Lev Manovich is a leading theorist of cultural objects produced with digital technology, perhaps best known for The Language of New Media (MIT Press, 2001). I interviewed him about his most recent book, Software Takes Command (Bloomsbury Academic, July 2014).
Photograph published in Alan Kay and Adele Goldberg, "Personal Dynamic Media" with the caption, "Kids learning to use the interim Dynabook."
MICHAEL CONNOR: I want to start with the question of methodology. How does one study software? In other words, what is the object of study—do you focus more on the interface, or the underlying code, or some combination of the two?
LEV MANOVICH: The goal of my book is to understand media software—its genealogy (where does it come from), its anatomy (the key features shared by all media viewing and editing software), and its effects in the world (pragmatics). Specifically, I am concerned with two kinds of effects:
1) How media design software shapes the media being created, making some design choices seem natural and easy to execute, while hiding other design possibilities;
2) How media viewing / managing / remixing software shapes our experience of media and the actions we perform on it.
I devote significant space to the analysis of After Effects, Photoshop and Google Earth—these are my primary case studies.
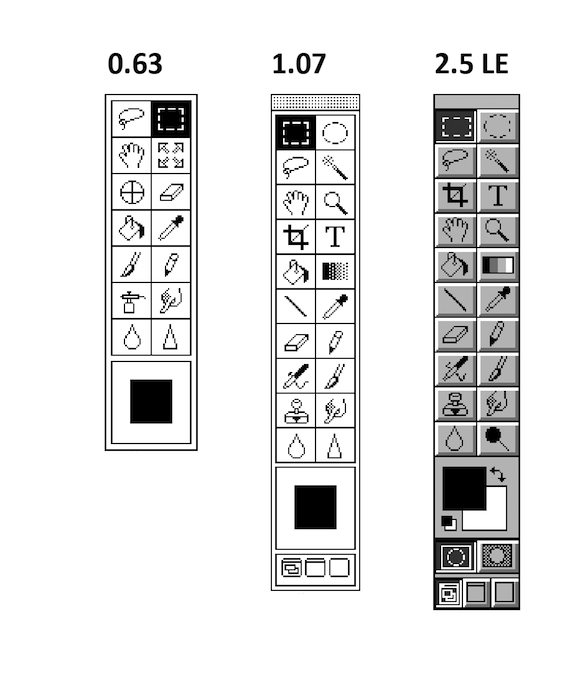
Photoshop Toolbox from version 0.63 (1988) to 7.0 (2002).
I also want to understand what media is today conceptually, after its "softwarization." Do the concepts of media developed to account for industrial-era technologies, from photography to video, still apply to media that is designed and experienced with software? Do they need to be updated, or completely replaced by new more appropriate concepts? For example: do we still have different media or did they merge into a single new meta-medium? Are there some structural features which motion graphics, graphic designs, web sites, product designs, buildings, and video games all share, since they are all designed with software?
In short: does "media" still exist?
For me, "software studies" is about asking such broad questions, as opposed to only focusing on code or interface. Our world, media, economy, and social relations all run on software. So any investigation of code, software architectures, or interfaces is only valuable if it helps us to understand how these technologies are reshaping societies and individuals, and our imaginations.
MC: In order to ask these questions, your book begins by delving into some early ideas from the 1960s and 1970s that had a profound influence on later developers. In looking at these historical precedents, to what extent were you able to engage with the original software or documentation thereof? And to what extent were you relying on written texts by these early figures?
Photograph published in Kay and Goldberg with the caption, "The interim Dynabook system consists of processor, disk drive, display, keyboard, and pointing devices."
LM: In my book I only discuss the ideas of a few of the most important people, and for this, I could find enough sources. I focused on the theoretical ideas from the 1960s and 1970s which led to the development of modern media authoring environment, and the common features of their interfaces. My primary documents were published articles by J. C. R. Licklider, Ivan Sutherland, Ted Nelson, Douglas Engelbart, Alan Kay, and their collaborators, and also a few surviving film clips—Sutherland demonstrating Sketchpad (the first interactive drawing system seen by the public), a tour of Xerox Alto, etc. I also consulted manuals for a few early systems which are available online.
While I was doing this research, I was shocked to realize how little visual documentation of the key systems and software (Sketchpad, Xerox Parc's Alto, first paint programs from late 1960s and 1970s) exists. We have original articles published about these systems with small black-and-white illustrations, and just a few low resolution film clips. And nothing else. None of the historically important systems exist in emulation, so you can't get a feeling of what it was like to use them.
This situation is quite different with other media technologies. You can go to a film museum and experience the real Panoroma from early 1840s, camera obscura, or another pre-cinematic technology. Painters today use the same "new media" as Impressionists in the 1870s—paints in tubes. With computer systems, most of the ideas behind contemporary media software come directly from the 1960s and 1970s—but the original systems are not accessible. Given the number of artists and programmers working today in "software art" and "creative coding," it should be possible to create emulations of at least a few most fundamental early systems. It's good to take care of your parents!
MC: One of the key early examples in your book is Alan Kay's concept of the "Dynabook," which posited the computer as "personal dynamic media" which could be used by all. These ideas were spelled out in his writing, and brought to some fruition in the Xerox Alto computer. I'd like to ask you about the documentation of these systems that does survive. What importance can we attach to these images of users, interfaces and the cultural objects produced with these systems?
Top and center: Images published in Kay and Goldberg with the captions, "An electronic circuit layout system programmed by a 15-year- old student" and "Data for this score was captured on a musical keyboard. A program then converts the data to standard musical notation." Bottom: The Alto Screen showing windows with graphics drawn using commands in Smalltalk programming language.
LM: The most informative sets of images of Alan Kay's "Dynabook" (Xerox Alto) appears in the article he wrote with his collaborator Adele Goldberg in 1977. In my book I analyze this article in detail, interpreting it as "media theory" (as opposed to just documentation of the system). Kay said that reading McLuhan convinced him that computer can be a medium for personal expression. The article presents theoretical development of this idea and reports on its practical implementation (Xerox Alto).
Alan Turing theoretically defined a computer as a machine that can simulate a very large class of other machines, and it is this simulation ability that is largely responsible for the proliferation of computers in modern society. But it was only Kay and his generation that extended the idea of simulation to media—thus turning the Universal Turing Machine into a Universal Media Machine, so to speak. Accordingly, Kay and Goldberg write in the article: "In a very real sense, simulation is the central notion of the Dynabook." However, as I suggest in the book, simulating existing media become a chance to extend and add new functions. Kay and Goldberg themselves are clear about this—here is, for example, what they say about an electronic book: "It need not be treated as a simulated paper book since this is a new medium with new properties. A dynamic search may be made for a particular context. The non-sequential nature of the file medium and the use of dynamic manipulation allow a story to have many accessible points of view."
The many images of media software developed both by Xerox team and other Alto users which appear in the article illustrate these ideas. Kay and Goldberg strategically give us examples of how their "interim 'Dynabook'" can allow users to paint, draw, animate, compose music, and compose text. This maked Alto first Universal Media Machine—the first computer offering ability to compose and create cultural experiences and artifacts for all senses.
MC: I'm a bit surprised to hear you say the words "just documentation!" In the case of Kay, his theoretical argument was perhaps more important than any single prototype. But, in general, one of the things I find compelling about your approach is your analysis of specific elements of interfaces and computer operations. So when you use the example of Ivan Sutherland's Sketchpad, wasn't it the documentation (the demo for a television show produced by MIT in 1964) that allowed you to make the argument that even this early software wasn't merely a simulation of drawing, but a partial reinvention of it?
Frames from Sketchpad demo video illustrating the program’s use of constraints. Left column: a user selects parts of a drawing. Right column: Sketchpad automatically adjusts the drawing. (The captured frames were edited in Photoshop to show the Sketchpad screen more clearly.)
LM: The reason I said "just documentation" is that normally people dont think about Sutherland, Engelbart or Kay as "media theorists," and I think it's more common to read their work as technical reports.
On to to Sutherland. Sutherland describes the new features of his system in his Ph.D. thesis and the published article, so in principle you can just read them and get these ideas. But at the same time, the short film clip which demonstrates the Sketchpad is invaluable—it helps you to better understand how these new features (such as "contraints satisfaction") actually worked, and also to "experience" them emotionally. Since I have seen the film clip years before I looked at Sutherland's PhD thesis (now available online), I can't really say what was more important. Maybe it was not even the original film clip, but its use in one of Alan Kay's lectures. In the lecture Alan Kay shows the clip, and explains how important these new features were.
MC: The Sketchpad demo does have a visceral impact. You began this interview by asking, "does media still exist?" Along these lines, the Sutherland clip raises the question of whether drawing, for one, still exists. The implications of this seem pretty enormous. Now that you have established the principle that all media are contingent on the software that produces, do we need to begin analyzing all media (film, drawing or photography) from the point of view of software studies? Where might that lead?
LM: The answer which I arrive to the question "does media still exist?" after 200 pages is relevant to all media which is designed or accessed with software tools. What we identify by conceptual inertia as "properties" of different mediums are actually the properties of media software—their interfaces, the tools, and the techniques they make possible for navigating, creating, editing, and sharing media documents. For example, the ability to automatically switch between different views of a document in Acrobat Reader or Microsoft Word is not a property of “text documents,” but as a result of software techniques whose heritage can be traced to Engelbart’s “view control.” Similarly, "zoom" or "pan" is not exclusive to digital images or texts or 3D scenes—its the properly of all modern media software.
Along with these and a number of other "media-independent" techniques (such as "search") which are build into all media software, there are also "media-specific" techniques which can only be used with particular data types. For example, we can extrude a 2-D shape to make a 3D model, but we can't extrude a text. Or, we can change contrast and saturation on a photo, but these operations do not make sense in relation to 3D models, texts, or sound.
So when we think of photography, film or any other medium, we can think of it as a combination of "media-independent" techniques which it shares with all other mediums, and also techniques which are specific to it.
MC: I'd proposed the title, "Don't Study Media, Study Software" for this article. But it sounds like you are taking a more balanced view?
LM: Your title makes me nervous, because some people are likely to misinterpret it. I prefer to study software such as Twitter, Facebook, Instagram, Photoshop, After Effects, game engines, etc., and use this understanding in interpreting the content created with this software—tweets, messages, social media photos, professional designs, video games, etc. For example, just this morning I was looking at a presentation by one of Twitter's engineers about the service, and learned that sometimes the responses to tweets can arrive before the tweet itself. This is important to know if we are to analyze the content of Twitter communication between people, for example.
Today, all cultural forms which require a user to click even once on their device to access and/or participate run on software. We can't ignore technology any longer. In short: "software takes command."
The NSA revelations highlight the role sophisticated algorithms play in sifting through masses of data. But more surprising is their widespread use in our everyday lives. So should we be more wary of their power?
The financial sector has long used algorithms to predict market fluctuations, but they can also help police identify crime hot spots or online shops target their customers. Photograph: Danil Melekhin/Getty Images
On 4 August 2005, the police department of Memphis, Tennessee, made so many arrests over a three-hour period that it ran out of vehicles to transport the detainees to jail. Three days later, 1,200 people had been arrested across the city – a new police department record. Operation Blue Crush was hailed a huge success.
Larry Godwin, the city's new police director, quickly rolled out the scheme and by 2011 crime across the city had fallen by 24%. When it was revealed Blue Crush faced budget cuts earlier this year, there was public outcry. "Crush" policing is now perceived to be so successful that it has reportedly been mimicked across the globe, including in countries such as Poland and Israel. In 2010, it was reported that two police forces in the UK were using it, but their identities were not revealed.
Crush stands for "Criminal Reduction Utilising Statistical History". Translated, it means predictive policing. Or, more accurately, police officers guided by algorithms. A team of criminologists and data scientists at the University of Memphis first developed the technique using IBM predictive analytics software. Put simply, they compiled crime statistics from across the city over time and overlaid it with other datasets – social housing maps, outside temperatures etc – then instructed algorithms to search for correlations in the data to identify crime "hot spots". The police then flooded those areas with highly targeted patrols.
"It's putting the right people in the right places on the right day at the right time," said Dr Richard Janikowski, an associate professor in the department of criminology and criminal justice at the University of Memphis, when the scheme launched. But not everyone is comfortable with the idea. Some critics have dubbed it "Minority Report" policing, in reference to the sci-fi film in which psychics are used to guide a "PreCrime" police unit.
The use of algorithms in policing is one example of their increasing influence on our lives. And, as their ubiquity spreads, so too does the debate around whether we should allow ourselves to become so reliant on them – and who, if anyone, is policing their use. Such concerns were sharpened further by the continuing revelations about how the US National Security Agency (NSA) has been using algorithms to help it interpret the colossal amounts of data it has collected from its covert dragnet of international telecommunications.
"For datasets the size of those the NSA collect, using algorithms is the only way to operate for certain tasks," says James Ball, the Guardian's data editor and part of the paper's NSA Files reporting team. "The problem is how the rules are set: it's impossible to do this perfectly. If you're, say, looking for terrorists, you're looking for something very rare. Set your rules too tight and you'll miss lots of, probably most, potential terror suspects. But set them more broadly and you'll drag lots of entirely blameless people into your dragnet, who will then face further intrusion or even formal investigation. We don't know exactly how the NSA or GCHQ use algorithms – or how extensively they're applied. But we do know they use them, including on the huge data trawls revealed in the Guardian."
From dating websites and City trading floors, through to online retailing and internet searches (Google's search algorithm is now a more closely guarded commercial secret than the recipe for Coca-Cola), algorithms are increasingly determining our collective futures. "Bank approvals, store cards, job matches and more all run on similar principles," says Ball. "The algorithm is the god from the machine powering them all, for good or ill."
Most observers blame the 'flash crash' of May 2010 on the use of algorithms to perform high-frequency trading. Photograph: Spencer Platt/Getty Images
But what is an algorithm? Dr Panos Parpas, a lecturer in the quantitative analysis and decision science ("quads") section of the department of computing at Imperial College London, says that wherever we use computers, we rely on algorithms: "There are lots of types, but algorithms, explained simply, follow a series of instructions to solve a problem. It's a bit like how a recipe helps you to bake a cake. Instead of having generic flour or a generic oven temperature, the algorithm will try a range of variations to produce the best cake possible from the options and permutations available."
Parpas stresses that algorithms are not a new phenomenon: "They've been used for decades – back to Alan Turing and the codebreakers, and beyond – but the current interest in them is due to the vast amounts of data now being generated and the need to process and understand it. They are now integrated into our lives. On the one hand, they are good because they free up our time and do mundane processes on our behalf. The questions being raised about algorithms at the moment are not about algorithms per se, but about the way society is structured with regard to data use and data privacy. It's also about how models are being used to predict the future. There is currently an awkward marriage between data and algorithms. As technology evolves, there will be mistakes, but it is important to remember they are just a tool. We shouldn't blame our tools."
The "mistakes" Parpas refers to are events such as the "flash crash" of 6 May 2010, when the Dow Jones industrial average fell 1,000 points in just a few minutes, only to see the market regain itself 20 minutes later. The reasons for the sudden plummet has never been fully explained, but most financial observers blame a "race to the bottom" by the competing quantitative trading (quants) algorithms widely used to perform high-frequency trading. Scott Patterson, a Wall Street Journal reporter and author of The Quants, likens the use of algorithms on trading floors to flying a plane on autopilot. The vast majority of trades these days are performed by algorithms, but when things go wrong, as happened during the flash crash, humans can intervene.
"By far the most complicated algorithms are to be found in science, where they are used to design new drugs or model the climate," says Parpas. "But they are done within a controlled environment with clean data. It is easy to see if there is a bug in the algorithm. The difficulties come when they are used in the social sciences and financial trading, where there is less understanding of what the model and output should be, and where they are operating in a more dynamic environment. Scientists will take years to validate their algorithm, whereas a trader has just days to do so in a volatile environment."
Most investment banks now have a team of computer science PhDs coding algorithms, says Parpas, who used to work on such a team. "With City trading, everyone is running very similar algorithms," he says. "They all follow each other, meaning you get results such as the flash crash. They use them to speed up the process and to break up big trades to disguise them from competitors when a big investment is being made. It's an on-going, live process. They will run new algorithms for a few days to test them before letting them loose with real money. In currency trading, an algorithm lasts for about two weeks before it is stopped because it is surpassed by a new one. In equities, which is a less complicated market, they will run for a few months before a new one replaces them. It takes a day or two to write a currency algorithm. It's hard to find out information about them because, for understandable reasons, they don't like to advertise when they are successful. Goldman Sachs, though, has a strong reputation across the investment banks for having a brilliant team of algorithm scientists. PhDs students in this field will usually be employed within a few months by an investment bank."
The idea that the world's financial markets – and, hence, the wellbeing of our pensions, shareholdings, savings etc – are now largely determined by algorithmic vagaries is unsettling enough for some. But, as the NSA revelations exposed, the bigger questions surrounding algorithms centre on governance and privacy. How are they being used to access and interpret "our" data? And by whom?
Dr Ian Brown, the associate director of Oxford University's Cyber Security Centre, says we all urgently need to consider the implications of allowing commercial interests and governments to use algorithms to analyse our habits: "Most of us assume that 'big data' is munificent. The laws in the US and UK say that much of this [the NSA revelations] is allowed, it's just that most people don't realise yet. But there is a big question about oversight. We now spend so much of our time online that we are creating huge data-mining opportunities."
Algorithms can run the risk of linking some racial groups to particular crimes. Photograph: Alamy
Brown says that algorithms are now programmed to look for "indirect, non-obvious" correlations in data. "For example, in the US, healthcare companies can now make assessments about a good or bad insurance risk based, in part, on the distance you commute to work," he says. "They will identity the low-risk people and market their policies at them. Over time, this creates or exacerbates societal divides. Professor Oscar Gandy, at the University of Pennsylvania, has done research into 'secondary racial discrimination', whereby credit and health insurance, which relies greatly on postcodes, can discriminate against racial groups because they happen to live very close to other racial groups that score badly."
Brown harbours similar concerns over the use of algorithms to aid policing, as seen in Memphis where Crush's algorithms have reportedly linked some racial groups to particular crimes: "If you have a group that is disproportionately stopped by the police, such tactics could just magnify the perception they have of being targeted."
Viktor Mayer-Schönberger, professor of internet governance and regulation at the Oxford Internet Institute, also warns against humans seeing causation when an algorithm identifies a correlation in vast swaths of data. "This transformation presents an entirely new menace: penalties based on propensities," he writes in his new book, Big Data: A Revolution That Will Transform How We Live, Work and Think, which is co-authored by Kenneth Cukier, the Economist's data editor. "That is the possibility of using big-data predictions about people to judge and punish them even before they've acted. Doing this negates ideas of fairness, justice and free will. In addition to privacy and propensity, there is a third danger. We risk falling victim to a dictatorship of data, whereby we fetishise the information, the output of our analyses, and end up misusing it. Handled responsibly, big data is a useful tool of rational decision-making. Wielded unwisely, it can become an instrument of the powerful, who may turn it into a source of repression, either by simply frustrating customers and employees or, worse, by harming citizens."
Mayer-Schönberger presents two very different real-life scenarios to illustrate how algorithms are being used. First, he explains how the analytics team working for US retailer Target can now calculate whether a woman is pregnant and, if so, when she is due to give birth: "They noticed that these women bought lots of unscented lotion at around the third month of pregnancy, and that a few weeks later they tended to purchase supplements such as magnesium, calcium and zinc. The team ultimately uncovered around two dozen products that, used as proxies, enabled the company to calculate a 'pregnancy prediction' score for every customer who paid with a credit card or used a loyalty card or mailed coupons. The correlations even let the retailer estimate the due date within a narrow range, so it could send relevant coupons for each stage of the pregnancy."
Harmless targeting, some might argue. But what happens, as has already reportedly occurred, when a father is mistakenly sent nappy discount vouchers instead of his teenage daughter whom a retailer has identified is pregnant before her own father knows?
Mayer-Schönberger's second example on the reliance upon algorithms throws up even more potential dilemmas and pitfalls: "Parole boards in more than half of all US states use predictions founded on data analysis as a factor in deciding whether to release somebody from prison or to keep him incarcerated.
Norah Jones: a specially developed algorithm predicted that her debut album contained a disproportionately high number of hit records. Photograph: Olycom SPA/Rex Features
Christopher Steiner, author of Automate This: How Algorithms Came to Rule Our World, has identified a wide range of instances where algorithms are being used to provide predictive insights – often within the creative industries. In his book, he tells the story of a website developer called Mike McCready, who has developed an algorithm to analyse and rate hit records. Using a technique called advanced spectral deconvolution, the algorithm breaks up each hit song into its component parts – melody, tempo, chord progression and so on – and then uses that to determine common characteristics across a range of No 1 records. McCready's algorithm correctly predicted – before they were even released – that the debut albums by both Norah Jones and Maroon 5 contained a disproportionately high number of hit records.
The next logical step – for profit-seeking record companies, perhaps – is to use algorithms to replace the human songwriter. But is that really an attractive proposition? "Algorithms are not yet writing pop music," says Steiner. He pauses, then laughs. "Not that we know of, anyway. If I were a record company executive or pop artist, I wouldn't tell anyone if I'd had a number one written by an algorithm."
Steiner argues that we should not automatically see algorithms as a malign influence on our lives, but we should debate their ubiquity and their wide range of uses. "We're already halfway towards a world where algorithms run nearly everything. As their power intensifies, wealth will concentrate towards them. They will ensure the 1%-99% divide gets larger. If you're not part of the class attached to algorithms, then you will struggle. The reason why there is no popular outrage about Wall Street being run by algorithms is because most people don't yet know or understand it."
But Steiner says we should welcome their use when they are used appropriately to aid and speed our lives. "Retail algorithms don't scare me," he says. "I find it useful when Amazon tells me what I might like. In the US, we know we will not have enough GP doctors in 15 years, as not enough are being trained. But algorithms can replace many of their tasks. Pharmacists are already seeing some of their prescribing tasks replaced by algorithms. Algorithms might actually start to create new, mundane jobs for humans. For example, algorithms will still need a human to collect blood and urine samples for them to analyse."
There can be a fine line, though, between "good" and "bad" algorithms, he adds: "I don't find the NSA revelations particularly scary. At the moment, they just hold the data. Even the best data scientists would struggle to know what to do with all that data. But it's the next step that we need to keep an eye on. They could really screw up someone's life with a false prediction about what they might be up to."
Ever notice how ant colonies so successfully explore and exploit resources in the world … to find food at 4th of July picnics, for example? You may find it annoying. But as an ecologist who studies ants and collective behavior, I think it’s intriguing — especially the fact that it’s all done without any central control.
What’s especially remarkable: the close parallels between ant colonies’ networks and human-engineered ones. One example is “Anternet”, where we, a group of researchers at Stanford, found that the algorithm desert ants use to regulate foraging is like the Traffic Control Protocol (TCP) used to regulate data traffic on the internet. Both ant and human networks use positive feedback: either from acknowledgements that trigger the transmission of the next data packet, or from food-laden returning foragers that trigger the exit of another outgoing forager.
But insect behavior mimicking human networks — another example are the ant-like solutions to the traveling salesman problem provided by the ant colony optimization algorithm — is actually not what’s most interesting about ant networks. What’s far more interesting are the parallels in the other direction: What have the ants worked out that we humans haven’t thought of yet?
During the 130 million years or so that ants have been around, evolution has tuned ant colony algorithms.
During the 130 million years or so that ants have been around, evolution has tuned ant colony algorithms to deal with the variability and constraints set by specific environments.
Ant colonies use dynamic networks of brief interactions to adjust to changing conditions. No individual ant knows what’s going on. Each ant just keeps track of its recent experience meeting other ants, either in one-on-one encounters when ants touch antennae, or when an ant encounters a chemical deposited by another.
Such networks have made possible the phenomenal diversity and abundance of more than 11,000 ant species in every conceivable habitat on Earth. So Anternet, and other ant networks, have a lot to teach us. Ant protocols may suggest ways to build our own information networks…
Dealing with High Operating Costs
Harvester ant colonies in the desert must spend water to get water. The ants lose water when foraging in the hot sun, and get their water by metabolizing it out of the seeds that they collect. Since colonies store seeds, their system of positive feedback doesn’t waste foraging effort when water costs are high — even if it means they leave some seeds “on the table” (or rather, ground) to be obtained on another, more humid day.
In this way, the Anternet allows the colony to deal with high operating costs. In the internet, the TCP protocol also prevents the system from sending data out on the internet when there’s no bandwidth available. Effort would be wasted if the message is lost, so it’s not worth sending it out unless it’s certain to reach its destination.
More recently, I’ve shown how natural selection is currently optimizing the Anternet algorithm. I’ve been following a population of 300 harvester ant colonies for more than 25 years, and by using genetic fingerprinting we figured out which colonies had more offspring colonies.
Colonies store food inside the nest as a survival tactic. On especially hot days, colonies that are likely to lay low instead of collecting more food are the ones that have more offspring colonies over their 25-year lifetimes. Restraint therefore emerges as the best strategy at the colony level. Long-lived colonies in the desert regulate their behavior not to maximize or optimize food intake, but instead to keep going without wasting resources.
In the face of scarcity, the algorithm that regulates the flow of ants is evolving toward minimizing operating costs rather than immediate accumulation. This is a sustainable strategy for any system, like a desert ant colony or the mobile internet, where it’s essential to achieve long-term reliability while avoiding wasted effort.
Scaling Up from Small to Large Systems
What happens when a system scales up? Like human-engineered systems, ant systems must be robust to scale up as the colony grows, and they have to be able to tolerate the failure of individual components.
Since large systems allow for some messiness, the ideal solutions utilize the contributions of each additional ant in such a way that the benefit of an extra worker outweighs the cost of producing and feeding one.
The tools that serve large colonies well, therefore, are redundancy and minimal information. Enormous ant colonies function using very simple interactions among nameless ants without any address.
In engineered systems we too are searching for ways to ensure reliable outcomes, as our networks scale, by using cheap operations that make use of randomness. Elegant top-down designs are appealing, but the robustness of ant algorithms shows that tolerating imperfection sometimes leads to better solutions.
Optimizing for First-Mover Advantage
The diversity of ant algorithms shows how evolution has responded to different environmental constraints. When operating costs are low and colonies seek an ephemeral delicacy — like flower nectar or watermelon rinds — searching speed is essential if the colony is to capture the prize before it dries up or is taken away.
In the face of scarcity, the algorithm that regulates the flow of ants is evolving toward minimizing operating costs rather than immediate accumulation.
Since ant colonies compete with each other and many are out looking for the same food, the first colony to arrive might have the best chance of holding on to the food and keeping the other ants away.
How does a colony achieve this first-mover advantage without any central control? The challenge in this situation is for the colony to manage the flow of ants so it has an ant almost everywhere almost all the time. The goal is to increase the likelihood that some ant will be close enough to encounter whatever happens to show up.
One strategy ants use (familiar from our own data networks) is to set up a circuit of permanent highways — like a network of cell phone towers — from which ants search locally. The invasive Argentine ants are experts at this; they’ll find any crumb that lands on your kitchen counter.
The Argentine ants also adjust their paths, shifting from a close to random walk when there are lots of ants around, leading each ant to search thoroughly in a small area, to a straighter path when there are few ants around, thus allowing the whole group to cover more ground.
Like a distributed demand-response network, the aggregated responses of each ant to local conditions generates the outcome for the whole system, without any centralized direction or control.
Addressing Security Breaches and Disasters
In the tropics, where hundreds of ant species are packed close together and competing for resources, colonies must deal with security problems. This has led to the evolution of security protocols that use local information for intrusion detection and for response.
One colony might use (“borrow” or “steal”, as humans would say) information from another, such as chemical trails or the density of ants, to find and use resources.
Rather than attempting to prevent incursions completely, however, ants create loose, stochastic identity systems in which one species regulates its behavior in response to the level of incursion from another.
There are obvious parallels with computer security. It’s becoming clear (consider recent events!) that we too will need to implement local evaluation and repair of intrusions, tolerating some level of imperfection. The ants have found ways to let their systems respond to each others’ incursions, without attempting to set up a central authority that regulates hacks.
Ants have evolved security protocols that use local information for intrusion detection and response.
Some of our networks seem to be moving toward using methods deployed by the ants.
Take the disaster recovery protocols of ants that forage in trees where branches can break, so the threat of rupture is high. A ring network, with signals or ants flowing in both directions, allows for rapid recovery here; after a break in the flow in one direction, the flow in the other direction can re-establish a link.
Similarly, early fiber-optic cable networks were often disrupted by farm machinery and other digging: one break could bring down the system because it would isolate every load. Engineers soon discovered, as ants have already done, that ring networks would create networks that are easier to repair.
***
Our networks will continue to change and evolve. By examining and comparing the algorithms used by ants in the desert, in the tropical forest, and the invasive species that visit our kitchens, it’s already obvious that the ants have come up with new solutions that can teach us something about how we should engineer our systems.
Using simple interactions like the brief touch of antennae — not unlike our fleeting status updates in ephemeral social networks — colonies make networks that respond to a world that constantly changes, with resources that show up in patches and then disappear. These networks are easy to repair and can grow or shrink.
Ant colonies have been used throughout history as models of industry, obedience, and wisdom. Although the ants themselves can be indolent, inconsiderate of others, and downright stupid, we have much to learn from ant colony protocols. The ants have evolved ways of working together that we haven’t yet dreamed of.
Not only do the ants build amazing architectures, they are also using algorithms and networks for millenia to achieve quite sustainable results and behaviors. As the article suggest, should we learn from ants?
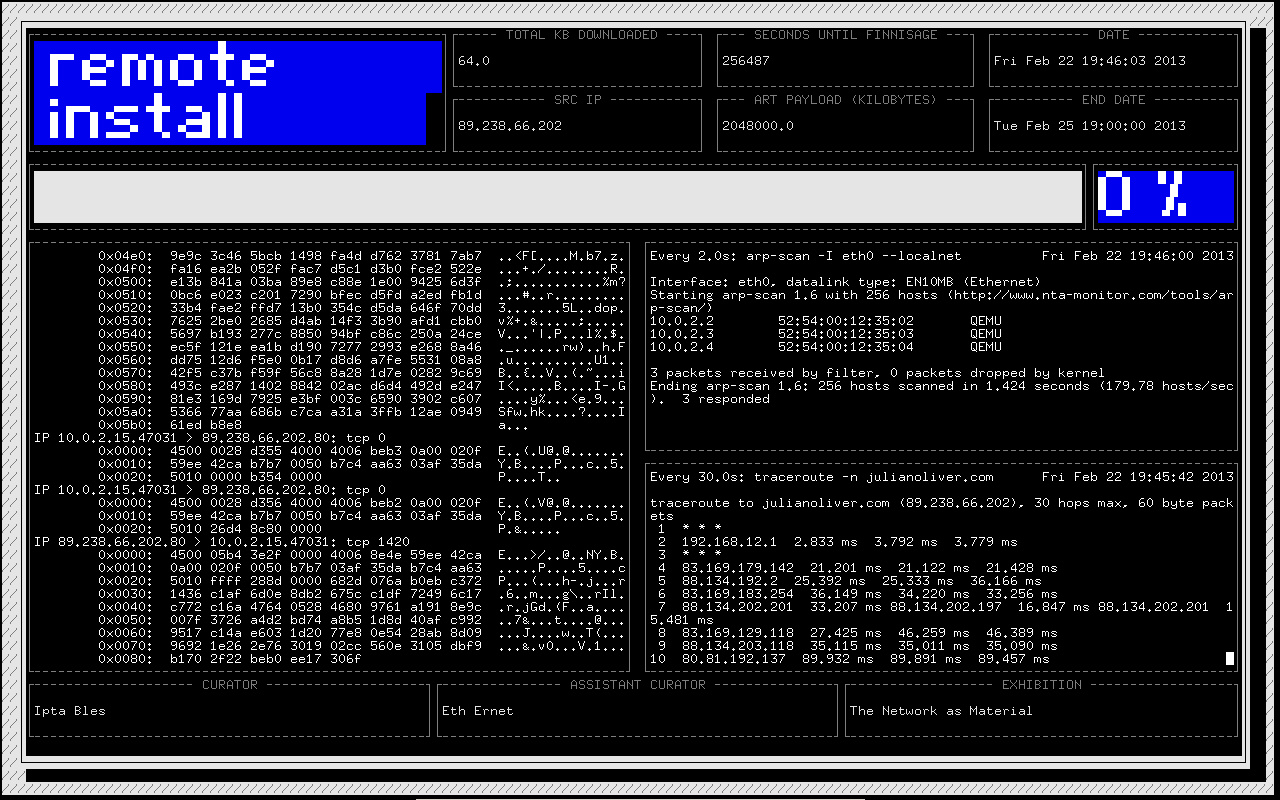
Created by Julian Oliver and installed at the recent NODE Forum in Frankfurt, Remote Install is an installation that remotely installs itself over the network and presents its own installation process as an artefact in itself.
Distributed as a stripped down, customised GNU/Linux Operating System, the gallery merely needs to copy a single file onto a USB stick, plug it into a computer on site and boot it on the day of the opening. Remote Install then analyses its network context and the amount of space given to it – the free space on the USB stick. It then logs into the artist’s server and creates a file of random binary data to exactly fill this space and proceeds to download it over the course of the entire exhibition. An algorithm ensures the last byte is downloaded on the last second of the exhibition.
In addition, devices on the gallery network that use too much bandwidth are knocked off the network by the script, as they are a threat to the installation process (wireless mode only). Detailed statistics relating to the process appear in several regions in the output, including a list of all the routers between the gallery and the artist’s server on the Internet.
The full process includes start up during exhibition opening, the software ask for IP from local network, requests name of Curator, Assistant Curator and Exhibition and exhibition close date. The software the determines amount of available space given to the artist (disk space), send a network packet to julianoliver.com with this value on a predetermined port and server generates a file matching this size of random data. The software then downloads the file throughout exhibition, ensuring that the process completes on last second of closing date.
A new line of research examines what happens in an office where the positions of the cubicles and walls—even the coffee pot—are all determined by data.
Can we use data about people to alter physical reality, even in real time, and improve their performance at work or in life? That is the question being asked by a developing field called augmented social reality.
Here’s a simple example. A few years ago, with Sandy Pentland’s human dynamics research group at MIT’s Media Lab, I created what I termed an “augmented cubicle.” It had two desks separated by a wall of plexiglass with an actuator-controlled window blind in the middle. Depending on whether we wanted different people to be talking to each other, the blinds would change position at night every few days or weeks.
The augmented cubicle was an experiment in how to influence the social dynamics of a workplace. If a company wanted engineers to talk more with designers, for example, it wouldn’t set up new reporting relationships or schedule endless meetings. Instead, the blinds in the cubicles between the groups would go down. Now as engineers passed the designers it would be easier to have a quick chat about last night’s game or a project they were working on.
Human social interaction is rapidly becoming more measurable at a large scale, thanks to always-on sensors like cell phones. The next challenge is to use what we learn from this behavioral data to influence or enhance how people work with each other. The Media Lab spinoff company I run uses ID badges packed with sensors to measure employees’ movements, their tone of voice, where they are in an office, and whom they are talking to. We use data we collect in offices to advise companies on how to change their organizations, often through actual physical changes to the work environment. For instance, after we found that people who ate in larger lunch groups were more productive, Google and other technology companies that depend on serendipitous interaction to spur innovation installed larger cafeteria tables.
In the future, some of these changes could be made in real time. At the Media Lab, Pentland’s group has shown how tone of voice, fluctuation in speaking volume, and speed of speech can predict things like how persuasive a person will be in, say, pitching a startup idea to a venture capitalist. As part of that work, we showed that it’s possible to digitally alter your voice so that you sound more interested and more engaged, making you more persuasive.
Another way we can imagine using behavioral data to augment social reality is a system that suggests who should meet whom in an organization. Traditionally that’s an ad hoc process that occurs during meetings or with the help of mentors. But we might be able to draw on sensor and digital communication data to compare actual communication patterns in the workplace with an organizational ideal, then prompt people to make introductions to bridge the gaps. This isn’t the LinkedIn model, where people ask to connect to you, but one where an analytical engine would determine which of your colleagues or friends to introduce to someone else. Such a system could be used to stitch together entire organizations.
Unlike augmented reality, which layers information on top of video or your field of view to provide extra information about the world, augmented social reality is about systems that change reality to meet the social needs of a group.
For instance, what if office coffee machines moved around according to the social context? When a coffee-pouring robot appeared as a gag in TV commercial two years ago, I thought seriously about the uses of a coffee machine with wheels. By positioning the coffee robot in between two groups, for example, we could increase the likelihood that certain coworkers would bump into each other. Once we detected—using smart badges or some other sensor—that the right conversations were occurring between the right people, the robot could move on to another location. Vending machines, bowls of snacks—all could migrate their way around the office on the basis of social data. One demonstration of these ideas came from a team at Plymouth University in the United Kingdom. In their “Slothbots” project, slow-moving robotic walls subtly change their position over time to alter the flow of people in a public space, constantly tuning their movement in response to people’s behavior.
The large amount of behavioral data that we can collect by digital means is starting to converge with technologies for shaping the world in response. Will we notify people when their environment is being subtly transformed? Is it even ethical to use data-driven techniques to persuade and influence people this way? These questions remain unanswered as technology leads us toward this augmented world.
Ben Waber is cofounder and CEO of Sociometric Solutions and the author of People Analytics: How Social Sensing Technology Will Transform Business, published by FT Press.
Personal comment:
Following my previous posts about data, monitoring or data centers: or when your "ashtray" will come close to you and your interlocutor, at the "right place", after having suggested to "meet" him...
Besides this trivial (as well as uninteresting and boring) functional example, there are undoubtedly tremendous implications and stakes around the fact that we might come to algorithmically negociated social interactions. In fact that we might increase these type of interactions, including physically, as we are already into algorithmic social interactions.
Which rules and algorithms, to do what? Again, we come back to the point when architects will have to start to design algorithms and implement them in close collaboration with developers.
Storing video and other files more intelligently reduces the demand on servers in a data center.
Worldwide, data centers consume huge and growing amounts of electricity.
New research suggests that data centers could significantly cut their electricity usage simply by storing fewer copies of files, especially videos.
For now the work is theoretical, but over the next year, researchers at Alcatel-Lucent’s Bell Labs and MIT plan to test the idea, with an eye to eventually commercializing the technology. It could be implemented as software within existing facilities. “This approach is a very promising way to improve the efficiency of data centers,” says Emina Soljanin, a researcher at Bell Labs who participated in the work. “It is not a panacea, but it is significant, and there is no particular reason that it couldn’t be commercialized fairly quickly.”
With the new technology, any individual data center could be expected to save 35 percent in capacity and electricity costs—about $2.8 million a year or $18 million over the lifetime of the center, says Muriel Médard, a professor at MIT’s Research Laboratory of Electronics, who led the work and recently conducted the cost analysis.
So-called storage area networks within data center servers rely on a tremendous amount of redundancy to make sure that downloading videos and other content is a smooth, unbroken experience for consumers. Portions of a given video are stored on different disk drives in a data center, with each sequential piece cued up and buffered on your computer shortly before it’s needed. In addition, copies of each portion are stored on different drives, to provide a backup in case any single drive is jammed up. A single data center often serves millions of video requests at the same time.
The new technology, called network coding, cuts way back on the redundancy without sacrificing the smooth experience. Algorithms transform the data that makes up a video into a series of mathematical functions that can, if needed, be solved not just for that piece of the video, but also for different parts. This provides a form of backup that doesn’t rely on keeping complete copies of the data. Software at the data center could simply encode the data as it is stored and decode it as consumers request it.
Médard’s group previously proposed a similar technique for boosting wireless bandwidth (see “A Bandwidth Breakthrough”). That technology deals with a different problem: wireless networks waste a lot of bandwidth on back-and-forth traffic to recover dropped portions of a signal, called packets. If mathematical functions describing those packets are sent in place of the packets themselves, it becomes unnecessary to re-send a dropped packet; a mobile device can solve for the missing packet with minimal processing. That technology, which improves capacity up to tenfold, is currently being licensed to wireless carriers, she says.
Between the electricity needed to power computers and the air conditioning required to cool them, data centers worldwide consume so much energy that by 2020 they will cause more greenhouse-gas emissions than global air travel, according to the consulting firm McKinsey.
Smarter software to manage them has already proved to be a huge boon (see “A New Net”). Many companies are building data centers that use renewable energy and smarter energy management systems (see “The Little Secrets Behind Apple’s Green Data Centers”). And there are a number of ways to make chips and software operate more efficiently (see “Rethinking Energy Use in Data Centers”). But network coding could make a big contribution by cutting down on the extra disk drives—each needing energy and cooling—that cloud storage providers now rely on to ensure reliability.
This is not the first time that network coding has been proposed for data centers. But past work was geared toward recovering lost data. In this case, Médard says, “we have considered the use of coding to improve performance under normal operating conditions, with enhanced reliability a natural by-product.”
Personal comment:
Still a link in the context of our workshop at the Tsinghua University and related to data storage at large.
The link between energy, algorithms and data storage made obvious. To be read in parallel with the previous repost from Kazys Varnelis, Into the Cloud (with zombies). -
In the same idea, another piece of code that could cut flight delays and therefore cut approx $1.2 million in annual crew costs and $5 million in annual fuel savings to a midsized airline...
A few events linked to the book launch of Bracket - [goes soft] that we missed to annouce on | rblg. After New-York at the Columbia's Studio-X NYC and Houston last February, the book will be launched in Toronto on the 1st of March.
Among several interesting projects curated by Benjamin Bratton, Julia Czerniak, Jeffrey Inaba, Geoff Manaugh, Philippe Rahm, Charles Renfro sits Arctic Opening, a project by fabric | ch that we realized back in 2010 on the Frioul Archipelago (Marseilles), in France.
The co-editors are Lola Sheppard and Neeraj Bhatia. The book is published by Actar and designed by Thumb.
I’m really excited to share my new essay, “The Relevance of Algorithms,” with those of you who are interested in such things. It’s been a treat to get to think through the issues surrounding algorithms and their place in public culture and knowledge, with some of the participants in Culture Digitally (here’s the full litany: Braun, Gillespie, Striphas, Thomas, the third CD podcast, and Anderson‘s post just last week), as well as with panelists and attendees at the recent 4S and AoIR conferences, with colleagues at Microsoft Research, and with all of you who are gravitating towards these issues in their scholarship right now.
The motivation of the essay was two-fold: first, in my research on online platforms and their efforts to manage what they deem to be “bad content,” I’m finding an emerging array of algorithmic techniques being deployed: for either locating and removing sex, violence, and other offenses, or (more troublingly) for quietly choreographing some users away from questionable materials while keeping it available for others. Second, I’ve been helping to shepherd along this anthology, and wanted my contribution to be in the spirit of the its aims: to take one step back from my research to articulate an emerging issue of concern or theoretical insight that (I hope) will be of value to my colleagues in communication, sociology, science & technology studies, and information science.
The anthology will ideally be out in Fall 2013. And we’re still finalizing the subtitle. So here’s the best citation I have.
Gillespie, Tarleton. “The Relevance of Algorithms. forthcoming, in Media Technologies, ed. Tarleton Gillespie, Pablo Boczkowski, and Kirsten Foot. Cambridge, MA: MIT Press.
Below is the introduction, to give you a taste.
Algorithms play an increasingly important role in selecting what information is considered most relevant to us, a crucial feature of our participation in public life. Search engines help us navigate massive databases of information, or the entire web. Recommendation algorithms map our preferences against others, suggesting new or forgotten bits of culture for us to encounter. Algorithms manage our interactions on social networking sites, highlighting the news of one friend while excluding another’s. Algorithms designed to calculate what is “hot” or “trending” or “most discussed” skim the cream from the seemingly boundless chatter that’s on offer. Together, these algorithms not only help us find information, they provide a means to know what there is to know and how to know it, to participate in social and political discourse, and to familiarize ourselves with the publics in which we participate. They are now a key logic governing the flows of information on which we depend, with the “power to enable and assign meaningfulness, managing how information is perceived by users, the ‘distribution of the sensible.’” (Langlois 2012)
Algorithms need not be software: in the broadest sense, they are encoded procedures for transforming input data into a desired output, based on specified calculations. The procedures name both a problem and the steps by which it should be solved. Instructions for navigation may be considered an algorithm, or the mathematical formulas required to predict the movement of a celestial body across the sky. “Algorithms do things, and their syntax embodies a command structure to enable this to happen” (Goffey 2008, 17). We might think of computers, then, fundamentally as algorithm machines — designed to store and read data, apply mathematical procedures to it in a controlled fashion, and offer new information as the output.
But as we have embraced computational tools as our primary media of expression, and have made not just mathematics but all information digital, we are subjecting human discourse and knowledge to these procedural logics that undergird all computation. And there are specific implications when we use algorithms to select what is most relevant from a corpus of data composed of traces of our activities, preferences, and expressions.
These algorithms, which I’ll call public relevance algorithms, are — by the very same mathematical procedures — producing and certifying knowledge. The algorithmic assessment of information, then, represents a particular knowledge logic, one built on specific presumptions about what knowledge is and how one should identify its most relevant components. That we are now turning to algorithms to identify what we need to know is as momentous as having relied on credentialed experts, the scientific method, common sense, or the word of God.
What we need is an interrogation of algorithms as a key feature of our information ecosystem (Anderson 2011), and of the cultural forms emerging in their shadows (Striphas 2010), with a close attention to where and in what ways the introduction of algorithms into human knowledge practices may have political ramifications. This essay is a conceptual map to do just that. I will highlight six dimensions of public relevance algorithms that have political valence:
1. Patterns of inclusion: the choices behind what makes it into an index in the first place, what is excluded, and how data is made algorithm ready
2. Cycles of anticipation: the implications of algorithm providers’ attempts to thoroughly know and predict their users, and how the conclusions they draw can matter
3. The evaluation of relevance: the criteria by which algorithms determine what is relevant, how those criteria are obscured from us, and how they enact political choices about appropriate and legitimate knowledge
4. The promise of algorithmic objectivity: the way the technical character of the algorithm is positioned as an assurance of impartiality, and how that claim is maintained in the face of controversy
5. Entanglement with practice: how users reshape their practices to suit the algorithms they depend on, and how they can turn algorithms into terrains for political contest, sometimes even to interrogate the politics of the algorithm itself
6. The production of calculated publics: how the algorithmic presentation of publics back to themselves shape a public’s sense of itself, and who is best positioned to benefit from that knowledge.
Considering how fast these technologies and the uses to which they are put are changing, this list must be taken as provisional, not exhaustive. But as I see it, these are the most important lines of inquiry into understanding algorithms as emerging tools of public knowledge and discourse.
It would also be seductively easy to get this wrong. In attempting to say something of substance about the way algorithms are shifting our public discourse, we must firmly resist putting the technology in the explanatory driver’s seat. While recent sociological study of the Internet has labored to undo the simplistic technological determinism that plagued earlier work, that determinism remains an alluring analytical stance. A sociological analysis must not conceive of algorithms as abstract, technical achievements, but must unpack the warm human and institutional choices that lie behind these cold mechanisms. I suspect that a more fruitful approach will turn as much to the sociology of knowledge as to the sociology of technology — to see how these tools are called into being by, enlisted as part of, and negotiated around collective efforts to know and be known. This might help reveal that the seemingly solid algorithm is in fact a fragile accomplishment.
~ ~ ~
Here is the full article [PDF]. Please feel free to share it, or point people to this post.
SCI-Arc Masters of Architecture graduates Liz and Kyle von Hasseln have been awarded the inaugural Gehry Prize for developing an interruptible 3D printing method, dubbed Phantom Geometry, that allows designers to make alterations to the design while it is being printed. The Phantom Geometry method is a convenient alternative to the conventional, static 3D printing systems available today. The system’s main components includes a UV light projector, a special photo-sensitive resin, and controlled robotic arms from SCI-Arc’s Robot House.
See also the project ProtoHouse by Softkill Design in the area of digital fabrication (obviously a technology that is actually in the "peak of expectations" phase of the hype cycle for emerging technologies graph).
Kevin Slavin argues that we're living in a world designed for -- and increasingly controlled by -- algorithms. In this riveting talk from TEDGlobal, he shows how these complex computer programs determine: espionage tactics, stock prices, movie scripts, and architecture. And he warns that we are writing code we can't understand, with implications we can't control.
Kevin Slavin navigates in the algoworld, the expanding space in our lives that’s determined and run by algorithms. Full bio »
It takes you 500,000 microseconds just to click a mouse. But if you’re a Wall Street algorithm and you’re five microseconds behind, you’re a loser.” (Kevin Slavin)
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.