when behavioral patterns indicate that their mental health could be changing. In the case of students, that approach could provide a way to reduce dropout rates or help people improve their academic performance, says Campbell.
“Intervention is the next step,” he says. “It could be something simple like telling a person they should go and engage in conversations to improve their mood, or that, statistically, if you party only three nights a week you will get more decent grades.” Campbell is also working on a study testing whether a similar app could help predict relapses in people with schizophrenia.
A startup called Ginger.io with an app similar to Campbell’s is already testing similar ideas with some health-care providers. In one trial with diabetics, changes in a person’s behavior triggered an alert to nurses, who reach out to make sure that the patient was adhering to his medication (see “Smartphone Tracker Gives Doctors Remote Viewing Powers”).
Anmol Madan, CEO and cofounder of Ginger.io, says the Dartmouth study adds to the evidence that those ideas are valuable. However, he notes, much larger studies are needed to really convince doctors and health-care providers to adopt a new approach. Ginger.io has found similar associations between its own data and clinical scales for depression, says Madan, although results have not been published.
Both Ginger.io and the Dartmouth work were inspired by research at the MIT Media Lab that established the idea that data from personal devices offers a new way to study human behavior (see “TR10: Social Physics”). Yaniv Altshuler, a researcher who helped pioneer that approach, says the Dartmouth study is an interesting addition to that body of work, but it’s also a reminder that there will be downsides to the mobile data trove. Being able to use mobile devices to learn very sensitive information about people could raise new privacy risks.
Campbell—who got clearance for his study from an ethical review board—notes that his results show how existing privacy rules can be left behind by data mining. A health-care provider collecting data using standard mental health surveys would be bound by HIPAA data privacy regulations in the United States. It’s less clear what rules apply when that same data is derived from a phone app. “If you have signals you can use to work out, say, that I am a manic depressive, what governs use of that data is not well accepted,” he says.
Whatever the answer, apps that log the kind of rich data Campbell collected are likely to become more common. Smartphone sensors have become much more energy-efficient, so detailed, round-the-clock data logging is now feasible without wiping out battery life. “As of six months ago phones got to the point where we could do 24/7 sensing,” says Campbell. “All the technology has now arrived that you can do these things.”
As Web companies and government agencies analyze ever more information about our lives, it’s tempting to respond by passing new privacy laws or creating mechanisms that pay us for our data. Instead, we need a civic solution, because democracy is at risk.
In 1967, The Public Interest, then a leading venue for highbrow policy debate, published a provocative essay by Paul Baran, one of the fathers of the data transmission method known as packet switching. Titled “The Future Computer Utility,” the essay speculated that someday a few big, centralized computers would provide “information processing … the same way one now buys electricity.”
Our home computer console will be used to send and receive messages—like telegrams. We could check to see whether the local department store has the advertised sports shirt in stock in the desired color and size. We could ask when delivery would be guaranteed, if we ordered. The information would be up-to-the-minute and accurate. We could pay our bills and compute our taxes via the console. We would ask questions and receive answers from “information banks”—automated versions of today’s libraries. We would obtain up-to-the-minute listing of all television and radio programs … The computer could, itself, send a message to remind us of an impending anniversary and save us from the disastrous consequences of forgetfulness.
It took decades for cloud computing to fulfill Baran’s vision. But he was prescient enough to worry that utility computing would need its own regulatory model. Here was an employee of the RAND Corporation—hardly a redoubt of Marxist thought—fretting about the concentration of market power in the hands of large computer utilities and demanding state intervention. Baran also wanted policies that could “offer maximum protection to the preservation of the rights of privacy of information”:
Highly sensitive personal and important business information will be stored in many of the contemplated systems … At present, nothing more than trust—or, at best, a lack of technical sophistication—stands in the way of a would-be eavesdropper … Today we lack the mechanisms to insure adequate safeguards. Because of the difficulty in rebuilding complex systems to incorporate safeguards at a later date, it appears desirable to anticipate these problems.
Sharp, bullshit-free analysis: techno-futurism has been in decline ever since.
All the privacy solutions you hear about are on the wrong track.
To read Baran’s essay (just one of the many on utility computing published at the time) is to realize that our contemporary privacy problem is not contemporary. It’s not just a consequence of Mark Zuckerberg’s selling his soul and our profiles to the NSA. The problem was recognized early on, and little was done about it.
Almost all of Baran’s envisioned uses for “utility computing” are purely commercial. Ordering shirts, paying bills, looking for entertainment, conquering forgetfulness: this is not the Internet of “virtual communities” and “netizens.” Baran simply imagined that networked computing would allow us to do things that we already do without networked computing: shopping, entertainment, research. But also: espionage, surveillance, and voyeurism.
If Baran’s “computer revolution” doesn’t sound very revolutionary, it’s in part because he did not imagine that it would upend the foundations of capitalism and bureaucratic administration that had been in place for centuries. By the 1990s, however, many digital enthusiasts believed otherwise; they were convinced that the spread of digital networks and the rapid decline in communication costs represented a genuinely new stage in human development. For them, the surveillance triggered in the 2000s by 9/11 and the colonization of these pristine digital spaces by Google, Facebook, and big data were aberrations that could be resisted or at least reversed. If only we could now erase the decade we lost and return to the utopia of the 1980s and 1990s by passing stricter laws, giving users more control, and building better encryption tools!
A different reading of recent history would yield a different agenda for the future. The widespread feeling of emancipation through information that many people still attribute to the 1990s was probably just a prolonged hallucination. Both capitalism and bureaucratic administration easily accommodated themselves to the new digital regime; both thrive on information flows, the more automated the better. Laws, markets, or technologies won’t stymie or redirect that demand for data, as all three play a role in sustaining capitalism and bureaucratic administration in the first place. Something else is needed: politics.
Even programs that seem innocuous can undermine democracy.
First, let’s address the symptoms of our current malaise. Yes, the commercial interests of technology companies and the policy interests of government agencies have converged: both are interested in the collection and rapid analysis of user data. Google and Facebook are compelled to collect ever more data to boost the effectiveness of the ads they sell. Government agencies need the same data—they can collect it either on their own or in coöperation with technology companies—to pursue their own programs.
Many of those programs deal with national security. But such data can be used in many other ways that also undermine privacy. The Italian government, for example, is using a tool called the redditometro, or income meter, which analyzes receipts and spending patterns to flag people who spend more than they claim in income as potential tax cheaters. Once mobile payments replace a large percentage of cash transactions—with Google and Facebook as intermediaries—the data collected by these companies will be indispensable to tax collectors. Likewise, legal academics are busy exploring how data mining can be used to craft contracts or wills tailored to the personalities, characteristics, and past behavior of individual citizens, boosting efficiency and reducing malpractice.
On another front, technocrats like Cass Sunstein, the former administrator of the Office of Information and Regulatory Affairs at the White House and a leading proponent of “nanny statecraft” that nudges citizens to do certain things, hope that the collection and instant analysis of data about individuals can help solve problems like obesity, climate change, and drunk driving by steering our behavior. A new book by three British academics—Changing Behaviours: On the Rise of the Psychological State—features a long list of such schemes at work in the U.K., where the government’s nudging unit, inspired by Sunstein, has been so successful that it’s about to become a for-profit operation.
Thanks to smartphones or Google Glass, we can now be pinged whenever we are about to do something stupid, unhealthy, or unsound. We wouldn’t necessarily need to know why the action would be wrong: the system’s algorithms do the moral calculus on their own. Citizens take on the role of information machines that feed the techno-bureaucratic complex with our data. And why wouldn’t we, if we are promised slimmer waistlines, cleaner air, or longer (and safer) lives in return?
This logic of preëmption is not different from that of the NSA in its fight against terror: let’s prevent problems rather than deal with their consequences. Even if we tie the hands of the NSA—by some combination of better oversight, stricter rules on data access, or stronger and friendlier encryption technologies—the data hunger of other state institutions would remain. They will justify it. On issues like obesity or climate change—where the policy makers are quick to add that we are facing a ticking-bomb scenario—they will say a little deficit of democracy can go a long way.
Here’s what that deficit would look like: the new digital infrastructure, thriving as it does on real-time data contributed by citizens, allows the technocrats to take politics, with all its noise, friction, and discontent, out of the political process. It replaces the messy stuff of coalition-building, bargaining, and deliberation with the cleanliness and efficiency of data-powered administration.
This phenomenon has a meme-friendly name: “algorithmic regulation,” as Silicon Valley publisher Tim O’Reilly calls it. In essence, information-rich democracies have reached a point where they want to try to solve public problems without having to explain or justify themselves to citizens. Instead, they can simply appeal to our own self-interest—and they know enough about us to engineer a perfect, highly personalized, irresistible nudge.
Privacy is a means to democracy, not an end in itself.
Another warning from the past. The year was 1985, and Spiros Simitis, Germany’s leading privacy scholar and practitioner—at the time the data protection commissioner of the German state of Hesse—was addressing the University of Pennsylvania Law School. His lecture explored the very same issue that preoccupied Baran: the automation of data processing. But Simitis didn’t lose sight of the history of capitalism and democracy, so he saw technological changes in a far more ambiguous light.
He also recognized that privacy is not an end in itself. It’s a means of achieving a certain ideal of democratic politics, where citizens are trusted to be more than just self-contented suppliers of information to all-seeing and all-optimizing technocrats. “Where privacy is dismantled,” warned Simitis, “both the chance for personal assessment of the political … process and the opportunity to develop and maintain a particular style of life fade.”
Three technological trends underpinned Simitis’s analysis. First, he noted, even back then, every sphere of social interaction was mediated by information technology—he warned of “the intensive retrieval of personal data of virtually every employee, taxpayer, patient, bank customer, welfare recipient, or car driver.” As a result, privacy was no longer solely a problem of some unlucky fellow caught off-guard in an awkward situation; it had become everyone’s problem. Second, new technologies like smart cards and videotex not only were making it possible to “record and reconstruct individual activities in minute detail” but also were normalizing surveillance, weaving it into our everyday life. Third, the personal information recorded by these new technologies was allowing social institutions to enforce standards of behavior, triggering “long-term strategies of manipulation intended to mold and adjust individual conduct.”
Modern institutions certainly stood to gain from all this. Insurance companies could tailor cost-saving programs to the needs and demands of patients, hospitals, and the pharmaceutical industry. Police could use newly available databases and various “mobility profiles” to identify potential criminals and locate suspects. Welfare agencies could suddenly unearth fraudulent behavior.
But how would these technologies affect us as citizens—as subjects who participate in understanding and reforming the world around us, not just as consumers or customers who merely benefit from it?
In case after case, Simitis argued, we stood to lose. Instead of getting more context for decisions, we would get less; instead of seeing the logic driving our bureaucratic systems and making that logic more accurate and less Kafkaesque, we would get more confusion because decision making was becoming automated and no one knew how exactly the algorithms worked. We would perceive a murkier picture of what makes our social institutions work; despite the promise of greater personalization and empowerment, the interactive systems would provide only an illusion of more participation. As a result, “interactive systems … suggest individual activity where in fact no more than stereotyped reactions occur.”
If you think Simitis was describing a future that never came to pass, consider a recent paper on the transparency of automated prediction systems by Tal Zarsky, one of the world’s leading experts on the politics and ethics of data mining. He notes that “data mining might point to individuals and events, indicating elevated risk, without telling us why they were selected.” As it happens, the degree of interpretability is one of the most consequential policy decisions to be made in designing data-mining systems. Zarsky sees vast implications for democracy here:
A non-interpretable process might follow from a data-mining analysis which is not explainable in human language. Here, the software makes its selection decisions based upon multiple variables (even thousands) … It would be difficult for the government to provide a detailed response when asked why an individual was singled out to receive differentiated treatment by an automated recommendation system. The most the government could say is that this is what the algorithm found based on previous cases.
This is the future we are sleepwalking into. Everything seems to work, and things might even be getting better—it’s just that we don’t know exactly why or how.
Too little privacy can endanger democracy. But so can too much privacy.
Simitis got the trends right. Free from dubious assumptions about “the Internet age,” he arrived at an original but cautious defense of privacy as a vital feature of a self-critical democracy—not the democracy of some abstract political theory but the messy, noisy democracy we inhabit, with its never-ending contradictions. In particular, Simitis’s most crucial insight is that privacy can both support and undermine democracy.
Traditionally, our response to changes in automated information processing has been to view them as a personal problem for the affected individuals. A case in point is the seminal article “The Right to Privacy,” by Louis Brandeis and Samuel Warren. Writing in 1890, they sought a “right to be let alone”—to live an undisturbed life, away from intruders. According to Simitis, they expressed a desire, common to many self-made individuals at the time, “to enjoy, strictly for themselves and under conditions they determined, the fruits of their economic and social activity.”
A laudable goal: without extending such legal cover to entrepreneurs, modern American capitalism might have never become so robust. But this right, disconnected from any matching responsibilities, could also sanction an excessive level of withdrawal that shields us from the outside world and undermines the foundations of the very democratic regime that made the right possible. If all citizens were to fully exercise their right to privacy, society would be deprived of the transparent and readily available data that’s needed not only for the technocrats’ sake but—even more—so that citizens can evaluate issues, form opinions, and debate (and, occasionally, fire the technocrats).
This is not a problem specific to the right to privacy. For some contemporary thinkers, such as the French historian and philosopher Marcel Gauchet, democracies risk falling victim to their own success: having instituted a legal regime of rights that allow citizens to pursue their own private interests without any reference to what’s good for the public, they stand to exhaust the very resources that have allowed them to flourish.
When all citizens demand their rights but are unaware of their responsibilities, the political questions that have defined democratic life over centuries—How should we live together? What is in the public interest, and how do I balance my own interest with it?—are subsumed into legal, economic, or administrative domains. “The political” and “the public” no longer register as domains at all; laws, markets, and technologies displace debate and contestation as preferred, less messy solutions.
But a democracy without engaged citizens doesn’t sound much like a democracy—and might not survive as one. This was obvious to Thomas Jefferson, who, while wanting every citizen to be “a participator in the government of affairs,” also believed that civic participation involves a constant tension between public and private life. A society that believes, as Simitis put it, that the citizen’s access to information “ends where the bourgeois’ claim for privacy begins” won’t last as a well-functioning democracy.
Thus the balance between privacy and transparency is especially in need of adjustment in times of rapid technological change. That balance itself is a political issue par excellence, to be settled through public debate and always left open for negotiation. It can’t be settled once and for all by some combination of theories, markets, and technologies. As Simitis said: “Far from being considered a constitutive element of a democratic society, privacy appears as a tolerated contradiction, the implications of which must be continuously reconsidered.”
Laws and market mechanisms are insufficient solutions.
In the last few decades, as we began to generate more data, our institutions became addicted. If you withheld the data and severed the feedback loops, it’s not clear whether they could continue at all. We, as citizens, are caught in an odd position: our reason for disclosing the data is not that we feel deep concern for the public good. No, we release data out of self-interest, on Google or via self-tracking apps. We are too cheap not to use free services subsidized by advertising. Or we want to track our fitness and diet, and then we sell the data.
Simitis knew even in 1985 that this would inevitably lead to the “algorithmic regulation” taking shape today, as politics becomes “public administration” that runs on autopilot so that citizens can relax and enjoy themselves, only to be nudged, occasionally, whenever they are about to forget to buy broccoli.
Habits, activities, and preferences are compiled, registered, and retrieved to facilitate better adjustment, not to improve the individual’s capacity to act and to decide. Whatever the original incentive for computerization may have been, processing increasingly appears as the ideal means to adapt an individual to a predetermined, standardized behavior that aims at the highest possible degree of compliance with the model patient, consumer, taxpayer, employee, or citizen.
What Simitis is describing here is the construction of what I call “invisible barbed wire” around our intellectual and social lives. Big data, with its many interconnected databases that feed on information and algorithms of dubious provenance, imposes severe constraints on how we mature politically and socially. The German philosopher Jürgen Habermas was right to warn—in 1963—that “an exclusively technical civilization … is threatened … by the splitting of human beings into two classes—the social engineers and the inmates of closed social institutions.”
The invisible barbed wire of big data limits our lives to a space that might look quiet and enticing enough but is not of our own choosing and that we cannot rebuild or expand. The worst part is that we do not see it as such. Because we believe that we are free to go anywhere, the barbed wire remains invisible. Worse, there’s no one to blame: certainly not Google, Dick Cheney, or the NSA. It’s the result of many different logics and systems—of modern capitalism, of bureaucratic governance, of risk management—that get supercharged by the automation of information processing and by the depoliticization of politics.
The more information we reveal about ourselves, the denser but more invisible this barbed wire becomes. We gradually lose our capacity to reason and debate; we no longer understand why things happen to us.
But all is not lost. We could learn to perceive ourselves as trapped within this barbed wire and even cut through it. Privacy is the resource that allows us to do that and, should we be so lucky, even to plan our escape route.
This is where Simitis expressed a truly revolutionary insight that is lost in contemporary privacy debates: no progress can be achieved, he said, as long as privacy protection is “more or less equated with an individual’s right to decide when and which data are to be accessible.” The trap that many well-meaning privacy advocates fall into is thinking that if only they could provide the individual with more control over his or her data—through stronger laws or a robust property regime—then the invisible barbed wire would become visible and fray. It won’t—not if that data is eventually returned to the very institutions that are erecting the wire around us.
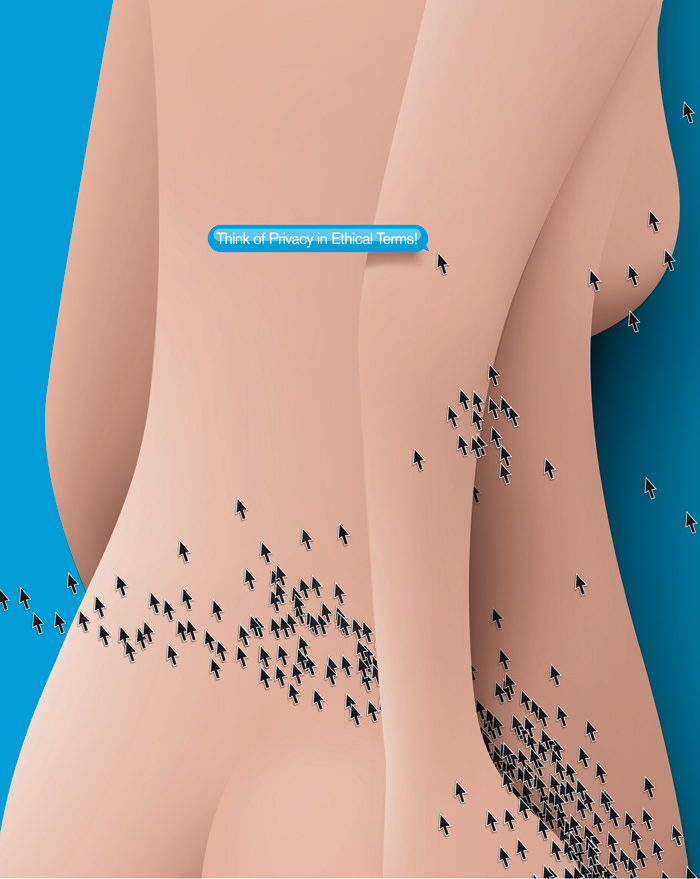
Think of privacy in ethical terms.
If we accept privacy as a problem of and for democracy, then popular fixes are inadequate. For example, in his book Who Owns the Future?, Jaron Lanier proposes that we disregard one pole of privacy—the legal one—and focus on the economic one instead. “Commercial rights are better suited for the multitude of quirky little situations that will come up in real life than new kinds of civil rights along the lines of digital privacy,” he writes. On this logic, by turning our data into an asset that we might sell, we accomplish two things. First, we can control who has access to it, and second, we can make up for some of the economic losses caused by the disruption of everything analog.
Lanier’s proposal is not original. In Code and Other Laws of Cyberspace (first published in 1999), Lawrence Lessig enthused about building a property regime around private data. Lessig wanted an “electronic butler” that could negotiate with websites: “The user sets her preferences once—specifies how she would negotiate privacy and what she is willing to give up—and from that moment on, when she enters a site, the site and her machine negotiate. Only if the machines can agree will the site be able to obtain her personal data.”
It’s easy to see where such reasoning could take us. We’d all have customized smartphone apps that would continually incorporate the latest information about the people we meet, the places we visit, and the information we possess in order to update the price of our personal data portfolio. It would be extremely dynamic: if you are walking by a fancy store selling jewelry, the store might be willing to pay more to know your spouse’s birthday than it is when you are sitting at home watching TV.
The property regime can, indeed, strengthen privacy: if consumers want a good return on their data portfolio, they need to ensure that their data is not already available elsewhere. Thus they either “rent” it the way Netflix rents movies or sell it on the condition that it can be used or resold only under tightly controlled conditions. Some companies already offer “data lockers” to facilitate such secure exchanges.
So if you want to defend the “right to privacy” for its own sake, turning data into a tradable asset could resolve your misgivings. The NSA would still get what it wanted; but if you’re worried that our private information has become too liquid and that we’ve lost control over its movements, a smart business model, coupled with a strong digital-rights-management regime, could fix that.
Meanwhile, government agencies committed to “nanny statecraft” would want this data as well. Perhaps they might pay a small fee or promise a tax credit for the privilege of nudging you later on—with the help of the data from your smartphone. Consumers win, entrepreneurs win, technocrats win. Privacy, in one way or another, is preserved also. So who, exactly, loses here? If you’ve read your Simitis, you know the answer: democracy does.
It’s not just because the invisible barbed wire would remain. We also should worry about the implications for justice and equality. For example, my decision to disclose personal information, even if I disclose it only to my insurance company, will inevitably have implications for other people, many of them less well off. People who say that tracking their fitness or location is merely an affirmative choice from which they can opt out have little knowledge of how institutions think. Once there are enough early adopters who self-track—and most of them are likely to gain something from it—those who refuse will no longer be seen as just quirky individuals exercising their autonomy. No, they will be considered deviants with something to hide. Their insurance will be more expensive. If we never lose sight of this fact, our decision to self-track won’t be as easy to reduce to pure economic self-interest; at some point, moral considerations might kick in. Do I really want to share my data and get a coupon I do not need if it means that someone else who is already working three jobs may ultimately have to pay more? Such moral concerns are rendered moot if we delegate decision-making to “electronic butlers.”
Few of us have had moral pangs about data-sharing schemes, but that could change. Before the environment became a global concern, few of us thought twice about taking public transport if we could drive. Before ethical consumption became a global concern, no one would have paid more for coffee that tasted the same but promised “fair trade.” Consider a cheap T-shirt you see in a store. It might be perfectly legal to buy it, but after decades of hard work by activist groups, a “Made in Bangladesh” label makes us think twice about doing so. Perhaps we fear that it was made by children or exploited adults. Or, having thought about it, maybe we actually do want to buy the T-shirt because we hope it might support the work of a child who would otherwise be forced into prostitution. What is the right thing to do here? We don’t know—so we do some research. Such scrutiny can’t apply to everything we buy, or we’d never leave the store. But exchanges of information—the oxygen of democratic life—should fall into the category of “Apply more thought, not less.” It’s not something to be delegated to an “electronic butler”—not if we don’t want to cleanse our life of its political dimension.
Sabotage the system. Provoke more questions.
We should also be troubled by the suggestion that we can reduce the privacy problem to the legal dimension. The question we’ve been asking for the last two decades—How can we make sure that we have more control over our personal information?—cannot be the only question to ask. Unless we learn and continuously relearn how automated information processing promotes and impedes democratic life, an answer to this question might prove worthless, especially if the democratic regime needed to implement whatever answer we come up with unravels in the meantime.
Intellectually, at least, it’s clear what needs to be done: we must confront the question not only in the economic and legal dimensions but also in a political one, linking the future of privacy with the future of democracy in a way that refuses to reduce privacy either to markets or to laws. What does this philosophical insight mean in practice?
First, we must politicize the debate about privacy and information sharing. Articulating the existence—and the profound political consequences—of the invisible barbed wire would be a good start. We must scrutinize data-intensive problem solving and expose its occasionally antidemocratic character. At times we should accept more risk, imperfection, improvisation, and inefficiency in the name of keeping the democratic spirit alive.
Second, we must learn how to sabotage the system—perhaps by refusing to self-track at all. If refusing to record our calorie intake or our whereabouts is the only way to get policy makers to address the structural causes of problems like obesity or climate change—and not just tinker with their symptoms through nudging—information boycotts might be justifiable. Refusing to make money off your own data might be as political an act as refusing to drive a car or eat meat. Privacy can then reëmerge as a political instrument for keeping the spirit of democracy alive: we want private spaces because we still believe in our ability to reflect on what ails the world and find a way to fix it, and we’d rather not surrender this capacity to algorithms and feedback loops.
Third, we need more provocative digital services. It’s not enough for a website to prompt us to decide who should see our data. Instead it should reawaken our own imaginations. Designed right, sites would not nudge citizens to either guard or share their private information but would reveal the hidden political dimensions to various acts of information sharing. We don’t want an electronic butler—we want an electronic provocateur. Instead of yet another app that could tell us how much money we can save by monitoring our exercise routine, we need an app that can tell us how many people are likely to lose health insurance if the insurance industry has as much data as the NSA, most of it contributed by consumers like us. Eventually we might discern such dimensions on our own, without any technological prompts.
Finally, we have to abandon fixed preconceptions about how our digital services work and interconnect. Otherwise, we’ll fall victim to the same logic that has constrained the imagination of so many well-meaning privacy advocates who think that defending the “right to privacy”—not fighting to preserve democracy—is what should drive public policy. While many Internet activists would surely argue otherwise, what happens to the Internet is of only secondary importance. Just as with privacy, it’s the fate of democracy itself that should be our primary goal.
After all, back in 1967 Paul Baran was lucky enough not to know what the Internet would become. That didn’t stop him from seeing the benefits of utility computing and its dangers. Abandon the idea that the Internet fell from grace over the last decade. Liberating ourselves from that misreading of history could help us address the antidemocratic threats of the digital future.
Evgeny Morozov is the author of The Net Delusion: The Dark Side of Internet Freedom and To Save Everything, Click Here: The Folly of Technological Solutionism.
Sentiment analysis on the social web depends on how a person’s state of mind is expressed in words. Now a new database of the links between words and emotions could provide a better foundation for this kind of analysis.
One of the buzzphrases associated with the social web is sentiment analysis. This is the ability to determine a person’s opinion or state of mind by analysing the words they post on Twitter, Facebook or some other medium.
Much has been promised with this method—the ability to measure satisfaction with politicians, movies and products; the ability to better manage customer relations; the ability to create dialogue for emotion-aware games; the ability to measure the flow of emotion in novels; and so on.
The idea is to entirely automate this process—to analyse the firehose of words produced by social websites using advanced data mining techniques to gauge sentiment on a vast scale.
But all this depends on how well we understand the emotion and polarity (whether negative or positive) that people associate with each word or combinations of words.
Today, Saif Mohammad and Peter Turney at the National Research Council Canada in Ottawa unveil a huge database of words and their associated emotions and polarity, which they have assembled quickly and inexpensively using Amazon’s crowdsourcing Mechanical Turk website. They say this crowdsourcing mechanism makes it possible to increase the size and quality of the database quickly and easily.
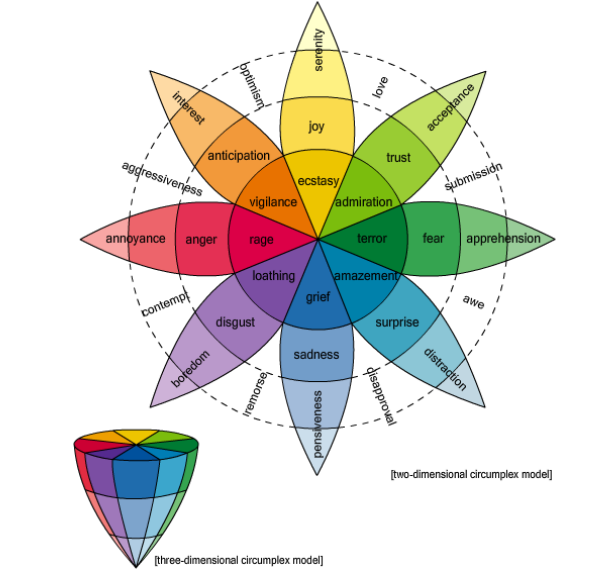
Most psychologists believe that there are essentially six basic emotions– joy, sadness, anger, fear, disgust, and surprise– or at most eight if you include trust and anticipation. So the task of any word-emotion lexicon is to determine how strongly a word is associated with each of these emotions.
One way to do this is to use a small group of experts to associate emotions with a set of words. One of the most famous databases, created in the 1960s and known as the General Inquirer database, has over 11,000 words labelled with 182 different tags, including some of the emotions that psychologist now think are the most basic.
A more modern database is the WordNet Affect Lexicon, which has a few hundred words tagged in this way. This used a small group of experts to manually tag a set of seed words with the basic emotions. The size of this database was then dramatically increased by automatically associating the same emotions with all the synonyms of these words.
One of the problems with these approaches is the sheer time it takes to compile a large database so Mohammad and Turney tried a different approach.
These guys selected about 10,000 words from an existing thesaurus and the lexicons described above and then created a set of five questions to ask about each word that would reveal the emotions and polarity associated with it. That’s a total of over 50,000 questions.
They then asked these questions to over 2000 people, or Turkers, on Amazon’s Mechanical Turk website, paying 4 cents for each set of properly answered questions.
The result is a comprehensive word-emotion lexicon for over 10,000 words or two-word phrases which they call EmoLex.
One important factor in this research is the quality of the answers that crowdsourcing gives. For example, some Turkers might answer at random or even deliberately enter wrong answers.
Mohammad and Turney have tackled this by inserting test questions that they use to judge whether or not the Turker is answering well. If not, all the data from that person is ignored.
They tested the quality of their database by comparing it to earlier ones created by experts and say it compares well. “We compared a subset of our lexicon with existing gold standard data to show that the annotations obtained are indeed of high quality,” they say.
This approach has significant potential for the future. Mohammad and Turney say it should be straightforward to increase the size of the date database and at the same technique can be easily adapted to create similar lexicons in other languages. And all this can be done very cheaply—they spent $2100 on Mechanical Turk in this work.
The bottom line is that sentiment analysis can only ever be as good as the database on which it relies. With EmoLex, analysts have a new tool for their box of tricks.
The NSA revelations highlight the role sophisticated algorithms play in sifting through masses of data. But more surprising is their widespread use in our everyday lives. So should we be more wary of their power?
The financial sector has long used algorithms to predict market fluctuations, but they can also help police identify crime hot spots or online shops target their customers. Photograph: Danil Melekhin/Getty Images
On 4 August 2005, the police department of Memphis, Tennessee, made so many arrests over a three-hour period that it ran out of vehicles to transport the detainees to jail. Three days later, 1,200 people had been arrested across the city – a new police department record. Operation Blue Crush was hailed a huge success.
Larry Godwin, the city's new police director, quickly rolled out the scheme and by 2011 crime across the city had fallen by 24%. When it was revealed Blue Crush faced budget cuts earlier this year, there was public outcry. "Crush" policing is now perceived to be so successful that it has reportedly been mimicked across the globe, including in countries such as Poland and Israel. In 2010, it was reported that two police forces in the UK were using it, but their identities were not revealed.
Crush stands for "Criminal Reduction Utilising Statistical History". Translated, it means predictive policing. Or, more accurately, police officers guided by algorithms. A team of criminologists and data scientists at the University of Memphis first developed the technique using IBM predictive analytics software. Put simply, they compiled crime statistics from across the city over time and overlaid it with other datasets – social housing maps, outside temperatures etc – then instructed algorithms to search for correlations in the data to identify crime "hot spots". The police then flooded those areas with highly targeted patrols.
"It's putting the right people in the right places on the right day at the right time," said Dr Richard Janikowski, an associate professor in the department of criminology and criminal justice at the University of Memphis, when the scheme launched. But not everyone is comfortable with the idea. Some critics have dubbed it "Minority Report" policing, in reference to the sci-fi film in which psychics are used to guide a "PreCrime" police unit.
The use of algorithms in policing is one example of their increasing influence on our lives. And, as their ubiquity spreads, so too does the debate around whether we should allow ourselves to become so reliant on them – and who, if anyone, is policing their use. Such concerns were sharpened further by the continuing revelations about how the US National Security Agency (NSA) has been using algorithms to help it interpret the colossal amounts of data it has collected from its covert dragnet of international telecommunications.
"For datasets the size of those the NSA collect, using algorithms is the only way to operate for certain tasks," says James Ball, the Guardian's data editor and part of the paper's NSA Files reporting team. "The problem is how the rules are set: it's impossible to do this perfectly. If you're, say, looking for terrorists, you're looking for something very rare. Set your rules too tight and you'll miss lots of, probably most, potential terror suspects. But set them more broadly and you'll drag lots of entirely blameless people into your dragnet, who will then face further intrusion or even formal investigation. We don't know exactly how the NSA or GCHQ use algorithms – or how extensively they're applied. But we do know they use them, including on the huge data trawls revealed in the Guardian."
From dating websites and City trading floors, through to online retailing and internet searches (Google's search algorithm is now a more closely guarded commercial secret than the recipe for Coca-Cola), algorithms are increasingly determining our collective futures. "Bank approvals, store cards, job matches and more all run on similar principles," says Ball. "The algorithm is the god from the machine powering them all, for good or ill."
Most observers blame the 'flash crash' of May 2010 on the use of algorithms to perform high-frequency trading. Photograph: Spencer Platt/Getty Images
But what is an algorithm? Dr Panos Parpas, a lecturer in the quantitative analysis and decision science ("quads") section of the department of computing at Imperial College London, says that wherever we use computers, we rely on algorithms: "There are lots of types, but algorithms, explained simply, follow a series of instructions to solve a problem. It's a bit like how a recipe helps you to bake a cake. Instead of having generic flour or a generic oven temperature, the algorithm will try a range of variations to produce the best cake possible from the options and permutations available."
Parpas stresses that algorithms are not a new phenomenon: "They've been used for decades – back to Alan Turing and the codebreakers, and beyond – but the current interest in them is due to the vast amounts of data now being generated and the need to process and understand it. They are now integrated into our lives. On the one hand, they are good because they free up our time and do mundane processes on our behalf. The questions being raised about algorithms at the moment are not about algorithms per se, but about the way society is structured with regard to data use and data privacy. It's also about how models are being used to predict the future. There is currently an awkward marriage between data and algorithms. As technology evolves, there will be mistakes, but it is important to remember they are just a tool. We shouldn't blame our tools."
The "mistakes" Parpas refers to are events such as the "flash crash" of 6 May 2010, when the Dow Jones industrial average fell 1,000 points in just a few minutes, only to see the market regain itself 20 minutes later. The reasons for the sudden plummet has never been fully explained, but most financial observers blame a "race to the bottom" by the competing quantitative trading (quants) algorithms widely used to perform high-frequency trading. Scott Patterson, a Wall Street Journal reporter and author of The Quants, likens the use of algorithms on trading floors to flying a plane on autopilot. The vast majority of trades these days are performed by algorithms, but when things go wrong, as happened during the flash crash, humans can intervene.
"By far the most complicated algorithms are to be found in science, where they are used to design new drugs or model the climate," says Parpas. "But they are done within a controlled environment with clean data. It is easy to see if there is a bug in the algorithm. The difficulties come when they are used in the social sciences and financial trading, where there is less understanding of what the model and output should be, and where they are operating in a more dynamic environment. Scientists will take years to validate their algorithm, whereas a trader has just days to do so in a volatile environment."
Most investment banks now have a team of computer science PhDs coding algorithms, says Parpas, who used to work on such a team. "With City trading, everyone is running very similar algorithms," he says. "They all follow each other, meaning you get results such as the flash crash. They use them to speed up the process and to break up big trades to disguise them from competitors when a big investment is being made. It's an on-going, live process. They will run new algorithms for a few days to test them before letting them loose with real money. In currency trading, an algorithm lasts for about two weeks before it is stopped because it is surpassed by a new one. In equities, which is a less complicated market, they will run for a few months before a new one replaces them. It takes a day or two to write a currency algorithm. It's hard to find out information about them because, for understandable reasons, they don't like to advertise when they are successful. Goldman Sachs, though, has a strong reputation across the investment banks for having a brilliant team of algorithm scientists. PhDs students in this field will usually be employed within a few months by an investment bank."
The idea that the world's financial markets – and, hence, the wellbeing of our pensions, shareholdings, savings etc – are now largely determined by algorithmic vagaries is unsettling enough for some. But, as the NSA revelations exposed, the bigger questions surrounding algorithms centre on governance and privacy. How are they being used to access and interpret "our" data? And by whom?
Dr Ian Brown, the associate director of Oxford University's Cyber Security Centre, says we all urgently need to consider the implications of allowing commercial interests and governments to use algorithms to analyse our habits: "Most of us assume that 'big data' is munificent. The laws in the US and UK say that much of this [the NSA revelations] is allowed, it's just that most people don't realise yet. But there is a big question about oversight. We now spend so much of our time online that we are creating huge data-mining opportunities."
Algorithms can run the risk of linking some racial groups to particular crimes. Photograph: Alamy
Brown says that algorithms are now programmed to look for "indirect, non-obvious" correlations in data. "For example, in the US, healthcare companies can now make assessments about a good or bad insurance risk based, in part, on the distance you commute to work," he says. "They will identity the low-risk people and market their policies at them. Over time, this creates or exacerbates societal divides. Professor Oscar Gandy, at the University of Pennsylvania, has done research into 'secondary racial discrimination', whereby credit and health insurance, which relies greatly on postcodes, can discriminate against racial groups because they happen to live very close to other racial groups that score badly."
Brown harbours similar concerns over the use of algorithms to aid policing, as seen in Memphis where Crush's algorithms have reportedly linked some racial groups to particular crimes: "If you have a group that is disproportionately stopped by the police, such tactics could just magnify the perception they have of being targeted."
Viktor Mayer-Schönberger, professor of internet governance and regulation at the Oxford Internet Institute, also warns against humans seeing causation when an algorithm identifies a correlation in vast swaths of data. "This transformation presents an entirely new menace: penalties based on propensities," he writes in his new book, Big Data: A Revolution That Will Transform How We Live, Work and Think, which is co-authored by Kenneth Cukier, the Economist's data editor. "That is the possibility of using big-data predictions about people to judge and punish them even before they've acted. Doing this negates ideas of fairness, justice and free will. In addition to privacy and propensity, there is a third danger. We risk falling victim to a dictatorship of data, whereby we fetishise the information, the output of our analyses, and end up misusing it. Handled responsibly, big data is a useful tool of rational decision-making. Wielded unwisely, it can become an instrument of the powerful, who may turn it into a source of repression, either by simply frustrating customers and employees or, worse, by harming citizens."
Mayer-Schönberger presents two very different real-life scenarios to illustrate how algorithms are being used. First, he explains how the analytics team working for US retailer Target can now calculate whether a woman is pregnant and, if so, when she is due to give birth: "They noticed that these women bought lots of unscented lotion at around the third month of pregnancy, and that a few weeks later they tended to purchase supplements such as magnesium, calcium and zinc. The team ultimately uncovered around two dozen products that, used as proxies, enabled the company to calculate a 'pregnancy prediction' score for every customer who paid with a credit card or used a loyalty card or mailed coupons. The correlations even let the retailer estimate the due date within a narrow range, so it could send relevant coupons for each stage of the pregnancy."
Harmless targeting, some might argue. But what happens, as has already reportedly occurred, when a father is mistakenly sent nappy discount vouchers instead of his teenage daughter whom a retailer has identified is pregnant before her own father knows?
Mayer-Schönberger's second example on the reliance upon algorithms throws up even more potential dilemmas and pitfalls: "Parole boards in more than half of all US states use predictions founded on data analysis as a factor in deciding whether to release somebody from prison or to keep him incarcerated.
Norah Jones: a specially developed algorithm predicted that her debut album contained a disproportionately high number of hit records. Photograph: Olycom SPA/Rex Features
Christopher Steiner, author of Automate This: How Algorithms Came to Rule Our World, has identified a wide range of instances where algorithms are being used to provide predictive insights – often within the creative industries. In his book, he tells the story of a website developer called Mike McCready, who has developed an algorithm to analyse and rate hit records. Using a technique called advanced spectral deconvolution, the algorithm breaks up each hit song into its component parts – melody, tempo, chord progression and so on – and then uses that to determine common characteristics across a range of No 1 records. McCready's algorithm correctly predicted – before they were even released – that the debut albums by both Norah Jones and Maroon 5 contained a disproportionately high number of hit records.
The next logical step – for profit-seeking record companies, perhaps – is to use algorithms to replace the human songwriter. But is that really an attractive proposition? "Algorithms are not yet writing pop music," says Steiner. He pauses, then laughs. "Not that we know of, anyway. If I were a record company executive or pop artist, I wouldn't tell anyone if I'd had a number one written by an algorithm."
Steiner argues that we should not automatically see algorithms as a malign influence on our lives, but we should debate their ubiquity and their wide range of uses. "We're already halfway towards a world where algorithms run nearly everything. As their power intensifies, wealth will concentrate towards them. They will ensure the 1%-99% divide gets larger. If you're not part of the class attached to algorithms, then you will struggle. The reason why there is no popular outrage about Wall Street being run by algorithms is because most people don't yet know or understand it."
But Steiner says we should welcome their use when they are used appropriately to aid and speed our lives. "Retail algorithms don't scare me," he says. "I find it useful when Amazon tells me what I might like. In the US, we know we will not have enough GP doctors in 15 years, as not enough are being trained. But algorithms can replace many of their tasks. Pharmacists are already seeing some of their prescribing tasks replaced by algorithms. Algorithms might actually start to create new, mundane jobs for humans. For example, algorithms will still need a human to collect blood and urine samples for them to analyse."
There can be a fine line, though, between "good" and "bad" algorithms, he adds: "I don't find the NSA revelations particularly scary. At the moment, they just hold the data. Even the best data scientists would struggle to know what to do with all that data. But it's the next step that we need to keep an eye on. They could really screw up someone's life with a false prediction about what they might be up to."
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.