Note: More than a year ago, I posted about this move by Alphabet-Google toward becoming city designers... I tried to point out the problems related to a company which business is to collect data becoming the main investor in public space and common goods (the city is still part of the commons, isn't it?) But of course, this is, again, about big business ("to make the world a better place" ... indeed) and slick ideas.
But it is highly problematic that a company start investing in public space "for free". We all know what this mean now, don't we? It is not needed and not desired.
So where are the "starchitects" now? What do they say? Not much... Where are all the "regular" architects as well? Almost invisible, tricked in the wrong stakes, with -- I'm sorry...-- very few of them being only able to identify the problem.
This is not about building a great building for a big brand or taking a conceptual position, not even about "die Gestalt" anymore. It is about everyday life for 66% of Earth population by 2050 (UN study). It is, in this precise case, about information technologies and mainly information stategies and businesses that materialize into structures of life.
fabric | rblg legend: this hand drawn image contains all the marketing clichés (green, blue, clean air, bikes, local market, public transportation, autonomous car in a happy village atmosphere... Can't be further from what it will be).
An 800-acre strip of Toronto's waterfront may show us how cities of the future could be built. Alphabet’s urban innovation team, Sidewalk Labs, has announced a plan to inject urban design and new technologies into the city's quayside to boost "sustainability, affordability, mobility, and economic opportunity."
Huh?
Picture streets filled with robo-taxis, autonomous trash collection, modular buildings, and clean power generation. The only snag may be the humans: as we’ve said in the past, people can do dumb things with smart cities. Perhaps Toronto will be different.
Note: following the two previous posts about algorythms and bots ("how do they ... ?), here comes a third one.
Slighty different and not really dedicated to bots per se, but which could be considered as related to "machinic intelligence" nonetheless. This time it concerns techniques and algoritms developed to understand the brain (BRAIN initiative, or in Europe the competing Blue Brain Project).
In a funny reversal, scientists applied techniques and algorythms developed to track human intelligence patterns based on data sets to the computer itself. How do a simple chip "compute information"? And the results are surprising: the computer doesn't understand how the computer "thinks" (or rather works in this case)!
This to confirm that the brain is certainly not a computer (made out of flesh)...
When you apply tools used to analyze the human brain to a computer chip that plays Donkey Kong, can they reveal how the hardware works?
Many research schemes, such as the U.S. government’s BRAIN initiative, are seeking to build huge and detailed data sets that describe how cells and neural circuits are assembled. The hope is that using algorithms to analyze the data will help scientists understand how the brain works.
But those kind of data sets don’t yet exist. So Eric Jonas of the University of California, Berkeley, and Konrad Kording from the Rehabilitation Institute of Chicago and Northwestern University wondered if they could use their analytical software to work out how a simpler system worked.
They settled on the iconic MOS 6502 microchip, which was found inside the Apple I, the Commodore 64, and the Atari Video Game System. Unlike the brain, this slab of silicon is built by humans and fully understood, down to the last transistor.
The researchers wanted to see how accurately their software could describe its activity. Their idea: have the chip run different games—including Donkey Kong, Space Invaders, and Pitfall, which have already been mastered by some AIs—and capture the behavior of every single transistor as it did so (creating about 1.5 GB per second of data in the process). Then they would turn their analytical tools loose on the data to see if they could explain how the microchip actually works.
For instance, they used algorithms that could probe the structure of the chip—essentially the electronic equivalent of a connectome of the brain—to establish the function of each area. While the analysis could determine that different transistors played different roles, the researchers write in PLOS Computational Biology, the results “still cannot get anywhere near an understanding of the way the processor really works.”
Elsewhere, Jonas and Kording removed a transistor from the microchip to find out what happened to the game it was running—analogous to so-called lesion studies where behavior is compared before and after the removal of part of the brain. While the removal of some transistors stopped the game from running, the analysis was unable to explain why that was the case.
In these and other analyses, the approaches provided interesting results—but not enough detail to confidently describe how the microchip worked. “While some of the results give interesting hints as to what might be going on,” explains Jonas, “the gulf between what constitutes ‘real understanding’ of the processor and what we can discover with these techniques was surprising.”
It’s worth noting that chips and brains are rather different: synapses work differently from logic gates, for instance, and the brain doesn’t distinguish between software and hardware like a computer. Still, the results do, according to the researchers, highlight some considerations for establishing brain understanding from huge, detailed data sets.
First, simply amassing a handful of high-quality data sets of the brains may not be enough for us to make sense of neural processes. Second, without many detailed data sets to analyze just yet, neuroscientists ought to remain aware that their tools may provide results that don’t fully describe the brain’s function.
As for the question of whether neuroscience can explain how an Atari works? At the moment, not really.
Note: let's "start" this new (delusional?) year with this short video about the ways "they" see things, and us. They? The "machines" of course, the bots, the algorithms...
An interesting reassembled trailer that was posted by Matthew Plummer-Fernandez on his Tumblr #algopop that documents the "appearance of algorithms in popular culture". Matthew was with us back in 2014, to collaborate on a research project at ECAL that will soon end btw and worked around this idea of bots in design.
Will this technological future become "delusional" as well, if we don't care enough? As essayist Eric Sadin points it in his recent book, "La silicolonisation du monde" (in French only at this time)?
Possibly... It is with no doubt up to each of us (to act), so as regarding our everyday life in common with our fellow human beings!
Everything but the detected objects are removed from the trailer of The Wolf of Wall Street. The software is powered by Yolo object-detection, which has been used for similar experiments.
Note: I'll be pleased to be in Paris next Friday and Saturday (02-03.12) at the Centre Culturel Suisse and in the company of an excellent line up (!Mediengruppe Bitnik, Nicolas Nova, Yves Citton, Tobias Revell & Nathalie Kane, Rybn, Joël Vacheron and many others) for the conference and event "Bot Like Me" curated by Sophie Lamparter and Luc Meier.
A l’occasion de l’exposition de !MedienGruppe Bitnik, et avec la complicité du duo d’artistes zurichois, Sophie Lamparter (directrice associée de swissnex San Francisco) et Luc Meier (directeur des contenus de l’EPFL ArtLab, Lausanne) ont concocté pour le CCS un événement de deux jours composé de conférences, tables rondes et concerts, réunissant scientifiques, artistes, écrivains, journalistes et musiciens pour examiner les dynamiques tourmentées des liens homme-machine. Conçues comme une plateforme d’échange à configuration souple, ces soirées interrogeront nos rapports complexes, à la fois familiers et malaisés, avec les bots qui se multiplient dans nos environnements ultra-connectés.
Vendredi 2 décembre / dès 19h30
conférence, 19h30-21h : Bot Like Me kick-off
avec Rolf Pfeifer (AI Lab de l’Université de Zurich / Osaka University), Carmen Weisskopf et Domagoj Smoljo ( !Mediengruppe Bitnik). Modération : Luc Meier et Sophie Lamparter
performance musicale live, 21h30 : Not Waving
Samedi 3 décembre / dès 14h30
tables rondes
-14h30-16h : Data Manifestos
avec Hannes Grassegger (auteur de Das Kapital bin ich), Hannes Gassert (Open Knowledge Network) et le collectif RYBN. Modération : Sophie Lamparter et Luc Meier
-16h30-18h : Cloud Labor, Petty Bot Jobs
avec Nicolas Nova (HEAD-Genève, Near Future Laboratory), Yves Citton (Université de Grenoble) et Patrick Keller (ECAL, fabric | ch). Modération : Marie Lechner
-18h30-20h : Botocene & Algoghosts
avec Tobias Revell et Natalie Kane (Haunted Machines), Gwenola Wagon et Jeff Guess (artistes). Modération : Joël Vacheron et Nicolas Nova
concert 21h : performance live de Low Jack et carte blanche au label Antinote
In particular, in the frame of this research project, as a source of critical inspiration for a workshop we were preparing to lead with students at that time (critical because "magic" in the context of technology means what it means: tricked and not understanding, therefore believing or "stupefied").
For the matter of documentation, I reblog this post as well on | rblg as it brings different ideas about the "sublime" related to data or data centers, creation and contemporary technology in general.
It may be a bit hard to follow without the initial context (a brief by the invited guests, Random International and the general objectives of the project), but this context can be accessed from within the post -below-, for the ones interested to digg deeper.
...
As a matter of fact, this whole topic make me also think of the film The Prestige by Christopher Nolan. In which the figure of Nikola Tesla (played by "The Man Who Fell to Earth himself, a.k.a. David Bowie) is depicted as a character very close to a magician, his inventions with electricity being understood at the margin between sciences and magic.
Following the publication of Dev Joshi‘s brief on I&IC documentary blog yesterday (note: 10.11.2015), I took today the opportunity to briefly introduce it to the interaction design students that will be involved in the workshop next week. Especially, I focused on some points of the brief that were important but possibly quite new concepts for them. I also extended some implicit ideas with images that could obviously bring ideas about devices to build to access some past data, or “shadows” as Dev’s names them.
What comes out in a very interesting way for our research in Dev’s brief is the idea that the data footprints each of us leaves online on a daily basis (while using all type of digital services) could be considered as past entities of ourselves, or trapped, forgotten, hidden, … (online) fragments of our personalities… waiting to be contacted again.
How many different versions of you are there in the cloud? If they could speak, what would they say?
Yet, interestingly, if the term “digital footprint” is generally used in English to depict this situation (the data traces each of us leaves behind), we rather use in French the term “ombre numérique” (literally “digital shadow”). That’s why we’ve decided with Dev that it was preferable to use this term as the title for the workshop (The Everlasting Shadows): it is somehow a more vivid expression that could bring quite direct ideas when it comes to think about designing “devices” to “contact” these “digital entities” or make them visible again in some ways.
Philippe Ramette, “L’ombre de celui que j’étais / Shadow of my former self “, 2007. Light installation, mixed media.
By extension, we could also start to speak about “digital ghosts” as this expression is also commonly used (not to mention the “corps sans organes” of G. Deleuze/F. Gattari and previously A. Artaud). Many “ghosts”/facets of ourselves? All trapped online in the form of zombie data?
Your digital ghosts are trapped on islands around the cloud – is there a way to rescue them? Maybe they just need a shelter to live in now that you have moved on?
… or a haunted house?
And this again is a revealing parallel, because it opens the whole conceptual idea to beliefs… (about ghosts? about personal traces and shadows? about clouds? and finally, about technology? …)
What about then to work with inspirations that would come from the spiritualism domain, its rich iconography and produce “devices” to communicate with your dead past data entities?
Fritz Lang. “Dr. Mabuse, the Gambler”, movie, 1922.
Or even start to think about some kind of “wearables”, and then become a new type of fraud technological data psychic?
Fraud medium Colin Evans in levitation, 13 June 1938 (source Wikipedia).
We could even digg deeper into these “beliefs” and start looking at old illustrations and engravings that depicts relations to “things that we don’t understand”, that are “beyond our understanding”… and that possibly show “tools” or strange machinery to observe or communicate with these “unknown things” (while trying to understand them)?
This last illustration could also drive us, by extension and a very straight shortcut , to the idea of the Sublime (in art, but also in philosophy), especially the romantic works of the painters from that period (late 18th and early 19th centuries, among them W. Turner, C. S. Friedrich, E. Delacroix, T. Cole, etc.)
Submerged by the presentiment of a nature that was in all dimensions dominating humans, that remained at that time mostly unexplained and mysterious, if not dangerous and feared, some painters took on this feeling, named “sublime” after Edmund Burke’s Philosophical Enquiry (1757), and start painting dramatic scenes of humans facing the forces of nature.
Thomas Cole, “The Voyage of Life: Old Age”, 1842. National Gallery of Art, Washington DC.
It is not by chance of course that I’ll end my “esoteric comments about the brief” post with this idea of the Sublime. This is because recently, the concept found a new life in regard to technology and its central yet “unexplained, mysterious, if not dangerous and feared” role in our contemporary society. The term got completed at this occasion to become the “Technological Sublime”, thus implicitly comparing the once dominant and “beyond our understanding” Nature to our contemporary technology.
“American Technological Sublime” by D. E. Nye, published in 1994 (MIT Press) was certainly one of the first book to join the two terms. It continues the exploration of the social construction of technology initiated in his previous book, “Electrifying America” (MIT Press, 1990). More recently in 2011, the idea popup again on the blog of Next Nature in an article simply entitled The Technological Sublime.
So, to complete my post with a last question, is the Cloud, that everybody uses but nobody seems to understand, a technologically sublime artifact? Wouldn’ it be ironic that an infrastructure, which aim is to be absolutely rational and functional, ultimately contributes to creates a completely opposite feeling?
Note: published a little while ago, this article from Time magazine ("The Next Revolution in Photography Is Coming") makes a fascinating point about the changing nature of photography. Even so the article mostly talks about journalism photography.
An interesting analysis by Stephen Mayes that shows how far photography is becoming data capture (sensing)... as much --or even more-- as it is visual capture. We should certainly discuss further around this question with the scientists that are writing the algorithms of photography. Yet as stated in the paper, a camera is slowly becoming primarily a "data-collecting device" and the image reconstructed from these data (by algorithms then) a last "grip on the belief in the image as an objective record".
This comes in resonance with our scholar understanding of photography as the media that was once believed or phantasized of being able to "capture reality", as it is. The early cinema carried later the same kind of beliefs. And we could then think again about this fantastic novel by Adolfo Bioy Casares (The Invention of Morel, 1940) that was extrapolating around these myths (of being able to fully record and register the "present", then replay it, entirely).
Today, this belief in our ability to "fully record the real" or digg into its recorded past (some big data projects) has a tendency to be transferred into data capture (and I obviously publish this post on purpose just after the presentation of an architecture project by fabric | ch that largely used and played around this idea of recording the present and that followed an installation around the same idea, through data).
So the connection that is made in this paper between photography and data capture is full of epistemological interests!
In the future, there will be no such thing as a "straight photograph"
It’s time to stop talking about photography. It’s not that photography is dead as many have claimed, but it’s gone.
Just as there’s a time to stop talking about girls and boys and to talk instead about women and men so it is with photography; something has changed so radically that we need to talk about it differently, think of it differently and use it differently. Failure to recognize the huge changes underway is to risk isolating ourselves in an historical backwater of communication, using an interesting but quaint visual language removed from the cultural mainstream.
The moment of photography’s “puberty” was around the time when the technology moved from analog to digital although it wasn’t until the arrival of the Internet-enabled smartphone that we really noticed a different behavior. That’s when adolescence truly set in. It was surprising but it all seemed somewhat natural and although we experienced a few tantrums along the way with arguments about promiscuity, manipulation and some inexplicable new behaviors, the photographic community largely accommodated the changes with some adjustments in workflow.
But these visible changes were merely the advance indicators of deeper transformations and it was only a matter of time before people’s imagination reached beyond the constraints of two dimensions to explore previously unimagined possibilities. And so it is that we find ourselves in a world where the digital image is almost infinitely flexible, a vessel for immeasurable volumes of information, operating in multiple dimensions and integrated into apps and technologies with purposes yet to be imagined.
Digital capture quietly but definitively severed the optical connection with reality, that physical relationship between the object photographed and the image that differentiated lens-made imagery and defined our understanding of photography for 160 years. The digital sensor replaced to optical record of light with a computational process that substitutes a calculated reconstruction using only one third of the available photons. That’s right, two thirds of the digital image is interpolated by the processor in the conversion from RAW to JPG or TIF. It’s reality but not as we know it.
For obvious commercial reasons camera manufacturers are careful to reconstruct the digital image in a form that mimics the familiar old photograph and consumers barely noticed a difference in the resulting image, but there are very few limitations on how the RAW data could be handled and reality could be reconstructed in any number of ways. For as long as there’s an approximate consensus on what reality should look like we retain a fingernail grip on the belief in the image as an objective record. But forces beyond photography and traditional publishing are already onto this new data resource, and culture will move with it whether photographers choose to follow or not.
As David Campbell has pointed out in his report on image integrity for the World Press Photo, this requires a profound reassessment of words like “manipulation” that assume the existence of a virginal image file that hasn’t already been touched by computational process. Veteran digital commentator Kevin Connor says, “The definition of computational photography is still evolving, but I like to think of it as a shift from using a camera as a picture-making device to using it as a data-collecting device.”
The differences contained in the structure and processing of a digital file are not the end of the story of photography’s transition from innocent childhood to knowing adulthood. There is so much more to grasp that very few people have yet grappled with the inevitable but as yet unimaginable impact on the photographic image. Taylor Davidson has described the camera of the future as an app, a software rather than a device that compiles data from multiple sensors. The smartphone’s microphone, gyroscope, accelerometer, thermometer and other sensors all contribute data as needed by whatever app calls on it and combines it with the visual data. And still that’s not the limit on what is already bundled with our digital imagery.
Our instruments are connected to satellites that contribute GPS data while connecting us to the Internet that links our data to all the publicly available information of Wikipedia, Google and countless other resources that know where we are, who was there before us and the associated economic, social and political activity. Layer on top of that the integration of LIDAR data (currently only in some specialist apps) then apply facial and object recognition software and consider the implication of emerging technologies such as virtual reality, semantic reality and artificial intelligence and one begins to realize the mind-boggling potential of computational imagery.
Things will go even further with the development of curved sensors that will allow completely different ways to interpret light, but that for the moment remains an idea rather than a reality. Everything else is already happening and will become increasingly evident as new technologies roll out, ushering us into a very different visual culture with expectations far beyond simple documentation.
Computational photography draws on all these resources and allows the visual image to create a picture of reality that is infinitely richer than a simple visual record, and with this comes the opportunity to incorporate deeper levels of knowledge. It won’t be long before photographers are making images of what they know, rather than only what they see. Mark Levoy, formerly of Stanford and now of Google puts it this way, “Except in photojournalism, there will be no such thing as a ‘straight photograph’; everything will be an amalgam, an interpretation, an enhancement or a variation – either by the photographer as auteur or by the camera itself.”
As we tumble forwards into these unknown territories there’s a curious throwback to a moment in art history when 100 years ago the Cubists revolutionized ways of seeing using a very similar (albeit analog) approach to what they saw. Picasso, Braque and others deconstructed the world and reassembled it not in terms of what they saw, but rather in terms of what they knew using multiple perspectives to depict a deeper understanding.
While the photographic world wrestles with even such basic tools as Photoshop there is no doubt that we’re moving into a space more aligned with Cubism than Modernism. It will not be long before our audiences demand more sophisticated imagery that is dynamic and responsive to change, connected to reality by more than a static two-dimensional rectangle of crude visual data isolated in space and time. We’ll look back at the black-and-white photograph that was the voice of truth for nearly a century, as a simplistic and incomplete source of information about what was happening in the world.
Some will consider this a threat, seeing only the danger of distortion and undetectable fakery and it’s certainly true that we’ll need to develop new measures by which to read imagery. We’re already highly skilled in distinguishing probable and improbable information and we know how to read written journalism (which is driven entirely by the writer’s imaginative ability to interpret reality in symbolic form) and we don’t confuse advertising imagery with documentary, nor the photo illustration on a magazine’s cover with the reportage inside. Fraud will always be a risk but with over a century of experience we’ve learned that we can’t rely on the mechanical process to protect us. New conventions will emerge and all the artistry that’s been developed since the invention of photography will find richer and deeper opportunities to express information, ideas and emotions with no greater risk to truth than we currently experience. The enriched opportunities for storytelling will allow greater complexity that’s closer to reality than the thinned-down simplification of 20th Century journalism and will open unprecedented connection between the subject and the viewer.
The twist is that new forces will be driving the process. The clue is in what already occurred with the smartphone. The revolutionary change in photography’s cultural presence wasn’t led by photographers, nor publishers or camera manufacturers but by telephone engineers, and this process will repeat as business grasps the opportunities offered by new technology to use visual imagery in extraordinary new ways, throwing us into new and wild territory. It’s happening already and we’ll see the impact again and again as new apps, products and services hit the market.
We owe it to the medium that we’ve nurtured into adolescence to stand by it and support it in adulthood even though it might seem unrecognizable in its new form. We know the alternative: it will be out the door and hanging with the wrong crowd while we sit forlornly in the empty nest wondering what we did wrong. The first step is to stop talking about the child it once was and to put away the sentimental memories of photography as we knew it for all these years.
It’s very far from dead but it’s definitely left the building.
Note: in the continuity of my previous post/documentation concerning the project Platform of Future-Past (fabric | ch's recent winning competition proposal), I publish additional images (several) and explanations about the second phase of the Platform project, for which we were mandated by Canton de Vaud (SiPAL).
The first part of this article gives complementary explanations about the project, but I also take the opportunity to post related works and researches we've done in parallel about particular implications of the platform proposal. This will hopefully bring a neater understanding to the way we try to combine experimentations-exhibitions, the creation of "tools" and the design of larger proposals in our open and process of work.
Notably, these related works concerned the approach to data, the breaking of the environment into computable elements and the inevitable questions raised by their uses as part of a public architecture project.
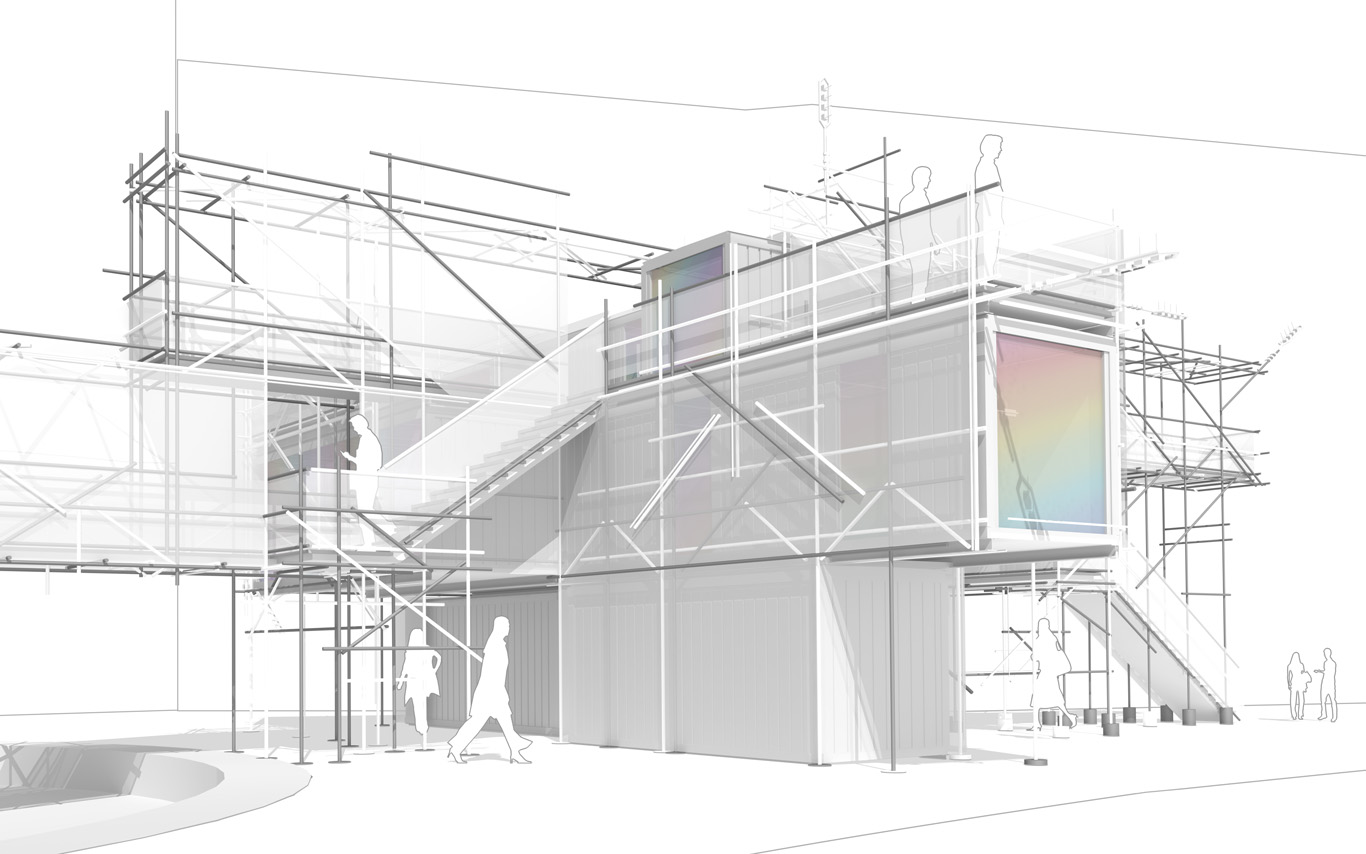
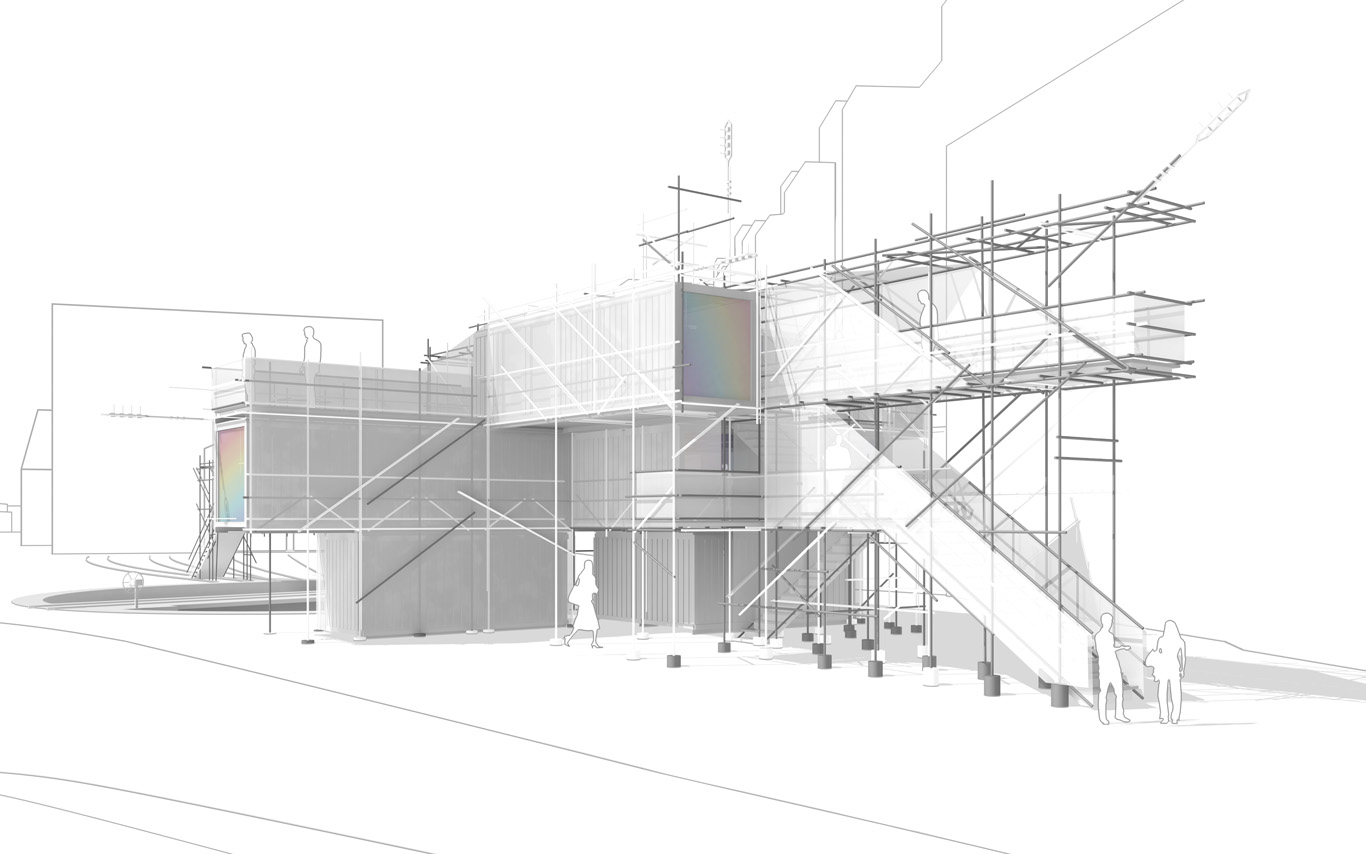
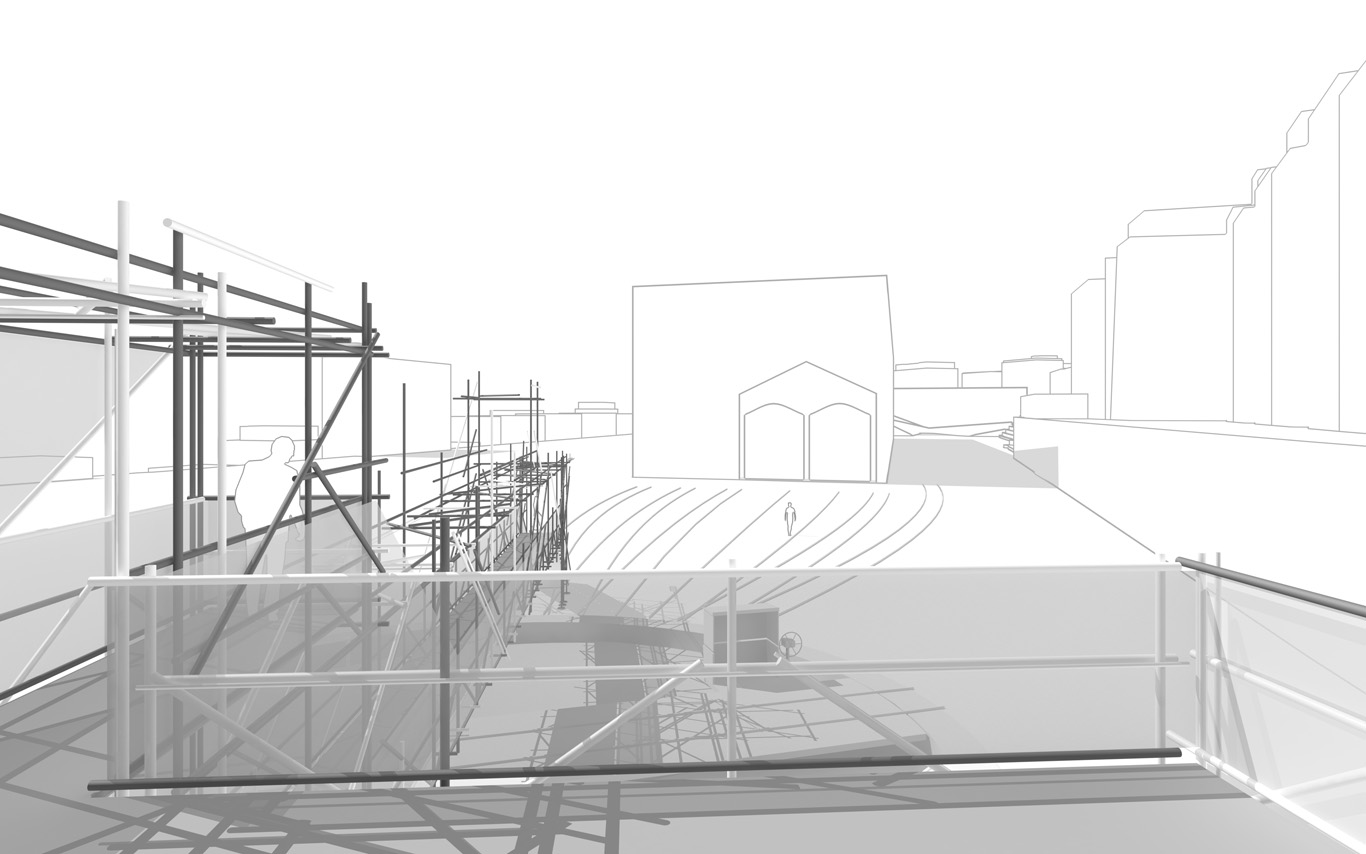
The information pavilion was potentially a slow, analog and digital "shape/experience shifter", as it was planned to be built in several succeeding steps over the years and possibly "reconfigure" to sense and look at its transforming surroundings.
The pavilion conserved therefore an unfinished flavour as part of its DNA, inspired by these old kind of meshed constructions (bamboo scaffoldings), almost sketched. This principle of construction was used to help "shift" if/when necessary.
In a general sense, the pavilion answered the conventional public program of an observation deck about a construction site. It also served the purpose of documenting the ongoing building process that often comes along. By doing so, we turned the "monitoring dimension" (production of data) of such a program into a base element of our proposal. That's where a former experimental installation helped us: Heterochrony.
As it can be noticed, the word "Public" was added to the title of the project between the two phases, to become Public Platform of Future-Past (PPoFP) ... which we believe was important to add. This because it was envisioned that the PPoFP would monitor and use environmental data concerning the direct surroundings of the information pavilion (but NO DATA about uses/users). Data that we stated in this case Public, while the treatment of the monitored data would also become part of the project, "architectural" (more below about it).
For these monitored data to stay public, so as for the space of the pavilion itself that would be part of the public domain and physically extends it, we had to ensure that these data wouldn't be used by a third party private service. We were in need to keep an eye on the algorithms that would treat the spatial data. Or best, write them according to our design goals (more about it below).
That's were architecture meets code and data (again) obviously...
The Public Platform of Future-Past is a structure (an information and sightseeing pavilion), a Platform that overlooks an existing Public site while basically taking it as it is, in a similar way to an archeological platform over an excavation site.
The asphalt ground floor remains virtually untouched, with traces of former uses kept as they are, some quite old (a train platform linked to an early XXth century locomotives hall), some less (painted parking spaces). The surrounding environment will move and change consideralby over the years while new constructions will go on. The pavilion will monitor and document these changes. Therefore the last part of its name: "Future-Past".
By nonetheless touching the site in a few points, the pavilion slightly reorganizes the area and triggers spaces for a small new outdoor cafe and a bikes parking area. This enhanced ground floor program can work by itself, seperated from the upper floors.
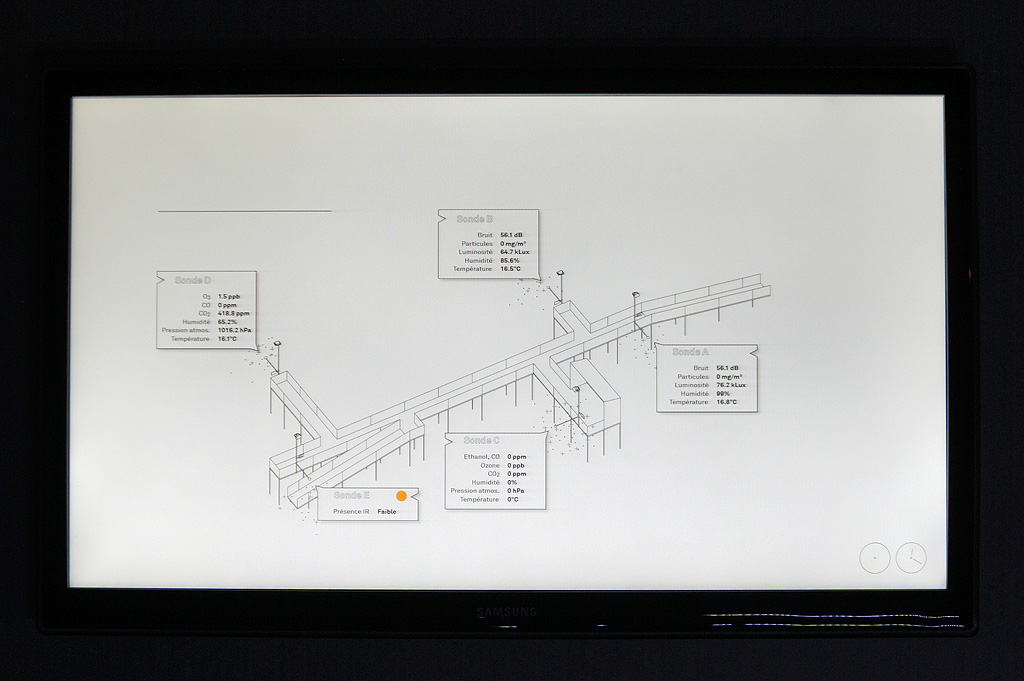
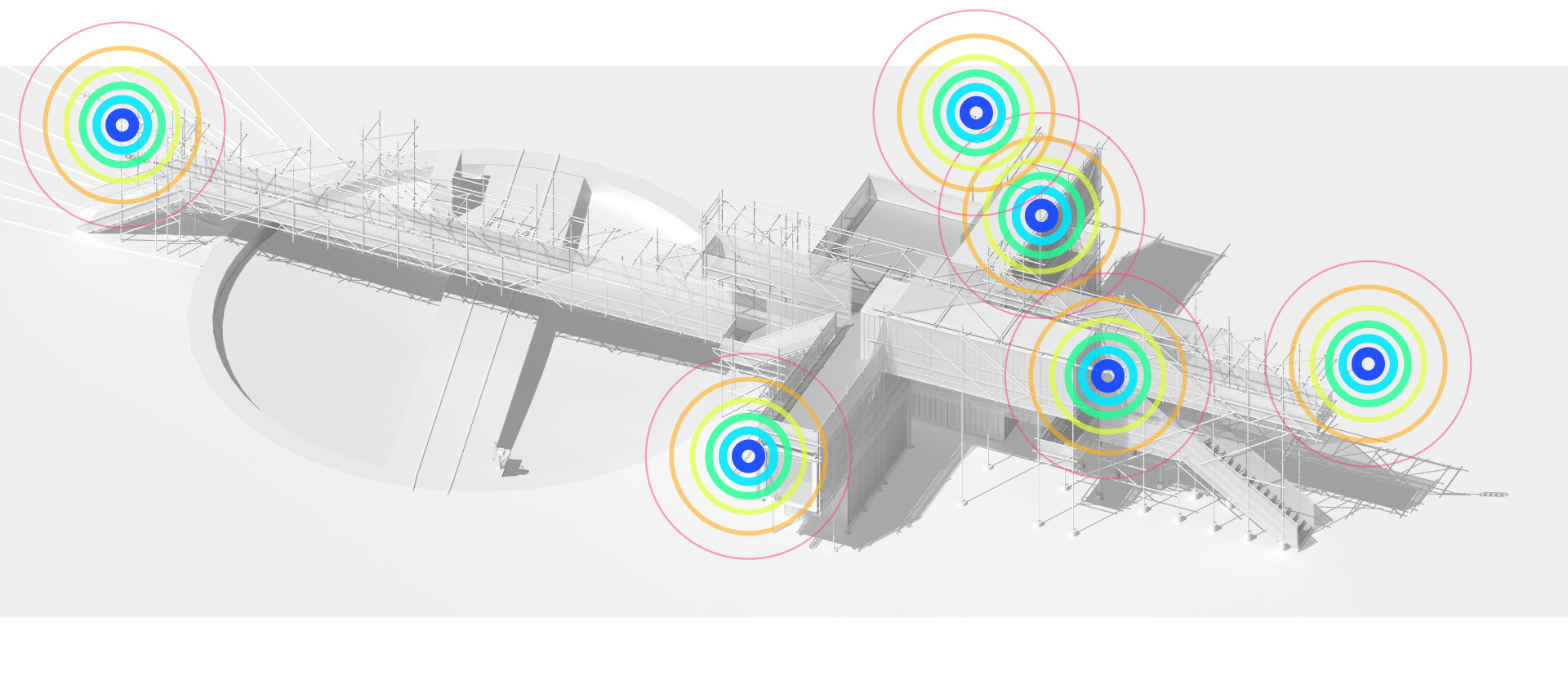
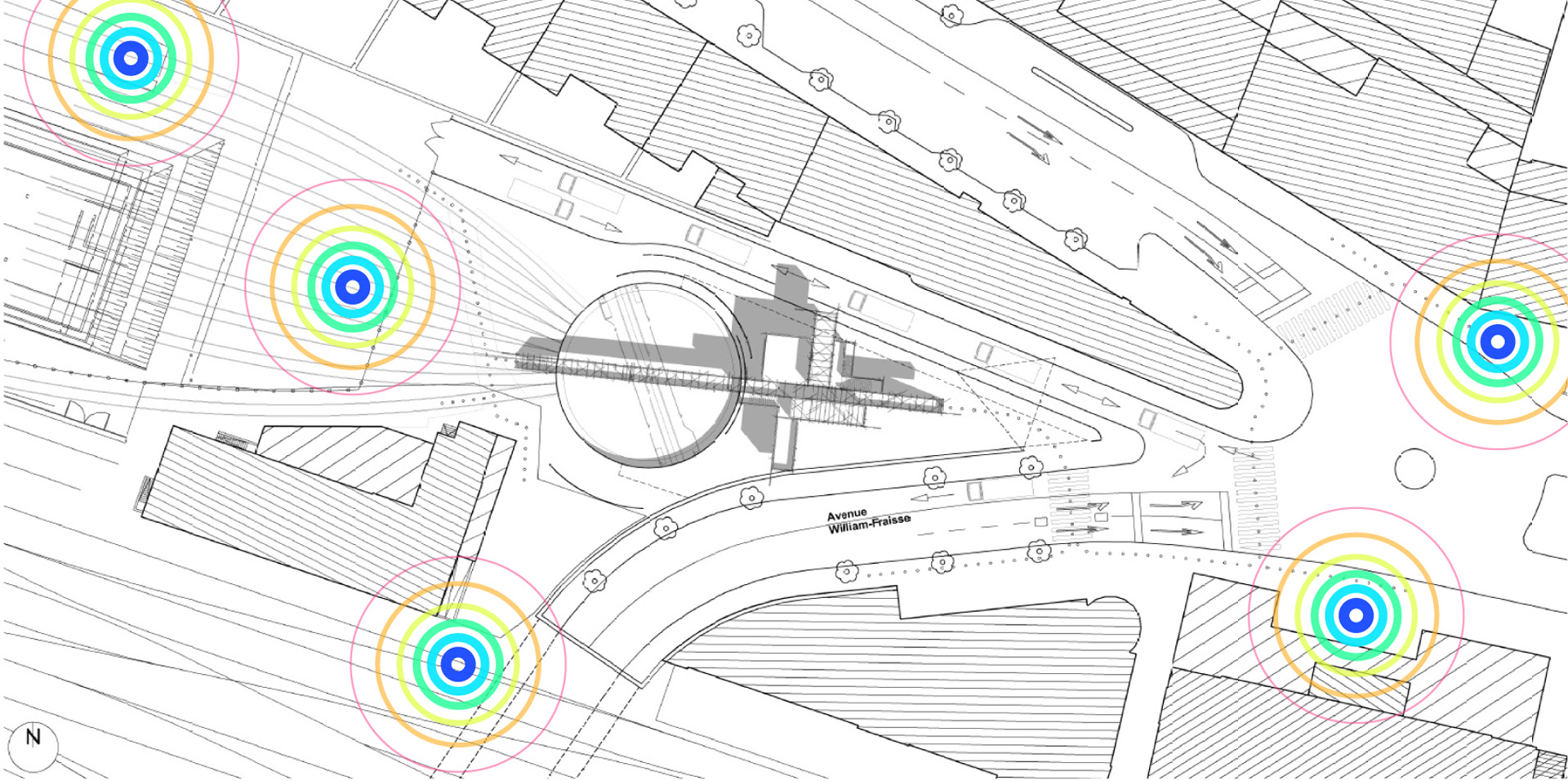
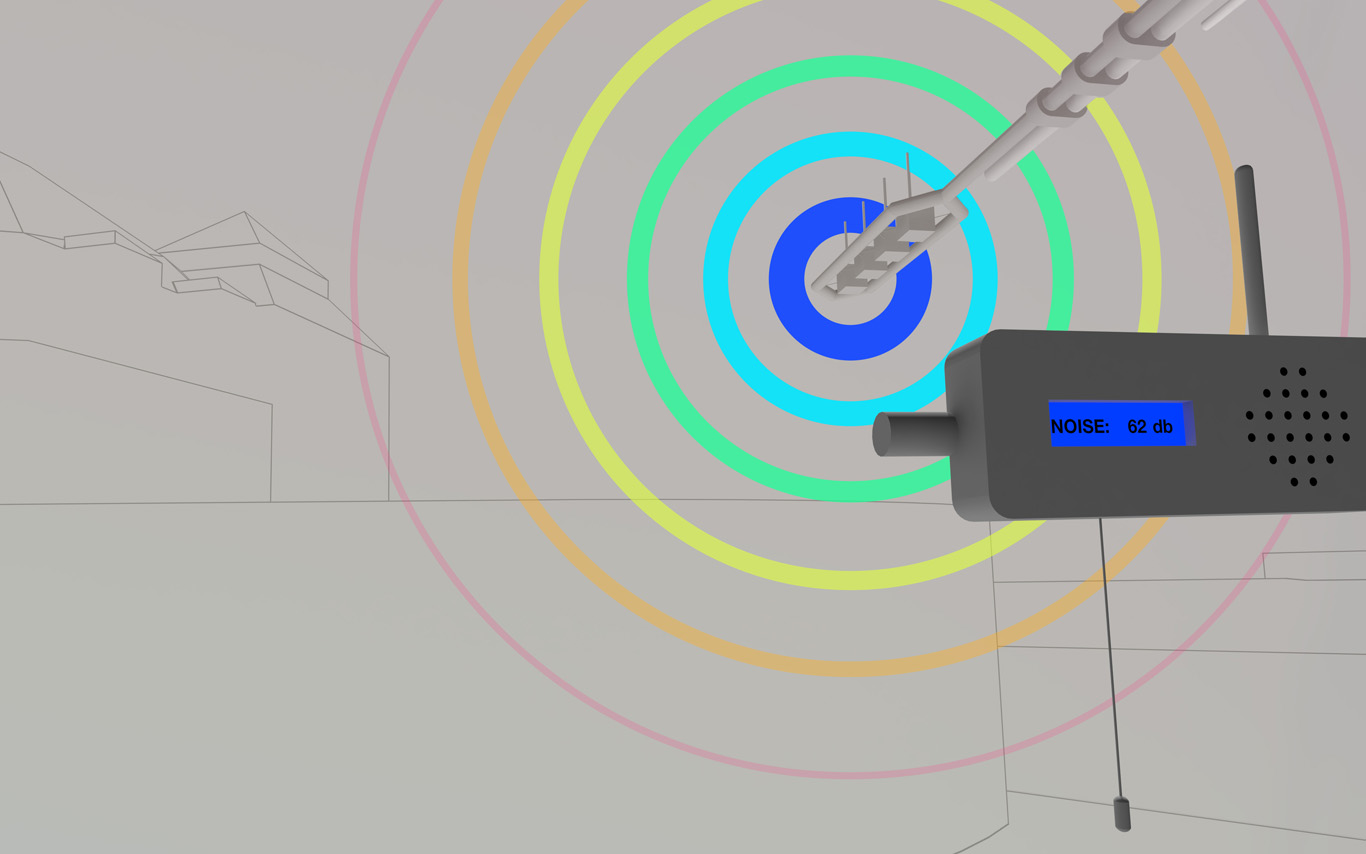
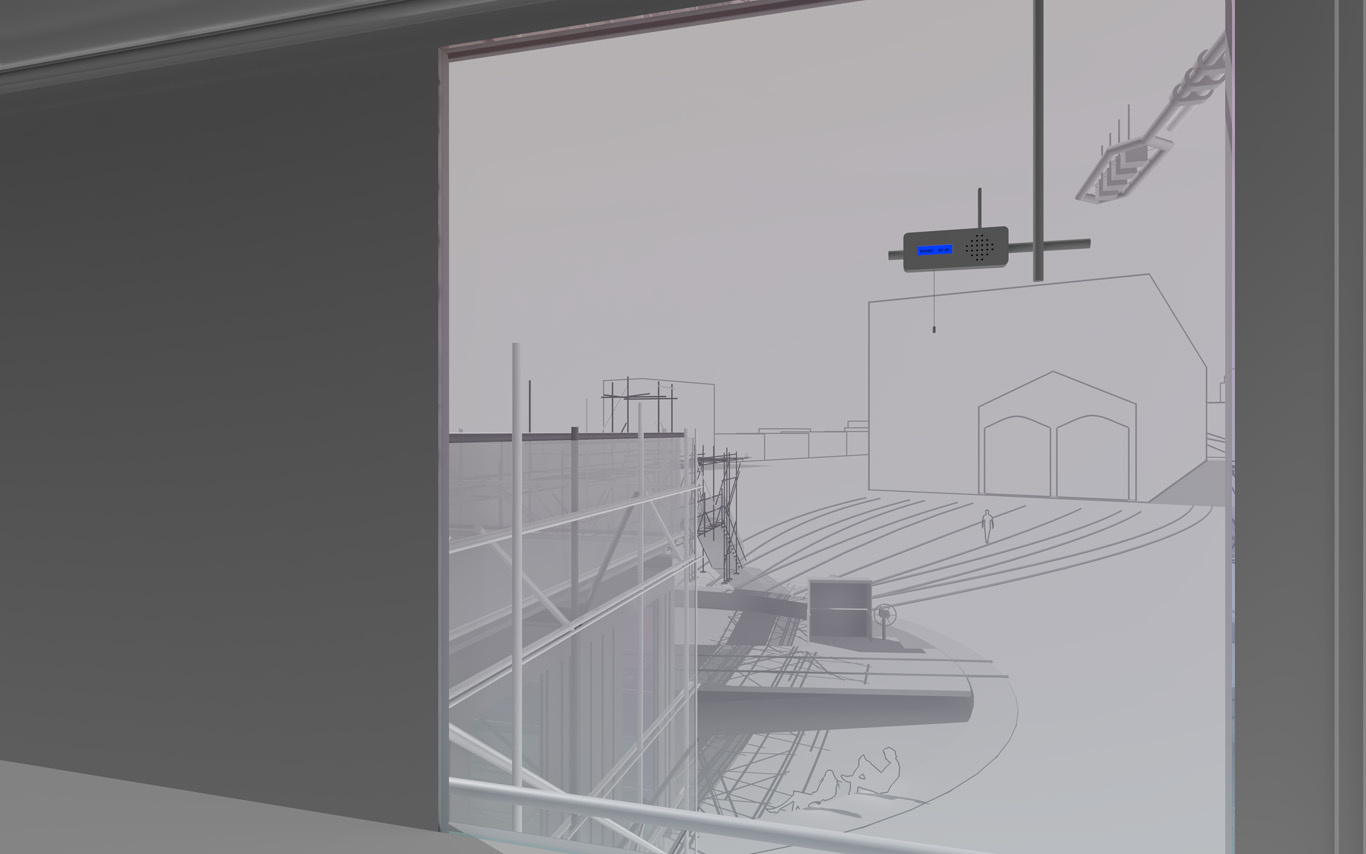
Several areas are linked to monitoring activities (input devices) and/or displays (in red, top -- that concern interests points and views from the platform or elsewhere --). These areas consist in localized devices on the platform itself (5 locations), satellite ones directly implented in the three construction sites or even in distant cities of the larger political area --these are rather output devices-- concerned by the new constructions (three museums, two new large public squares, a new railway station and a new metro). Inspired by the prior similar installation in a public park during a festival -- Heterochrony (bottom image) --, these raw data can be of different nature: visual, audio, integers from sensors (%, °C, ppm, db, lm, mb, etc.), ...
Input and output devices remain low-cost and simple in their expression: several input devices / sensors are placed outside of the pavilion in the structural elements and point toward areas of interest (construction sites or more specific parts of them). Directly in relation with these sensors and the sightseeing spots but on the inside are placed output devices with their recognizable blue screens. These are mainly voice interfaces: voice outputs driven by one bot according to architectural "scores" or algorithmic rules (middle image). Once the rules designed, the "architectural system" runs on its own. That's why we've also named the system based on automated bots "Ar.I." It could stand for "Architectural Intelligence", as it is entirely part of the architectural project.
The coding of the "Ar.I." and use of data has the potential to easily become something more experimental, transformative and performative along the life of PPoFT.
Observers (users) and their natural "curiosity" play a central role: preliminary observations and monitorings are indeed the ones produced in an analog way by them (eyes and ears), in each of the 5 interesting points and through their wanderings. Extending this natural interest is a simple cord in front of each "output device" that they can pull on, which will then trigger a set of new measures by all the related sensors on the outside. This set new data enter the database and become readable by the "Ar.I."
The whole part of the project regarding interaction and data treatments has been subject to a dedicated short study (a document about this study can be accessed here --in French only--). The main design implications of it are that the "Ar.I." takes part in the process of "filtering" which happens between the "outside" and the "inside", by taking part to the creation of a variable but specific "inside atmosphere" ("artificial artificial", as the outside is artificial as well since the anthropocene, isn't it ?) By doing so, the "Ar.I." bot fully takes its own part to the architecture main program: triggering the perception of an inside, proposing patterns of occupations.
"Ar.I." computes spatial elements and mixes times. It can organize configurations for the pavilion (data, displays, recorded sounds, lightings, clocks). It can set it to a past, a present, but also a future estimated disposition. "Ar.I." is mainly a set of open rules and a vocal interface, at the exception of the common access and conference space equipped with visual displays as well. "Ar.I." simply spells data at some times while at other, more intriguingly, it starts give "spatial advices" about the environment data configuration.
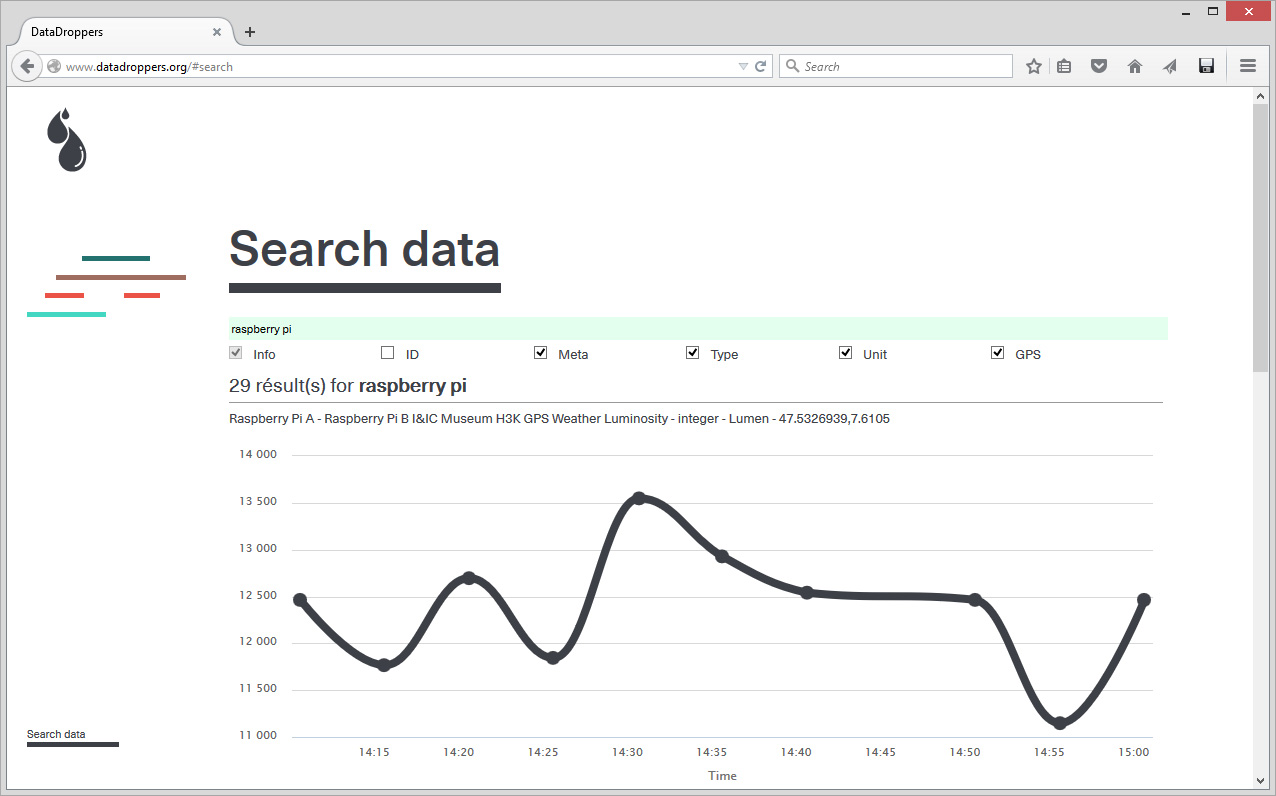
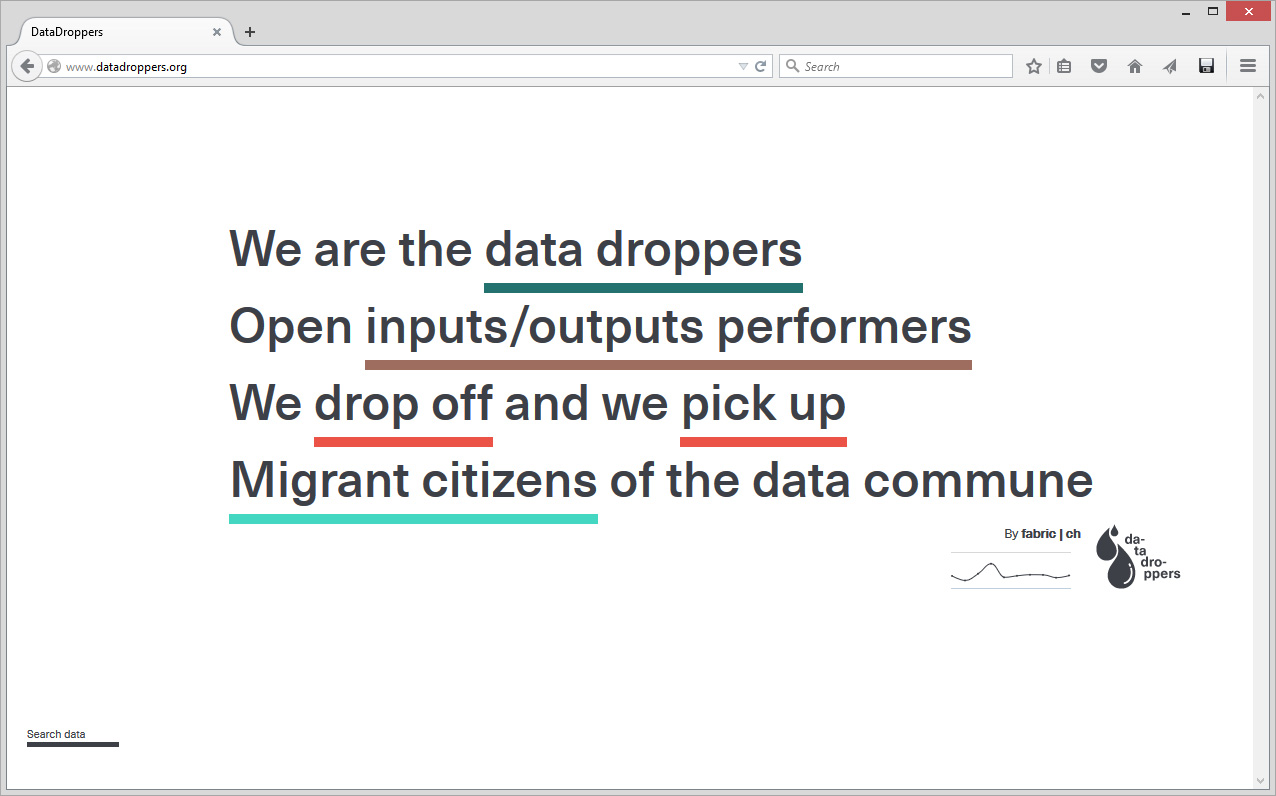
In parallel to Public Platform of Future Past and in the frame of various research or experimental projects, scientists and designers at fabric | ch have been working to set up their own platform for declaring and retrieving data (more about this project, Datadroppers, here). A platform, simple but that is adequate to our needs, on which we can develop as desired and where we know what is happening to the data. To further guarantee the nature of the project, a "data commune" was created out of it and we plan to further release the code on Github.
In tis context, we are turning as well our own office into a test tube for various monitoring systems, so that we can assess the reliability and handling of different systems. It is then the occasion to further "hack" some basic domestic equipments and turn them into sensors, try new functions as well, with the help of our 3d printer in tis case (middle image). Again, this experimental activity is turned into a side project, Studio Station (ongoing, with Pierre-Xavier Puissant), while keeping the general background goal of "concept-proofing" the different elements of the main project.
A common room (conference room) in the pavilion hosts and displays the various data. 5 small screen devices, 5 voice interfaces controlled for the 5 areas of interests and a semi-transparent data screen. Inspired again by what was experimented and realized back in 2012 during Heterochrony (top image).
----- ----- -----
PPoFP, several images. Day, night configurations & few comments
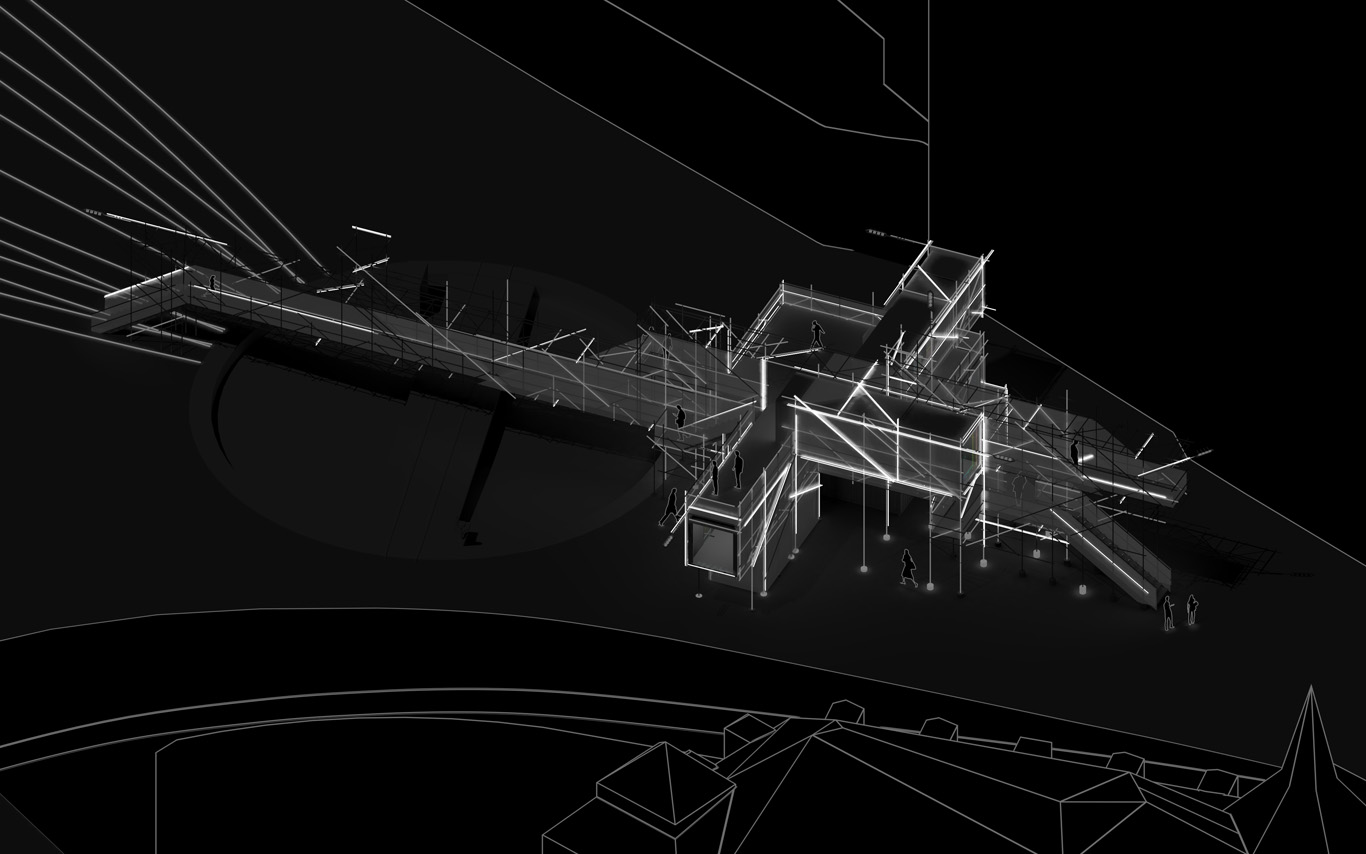
Public Platform of Future-Past, axonometric views day/night.
An elevated walkway that overlook the almost archeological site (past-present-future). The circulations and views define and articulate the architecture and the five main "points of interests". These mains points concentrates spatial events, infrastructures and monitoring technologies. Layer by layer, the suroundings are getting filtrated by various means and become enclosed spaces.
Walks, views over transforming sites, ...
Data treatment, bots, voice and minimal visual outputs.
Night views, circulations, points of view.
Night views, ground.
Random yet controllable lights at night. Underlined areas of interests, points of "spatial densities".
Note: we've been working recently at fabric | ch on a project that we couldn't publish or talk about for contractual reasons... It concerned a relatively large information pavilion we had to create for three new museums in Switzerland (in Lausanne) and a renewed public space (railway station square). This pavilion was supposed to last for a decade, or a bit longer. The process was challenging, the work was good (we believed), but it finally didn't get build...
Sounds sad but common isn't it?
...
We'll see where these many "..." will lead us, but in the meantime and as a matter of documentation, let's stick to the interesting part and publish a first report about this project.
It consisted in an evolution of a prior spatial installation entitled Heterochrony (pdf). A second post will follow soon with the developments of this competition proposal. Both posts will show how we try to combine small size experiments (exhibitions) with more permanent ones (architecture) in our work. It also marks as well our desire at fabric | ch to confront more regularly our ideas and researches with architectural programs.
On the jury paper was written, under "price" -- as we didn't get paid for the 1st price itself -- : "Réalisation" (realization).
Just below in the same letter, "according to point 1.5 of the competition", no realization will be attributed... How ironic! We did work further on an extended study though.
A few words about the project taken from its presentation:
" (...) This platform with physically moving parts could almost be considered an archaeological footbridge or an unknown scientific device, reconfigurable and shiftable, overlooking and giving to see some past industrial remains, allowing to document the present, making foresee the future.
The pavilion, or rather pavilions, equipped with numerous sensor systems, could equally be considered an "architecture of documentation" and interaction, in the sense that there will be extensive data collected to inform in an open and fluid manner over the continuous changes on the sites of construction and tranformations. Taken from the various "points of interets' on the platform, these data will feed back applications ("architectural intelligence"?), media objects, spatial and lighting behaviors. The ensemble will play with the idea of a combination of various time frames and will combine the existing, the imagined and the evanescent. (...) "
Note: after a few weeks posting about the Universal Income, here comes the "Universal data accumulator for devices, sensors, programs, humans & more" by Wolfram (best known for Wolfram Alpha computational engine and the former Mathematica libraries, on which most of their other services seem to be built).
Funilly, we've picked a very similar name for a very similar data service we've set up for ourselves and our friends last year, during an exhibition at H3K: Datadroppers (!), with a different set of references in our mind (Drop City? --from which we borrowed the colors-- "Turn on, tune in, drop out"?) Even if our service is logically much more grassroots, less developed but therfore quite light to use as well.
We developed this project around data dropping/picking with another architectural project in mind that I'll speak about in the coming days: Public Platform of Future-Past. It was clearly and closely linked.
"Universal" is back in the loop as a keyword therefore... (I would rather adopt a different word for myself and the work we are doing though: "Diversal" --which is a word I'm using for 2 yearnow and naively thought I "invented", but not...)
"The Wolfram Data Drop is an open service that makes it easy to accumulate data of any kind, from anywhere—setting it up for immediate computation, visualization, analysis, querying, or other operations." - which looks more oriented towards data analysis than use in third party designs and projects.
"Datadroppers is a public and open data commune, it is a tool dedicated to data collection and sharing that tries to remain as simple, minimal and easy to use as possible." Direct and light data tool for designers, belonging to designers (fabric | ch) that use it for their own projects...
Note: "(...) For example, technologists might be held responsible if they use poor quality data to train AI systems, or fossilize prejudices based on race, age, or gender into the algorithms they design."
Mind your data and the ones you'll use to "fossilize", so to say (and as long as you'll already know what's in your data)... It is then no more about "if" you're collecting data, but "which" data you'll use to feed your AIs, and "how". Now that we clearly see that large corporations plan to use more and more of these kind of techs to also drive "domestic" applications (and by extension as we already know "personal" applications of all sorts), it will be important to understand the stakes behind them as it will become part of our social and design context.
An important problem that I can see for designers and architects is that if you don't agree with the principles --commercial, social, ethical and almost conceptual-- implied by the technologies (i.e. any "homekit" like platforms controlled by bots), you won't find many if any counter propositions/techs to work with (all large diffusion products will support iOS, Android and the likes). It is almost a dictatorship of products hidden behind a "participate" paradigma. Either you'll be in and accept the conditions (you might use an API provided with the service --FB, Twitter, IFTTT, Apple, Google, Wolfram, Siemens, MS, etc.--, but then feed the central company nonetheless), or out... or possibly develop you own solution(s) that will probably be a pain in the ass to use for your client because it/they will clearly be side products hard to maintain, update, etc.
"Some" open source projects driven by "some" communities could be/become (should be) alternative solutions of course, but for now these are good for prototyping and teaching, not for consistent "domestic" applications... And when they'll possibly do so, they might likely be bought. So we'll have "difficulties" as (interaction) designers, so to say: you'll work for your client(s) ... and the corp. that provides the services you'll use!
Should the government regulate artificial intelligence? That was the central question of the first White House workshop on the legal and governance implications of AI, held in Seattle on Tuesday.
“We are observing issues around AI and machine learning popping up all over the government,” said Ed Felten, White House deputy chief technology officer. “We are nowhere near the point of broadly regulating AI … but the challenge is how to ensure AI remains safe, controllable, and predictable as it gets smarter.”
One of the key aims of the workshop, said one of its organizers, University of Washington law professor Ryan Calo, was to help the public understand where the technology is now and where it’s headed. “The idea is not for the government to step in and regulate AI but rather to use its many other levers, like coördination among the agencies and procurement power,” he said. Attendees included technology entrepreneurs, academics, and members of the public.
In a keynote speech, Oren Etzioni, CEO of the Allen Institute for Artificial Intelligence, noted that we are still in the Dark Ages of machine learning, with AI systems that generally only work well on well-structured problems like board games and highway driving. He championed a collaborative approach where AI can help humans to become safer and more efficient. “Hospital errors are the third-leading cause of death in the U.S.,” he said. “AI can help here. Every year, people are dying because we’re not using AI properly in hospitals.”
Oren Etzioni, CEO of the Allen Institute for Artificial Intelligence, left, speaks with attendees at the White House workshop on artificial intelligence.
Nevertheless, Etzioni considers it far too early to talk about regulating AI: “Deep learning is still 99 percent human work and human ingenuity. ‘My robot did it’ is not an excuse. We have to take responsibility for what our robots, AI, and algorithms do.”
A panel on “artificial wisdom” focused on when these human-AI interactions go wrong, such as the case of an algorithm designed to predict future criminal offenders that appears to be racially biased. “The problem is not about the AI agents themselves, it’s about humans using technological tools to oppress other humans in finance, criminal justice, and education,” said Jack Balkin of Yale Law School.
Several academics supported the idea of an “information fiduciary”: giving people who collect big data and use AI the legal duties of good faith and trustworthiness. For example, technologists might be held responsible if they use poor quality data to train AI systems, or fossilize prejudices based on race, age, or gender into the algorithms they design.
As government institutions increasingly rely on AI systems for decision making, those institutions will need personnel who understand the limitations and biases inherent in data and AI technology, noted Kate Crawford, a social scientist at Microsoft Research. She suggested that students be taught ethics alongside programming skills.
Bryant Walker Smith from the University of South Carolina proposed regulatory flexibility for rapidly evolving technologies, such as driverless cars. “Individual companies should make a public case for the safety of their autonomous vehicles,” he said. “They should establish measures and then monitor them over the lifetime of their systems. We need a diversity of approaches to inform public debate.”
This was the first of four workshops planned for the coming months. Two will address AI for social good and issues around safety and control, while the last will dig deeper into the technology’s social and economic implications. Felten also announced that the White House would shortly issue a request for information to give the general public an opportunity to weigh in on the future of AI.
The elephant in the room, of course, was November’s presidential election. In a blog post earlier this month, Felten unveiled a new National Science and Technology Council Subcommittee on Machine Learning and Artificial Intelligence, focused on using AI to improve government services “between now and the end of the Administration.”
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.



























.jpg)

.jpg)
.jpg)


.jpg)



.jpg)
.jpg)
.jpg)
.jpg)