Monday, August 09. 2010
Murder-predicting computers could tell who gets out of prison
-----
The way things usually go is that is a parole board has to deliberate over a convicted person's past crimes and their behavior to determine if they are fit for release from prison. Now, a college professor says that computers could fulfill this role with greater accuracy.
"This system can forecast which inmates will kill again," says University of Pennsylvania professor Richard Berk. "With the help of years of computer data, I can separate the really bad guys being released from the people who probably won't re-offend."
His computer system is actually being used already in probation departments in Philadelphia and Baltimore, though right now it's flagging potential problematic convicts rather than deciding who should stay and who should get released from prison.
The computers make decisions based on models that are built for each criminal, taking in factors such as age, the nature of the crime and other details such as the murder weapon used. The more information the computers have, the better its chances of determining whether someone would kill again as it matches that profile up against what is statistically likely to happen historically.
Pre-Cogs, anyone? The trio of living computers from Minority Report, pictured above, were tasked with knowing when a crime would be committed while it was still a thought in someone's mind.
Related Links:
Wednesday, July 07. 2010
The Sentient City Survival Kit
Tuesday, June 22. 2010
Apple Now Stores and Shares Your iPhones Location
Via Mashable
-----
 Apple’s new privacy policy contains a small new paragraph of big importance: it gives the company license to store “the real-time geographic location of your Apple computer or device” and share it with “partners and licensees.” As if we haven’t had enough privacy kerfuffles of late.
Apple’s new privacy policy contains a small new paragraph of big importance: it gives the company license to store “the real-time geographic location of your Apple computer or device” and share it with “partners and licensees.” As if we haven’t had enough privacy kerfuffles of late.
Apple goes on to assure customers in the remainder of the new clause that location data is “collected anonymously in a form that does not personally identify you.” Still, there seems to be no effective method of opting out of the data storage and sharing, as you’ll need to agree to the new terms and conditions before downloading new apps or any media from the iTunes store.
The company gives a nod to MobileMe’s “Find My iPhone” feature as one of the services that requires personal location information to work, but it’s not saying much about other details, including who the data will be shared with and for how long it will be stored. Apple says the information it collects will be used to “provide and improve location-based products and services”; check out the full text of the new paragraph in the privacy policy below:
“To provide location-based services on Apple products, Apple and our partners and licensees may collect, use, and share precise location data, including the real-time geographic location of your Apple computer or device. This location data is collected anonymously in a form that does not personally identify you and is used by Apple and our partners and licensees to provide and improve location-based products and services. For example, we may share geographic location with application providers when you opt in to their location services.
Some location-based services offered by Apple, such as the MobileMe “Find My iPhone” feature, require your personal information for the feature to work.”
What do you think: should iPhone, iPad and Mac users be wary of this change in the privacy policy? Will this be business as usual now that geographic data is easy to come by on most of our devices?
[via LA Times]
Personal comment:
Is Apple the new evil? Spread the message...
Friday, June 04. 2010
Surveillance Software Knows What a Camera Sees or Searching into surveillance video content.
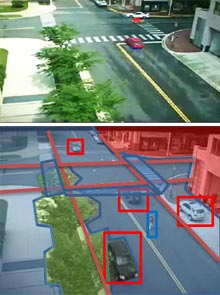 |
||
| Picture this: The objects in a surveillance footage scene (top) are annotated by computer vision software (below). Credit: Song-Chun Zhu/UCLA |
||
|
Multimedia
|

"You can see from the existence of YouTube and all the other growing sources of video around us that being able to search video is a major problem," says Song-Chun Zhu, lead researcher and professor of statistics and computer science at UCLA.
"Almost all search for images or video is still done using the surrounding text," he says. Zhu and UCLA colleagues Benjamin Yao and Haifeng Gong developed a new system, called I2T (Image to Text), which is intended to change that.
It puts a series of computer vision algorithms into a system that takes images or video frames as input, and spits out summaries of what they depict. "That can be searched using simple text search, so it's very human-friendly," says Zhu.
The team applied the software to surveillance footage in collaboration with Mun Wai Lee of ObjectVideo to demonstrate the strength of I2T. Systems like it might help address the fact that there are more and more surveillance cameras--on the streets and in military equipment, for instance--while the number of people working with them remains about the same, says Zhu.
The first part of I2T is an image parser that decomposes an image--meaning it removes the background, and objects like vehicles, trees, and people. Some objects can be broken down further; for example, the limbs of a person or wheels of a car can be separated from the object they belong to.
Next, the meaning of that collection of shapes is determined. "This knowledge representation step is the most important part of the system," says Zhu, explaining that this knowledge comes from human smarts. In 2005, Zhu established the nonprofit Lotus Hill Institute in Ezhou, China, and, with some support from the Chinese government, recruited about 20 graduates of local art colleges to work full-time to annotate a library of images to aid computer vision systems. The result is a database of more than two million images containing objects that have been identified and classified into more than 500 categories.
To ensure that workers annotate images in a standard way, software guides them as they work. It uses versions of the algorithms that will eventually benefit from the final data to pick out the key objects for a person to classify, and it suggests how they might be classified based on previous data. The objects inside images are classified into a hierarchy of categories based on Princeton's WordNet database, which organizes English words into groups according to their meanings. "Once you have the image parsed using that system that also includes the meaning, transcription into the natural language is not too hard," says Zhu, who makes some of the data available for free to other researchers. "It is high-quality data and we hope that more people are going to use this," he says.
The video-processing system also uses algorithms that can describe the movement of objects in successive frames. It generates sentences like "boat1 follows boat2 between 35:56 and 37:23" or "boat3 approaches maritime marker at 40:01." "Sometimes it can do a match on an object that has left and reentered a scene," says Zhu, "and say, for example, this is probably a certain car again." It is also possible to define virtual "trip wires" to help it describe certain events, like a car running a stop sign (see video).
Although the system demonstrates a step toward what Zhu calls a "grand vision in computer science," I2T is not yet ready for commercialization. Processing surveillance footage is relatively easy for the software because the camera--and hence the background in a scene--is static; I2T is far from capable of recognizing the variety of objects or situations a human could. If set loose on random images or videos found online, for example, I2T would struggle to perform so well.
Improving the system's knowledge of how to identify objects and scenes by adding to the number of images in the Lotus Hill Institute training set should help, says Zhu.
The I2T system underlying the surveillance prototype is powerful, says Zu Kim, a researcher at the University of California, Berkeley, who researches the use of computer vision to aid traffic surveillance and vehicle tracking. "It's a really nice piece of work," he says, even if it can't come close to matching human performance.
Kim explains that better image parsing is relevant to artificial intelligence work of all kinds. "There are very many possibilities for a good image parser--for example, allowing a blind person to understand an image on the Web."
Kim can see other uses for generating text from video, pointing out that it could be fed into a speech synthesizer. "It could be helpful if someone was driving and needed to know what a surveillance camera was seeing." But humans are visual creatures, he adds, and in many situations could be expected to prefer to decide what's happening in an image or a video for themselves.
Copyright Technology Review 2010.
Personal comment:
That's nothing new that surveillance camera are being driven by softwares that analyses the content of the image. The "interesting" point here is that the software creates a text based commentary (a sort of text based substitution of the image and its software analysis) upon which text based search algorythms can be applied to find specific content in a video.
Applied to surveillance camera, this could trigger powerfull surveillance. Applied to other projects, this could be interesting to get text based descriptiond of real time actions in public or private space. Of course, with all the questions about the nature of space that come along with this type of project...
Tuesday, June 01. 2010
Ive never been sued by a door. But I guess I can live through it.

From Ubik, by Philip K. Dick (1969):
“The door refused to open. It said, “Five cents, please.”
He searched his pockets. No more coins; nothing. “I’ll pay you tomorrow,” he told the door. Again he tried the knob. Again it remained locked tight. “What I pay you,” he informed it, “is in the nature of a gratuity; I don’t have to pay you.”
“I think otherwise,” the door said. “Look in the purchase contract you signed when you bought this conapt.”In his desk drawer he found the contract; since signing it he had found it necessary to refer to the document many times. Sure enough; payment to his door for opening and shutting constituted a mandatory fee. Not a tip.
“You discover I’m right,” the door said. It sounded smug.
From the drawer beside the sink Joe Chip got a stainless steel knife; with it he began systematically to unscrew the bolt assembly of his apt’s money-gulping door.
“I’ll sue you,” the door said as the first screw fell out.
Joe Chip said, “I’ve never been sued by a door. But I guess I can live through it.”
“
Why do I blog this I really enjoy this quote and find it exemplifies the ever-increasing delegation of decisions that are embedded/inscribed into technical objects. The Ubik door might certainly be the ubicomp posterchild in a parallel (and dystopic) environment but it seems highly plausible nowadays. Let’s accumulate this kind of examples and see what patterns one can find.
Related Links:
Friday, May 28. 2010
Defence lab reveals ultimate CCTV
Via Archinect
-----

"You can't tell who is an insurgent by what they look like, but you can track their behaviour," explained Andrew Seedhouse, chief technologist for sensors and countermeasures at Dstl. The surveillance, DSTL says, will eventually help to "win the battle" against insurgency. Um what ?
Tuesday, May 18. 2010
Facebook Personal Data a Security Risk
Monday, May 17. 2010
If You Want Freedom, Dont Use Proprietary Software
-----
 Free software pioneer Richard Stallman spoke with us recently about the principles of free and open source programs, and what he had to say is as relevant and revolutionary as when he first started working in this field 30 years ago.
Free software pioneer Richard Stallman spoke with us recently about the principles of free and open source programs, and what he had to say is as relevant and revolutionary as when he first started working in this field 30 years ago.
Our community has been talking a lot lately about what it means to be open, about what makes software open, about what makes companies open. No matter what talk of “openness” you hear in the media, no major web company — not Facebook, not Google, not Adobe and certainly not Apple — is creating truly free and open applications. Some may make gestures toward this ideology with APIs or “open source” projects, but ultimately, the company controls the software and the users’ data.
At the end of the day, if you want freedom and privacy, the only way to attain those goals is to abstain from proprietary software, including media players, social networks, operating systems, document storage, email services and any other program that is licensed, patented and locked down by a corporation. If you prefer convenience — well, best to stop complaining about your loss of freedom and/or privacy.
Like many heroes of the digital era, Richard Stallman is largely unsung by the general populace. Yet when it comes to user privacy and technological freedom, he’s probably one of the most committed individuals in the world.
By freedom, he means four things:
- The software should be freely accessible.
- The software should be free to modify.
- The software should be free to share with others.
- The software should be free to change and redistribute copies of the changed software.
Stallman started the Free Software Foundation. He even worked to make an operating system (GNU/Linux) that could be entirely free. And he is deeply opposed to proprietary software, software with commercial licenses that fly in the face of everything he calls freedom.
If you’ve ever downloaded music illegally, if you’ve ever complained about closed platforms, if you’ve ever gotten a serial number online for software you didn’t buy, if you’re worried about social networks controlling your data, you need to hear what Stallman has to say.
We got the chance to interview Stallman extensively at WordCamp San Francisco, and we’ll be posting segments of that interview each week. Stay tuned for insights on music sharing, Apple versus Adobe and more.
Note: Stallman asked that we use Ogg Theora, an open format, for encoding this video. To download the original video, go to its Wikimedia page. This video is published under a Creative Commons-No Derivatives license.
Personal comment:
There's a debate now on Mashable about what is open vs what is proprietary in technology. Especially now that this has become a marketing term full of lies.
Interesting debate to follow, in particular for us in the perspective of two projects we are currently working on where we'll claim for an open approach regarding technology in public spaces (all of them, including in outer space! I-Weather as Deep Space Public Lighting) or where we'll adopt a critical approach regarding surveillance (technologies) in the public space (a future "Paranoid Shelter" project we are working on for a while), followed maybe a bit later by a collaboration ("Globale Paranoïa") with French writer and essayist Eric Sadin.
It's a really a whole big debate, quite complex, just as the question of freedom that is a complex one. For our part, we are interested maybe in a less complex question at first. The one of public space (public is not free so to say, it is shared in different ways and allows for, or offer this and that but not everything).
Friday, May 14. 2010
Who Controls Identity on the Web?
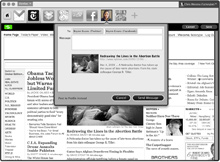 |
| Identity parade: A concept browser designed by Mozilla would let users control a single identity for logging in to different websites. Credit: Mozilla Foundation |
The two approaches are fundamentally different. Facebook's Open Graph Protocol uses the oAuth standard, which lets a website identify a user via a third-party site without exchanging sensitive information. Facebook--whose 400 million active users make it the world's largest social network in the world--stands to benefit as other sites come to rely on the information it holds about users and their social connections.
The approach taken by the Mozilla Foundation, which makes the Firefox browser, comes in the form of a suite of browser extensions. One of the extensions, called Account Manager, can replace all of a user's online passwords with secure, computer-generated strings that are encrypted and protected with a single master password. Mozilla's identity extensions can interact with other identity standards, including OpenGraph, oAuth, and OpenID, a standard that allows any website or Web service provider to host a social network-style profile of a user. The goal of the Mozilla Foundation's efforts is to establish a set of open standards and protocols that could be implemented in any browser or website.
As much as possible, identity would be moved out of the webpage itself and into the "chrome" of the browser--the parts around of the webpage. Logging in and out of sites would be accomplished through buttons at the top of the browser that would activate secure protocols--rendering the process of creating and memorizing usernames and passwords obsolete.
"Every user of the Internet today is expected to describe themselves to every site they go to," says Mike Hanson, principal engineer at Mozilla Labs. Inevitably, Hanson says, this leads to confusion and security holes, such as passwords that are identical across multiple sites.
The solution, according to Hanson, is to let the browser itself manage user identity. Weave Sync, another Mozilla extension, is designed to enable that vision. It stores encrypted versions of a growing list of data on a Mozilla-hosted server (or any user-specified server), including a person's history, preferences, bookmarks, and even open tabs, which can be synced across two or more browsers. This allows users to have the same browser workspace on any device that supports Firefox or its mobile equivalent, Fennec. There's even a prototype for the iPhone, built on top of Apple's Safari browser.
Last fall Mozilla Labs also commissioned Chris Messina, at the time a researcher in residence at Mozilla Labs, to design a Web browser that would manage the other half of online identity--a user's social graph. In Messina's mock-ups, a user can interact with people on the Web in ways that go beyond what OpenID or Facebook's OpenGraph currently offer. "The idea of a social browser is important to me because it's the single point of integration for all websites," says Messina. "It's the one thing that knows who you are across all social experiences."
Messina's designs envision a browser that lets users "follow" other users by viewing all of their relevant information streams--Facebook, Twitter, Flickr, etc.--collected into a single browser tab stamped with that user's profile picture. A similar interface could also be used to control exactly what personal information other people and websites have access to. This could allow, for instance, a user to change her shipping address across any number of sites at once, or to control which version of their identity a particular groups of friends can access. "I'm not interested in the [Mark] Zuckerberg approach, where privacy doesn't exist anymore," says Messina, referring to the CEO of Facebook.
Both Facebook and the Mozilla Foundation will face challenges in pushing their own vision of online identity. John Mitchell, a professor of computer science at Stanford, says the most significant barrier will be the adoption of suitable protocols. Before such protocols can be standardized and rolled into, for instance, the next version of HTML, Web developers are going to have to be willing to experiment.
"What I've seen from a lot of companies is an attempt to guess the end solution and build that only," says Mitchell. "It would be better if, instead, we had an open architecture where people could try many different approaches."
If the new Mozilla software and Messina's designs are sufficiently popular with users and developers (not to mention the influencers who sit on the boards of standards committees like the World Wide Web Consortium), then the foundation's technology could find its way into the regular release of Firefox and perhaps, ultimately, into other browsers.
To Messina, just drawing up the blueprints for such technology was an important first step. "We're further away from the death of the password than I'd like to be, but it's a nice goal to aim for," he says.
Copyright Technology Review 2010.
Personal comment:
Back in 2003 (and up to 2005), we treated this question of identity, surveillance-monitoring technique and data mining of user's data in the Knowscape Mobile project, or in the AI vs AI in self-space project too. We claimed for a total open approach of online identity considering the web as a public space (open data collected in open space belongs to everybody). Of course, this was a speculative project to address the question. An approach that won't be feasible in reality because we definitely need all type of spaces: public, private, semi-public, semi-private, etc. But the status of "space" and their data should be transparent to all users.
Today, this question of "who owns the data", of "public vs private" is becoming more and more of a hot problem, in particular regarding personal data. But it is definitely a problem worth discussing it. So as the status of public space.
IOGraph: Tracking Computer Mouse Movements as Art Work
-----

IOGraph [iographica.com] is a little software application that turns the continuous tracking of computer mouse movements into a "modern art".
The basic concept is that people just "run" the application in the background, and then accomplish their usual activities at the computer. After a long day of hard work, a beautiful image is then created by cumulating all mouse movements and representing them as continuous paths. For people who work in a single application for a considerably long time, IOGraph could even provide potentially interesting usability data when overlayed on a screenshot of the actual window configuration.
You can check some past mouse-tracking art work at Flickr.
fabric | rblg
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.
Quicksearch
Categories
Calendar
|
|
May '24 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||
