Thursday, April 21. 2011
Via MIT Technology Review
-----
An experimental system would tighten the limits on information provided to websites.
By Erica Naone
 |
| Credit: iStockphoto |
Today, many websites ask users to take a devil's deal: share personal information in exchange for receiving useful personalized services. New research from Microsoft, which will be presented at the IEEE Symposium on Security and Privacy in May, suggests the development of a Web browser and associated protocols that could strengthen the user's hand in this exchange. Called RePriv, the system mines a user's behavior via a Web browser but controls how the resulting information is released to websites that want to offer personalized services, such as a shopping site that automatically knows users' interests.
"The browser knows more about the user's behavior than any individual site," says Ben Livshits, a researcher at Microsoft who was involved with the work. He and colleagues realized that the browser could therefore offer a better way to track user behavior, while it also protects the information that is collected, because users won't have to give away as much of their data to every site they visit.
The RePriv browser tracks a user's behavior to identify a list of his or her top interests, as well as the level of attention devoted to each. When the user visits a site that wants to offer personalization, a pop-up window will describe the type of information the site is asking for and give the user the option of allowing the exchange or not. Whatever the user decides, the site doesn't get specific information about what the user has been doing—instead, it sees the interest information RePriv has collected.
Livshits explains that a news site could use RePriv to personalize a user's view of the front page. The researchers built a demonstration based on the New York Times website. It reorders the home page to reflect the user's top interests, also taking into account data collected from social sites such as Digg that suggests which stories are most popular within different categories.
Livshits admits that RePriv still gives sites some data about users. But he maintains that the user remains aware and in control. He adds that cookies and other existing tracking techniques sites already collect far more user data than RePriv supplies.
The researchers also developed a way for third parties to extend RePriv's capabilities. They built a demonstration browser extension that tracks a user's interactions with Netflix to collect more detailed data about that person's movie preferences. The extension could be used by a site such as Fandango to personalize the movie information it presents—again, with user permission.
"There is a clear tension between privacy and personalized technologies, including recommendations and targeted ads," says Elie Bursztein, a researcher at the Stanford Security Laboratory, who is developing an extension for the Chrome Web browser that enables more private browsing. "Putting the user in control by moving personalization into the browser offers a new way forward," he says.
"In the medium term, RePriv could provide an attractive interface for service providers that will dissuade them from taking more abusive approaches to customization," says Ari Juels, chief scientist and director of RSA Laboratories, a corporate research center.
Juels says RePriv is generally well engineered and well thought out, but he worries that the tool goes against "the general migration of data and functionality to the cloud." Many services, such as Facebook, now store information in the cloud, and RePriv wouldn't be able to get at data there—an omission that could hobble the system, he points out.
Juels is also concerned that most people would be permissive about the information they allow RePriv to release, and he believes many sites would exploit this. And he points out that websites with a substantial competitive advantage in the huge consumer-preference databases they maintain would likely resist such technology. "RePriv levels the playing field," he says. "This may be good for privacy, but it will leave service providers hungry." Therefore, he thinks, big players will be reluctant to cooperate with a system like this.
Livshits argues that some companies could use these characteristics of RePriv to their advantage. He says the system could appeal to new services, which struggle to give users a personalized experience the first time they visit a site. And larger sites might welcome the opportunity to get user data from across a person's browsing experience, rather than only from when the user visits their site. Livshits believes they might be willing to use the system and protect user privacy in exchange.
Copyright Technology Review 2011.
Via Libération
-----
par Alexandre Hervaud

Capture Ecrans
Dire où l’on se trouve en permanence via son smartphone, c’est simple comme bonjour : on peut le déclamer à qui ça intéresse (indice : personne) via les versions mobiles des réseaux sociaux type Facebook ou Twitter, ou check-iné comme un fou sur les appli spécifiques de géolocalisation comme Foursquare. Mais il y a un autre moyen, d’autant plus simple qu’il est automatique : avoir un iPhone et permettre sans le savoir à Apple de pister nos moindres déplacements.
La découverte est signée Alasdair Allan et Pete Warden, deux spécialistes qui l’ont annoncé aujourd’hui à la conférence Where 2.0 après l’avoir explicité sur le site Radar. Leur trouvaille peut être résumée ainsi : les iPhone et iPad 3G fonctionnant sous le système d’exploitation iOS4 (disponible depuis juin 2010) enregistrent régulièrement la localisation des produits dans un fichier caché, dont le contenu est restauré à chaque sauvegarde ou migration d’appareil.
Concrètement, d’après Radar, les localisations sont stockées dans un fichier appelé consolidated.db, avec coordonnées géographiques évoluant en fonction de la date d’enregistrement. La chose n’est pas toujours archi précise, triangularisation oblige, mais un test auprès des collègues de Liberation.fr montre le genre de données ainsi enregistrées :
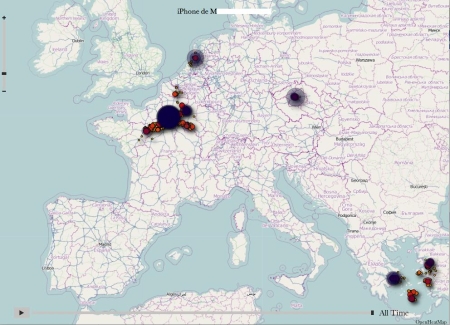
Un logiciel baptisé iPhone Tracker est disponible pour lire à son tour ce genre de traces. En mouvement (soit en faisant évoluer la chronologie), ça donne ça :
Washington DC to New York from Alasdair Allan on Vimeo.
Radar précise qu’à ce stade, rien ne prouve que ces données puissent échapper au contrôle de l’utilisateur (comprendre : être envoyées via le Net à des serveurs cachés contrôlés par de maléfiques Big Brother en puissance suivant la moindre de nos traces). De même, l’existence même de ce type d’informations n’est pas en soi une nouvelle : les opérateurs téléphoniques en disposent et peuvent les transmettre aux autorités dans certaines circonstances (enquêtes, etc.), mais uniquement sur demande en bonne et due forme (mandat, par exemple). Le problème ici soulevé est que le fichier en question n’est pas du tout crypté, donc facilement accessible en cas de vol ou d’emprunt de téléphone, par exemple. Des fonctionnalités permises par l’iOS4, comme la classification automatiques des photos prises par l’iPhone en fonction du lieu de la prise de vue (cf capture à droite), peuvent éventuellement constituer une piste d’explication quant à la présence d’un tel fichier dans le téléphone.
Parmi les pistes suggérées par Radar pour éviter ce genre de désagrément, on peut citer l’option « Encrypt iPhone Backup » accessibles via les paramètres d’iTunes une fois l’appareil connecté à l’ordinateur. Alasdair Allan et Pete Warden expliquent en détail leur trouvaille dans la vidéo ci-dessous (en anglais, 20 minutes) :
Pour la petite histoire, Peter Warden a travaillé durant cinq ans pour Apple (mais jamais directement sur l’avancée de l’iPhone), avant de quitter l’entreprise « en bons termes » il y a trois ans. Sur la page permettant de télécharger iPhone Tracker, qu’ils ont conçus eux-même, les deux geeks semblent presque déçus de leur découverte : « on est tous les deux de grands fans des produits Apple, et on ne prend vraiment aucun plaisir à mettre en avant ce problème ».
Friday, April 08. 2011
Via MIT Technology Review
-----
The social network breaks an unwritten rule by giving away plans to its new data center—an action it hopes will make the Web more efficient.
By Tom Simonite
 |
The new data center, in Prineville, Oregon, covers 147,000 square feet and is one of the most energy-efficient computing warehouses ever built.
Credit: Jason Madera |
Just weeks before switching on a massive, super-efficient data center in rural Oregon, Facebook is giving away the designs and specifications to the whole thing online. In doing so, the company is breaking a long-established unwritten rule for Web companies: don't share the secrets of your server-stuffed data warehouses.
Ironically, most of those secret servers rely heavily on open source or free software, for example the Linux operating system and the Apache webserver. Facebook's move—dubbed the Open Compute Project—aims to kick-start a similar trend with hardware.
"Mark [Zuckerberg] was able to start Facebook in his dorm room because PHP and Apache and other free and open-source software existed," says David Recordon, who helps coordinate Facebook's use of, and contribution to, open-source software. "We wanted to encourage that for hardware, and release enough information about our data center and servers that someone else could go and actually build them."
The attitude of other large technology firms couldn't be more different, says Ricardo Bianchini, who researches energy-efficient computing infrastructure at Rutgers University. "Typically, companies like Google or Microsoft won't tell you anything about their designs," he says. A more open approach could help the Web as a whole become more efficient, he says. "Opening up the building like this will help researchers a lot, and also other industry players," he says. "It's opening up new opportunities to share and collaborate."
The open hardware designs are for a new data center in Prineville, Oregon, that will be switched on later this month. The 147,000-square-foot building will increase Facebook's overall computing capacity by around half; the social network already processes some 100 million new photos every day, and its user base of over 500 million is growing fast.
The material being made available - on a new website - includes detailed specifications of the building's electrical and cooling systems, as well as the custom designs of the servers inside. Facebook is dubbing the approach "open" rather than open-source because its designs won't be subject to a true open-source legal license, which requires anyone modifying them to share any changes they make.
The plans reveal the fruits of Facebook's efforts to create one of the most energy-efficient data centers ever built. Unlike almost every other data center, Facebook's new building doesn't use chillers to cool the air flowing past the servers. Instead, air from the outside flows over foam pads moistened by water sprays to cool by evaporation. The building is carefully oriented so that prevailing winds direct outside air into the building in both winter and summer.
Facebook's engineers also created a novel electrical design that cuts the number of times that the electricity from the grid is run through a transformer to reduce its voltage en route to the servers inside. Most data centers use transformers to reduce the 480 volts from the nearest substation down to 208 volts, but Facebook's design skips that step. "We run 480 volts right up to the server," says Jay Park, Facebook's director of data-center engineering. "That eliminates the need for a transformer that wastes energy."
To make this possible, Park and colleagues created a new type of server power supply that takes 277 volts and which can be split off from the 408-volt supply without the need for a transformer. The 408 volts is delivered using a method known as "three phase power": three wires carry three alternating currents with carefully different timings. Splitting off one of those wires extracts a 277-volt supply.
Park and colleagues also came up with a new design for the backup batteries that keep servers running during power outages before backup generators kick in—a period of about 90 seconds. Instead of building one huge battery store in a dedicated room, many cabinet-sized battery packs are spread among the servers. This is more efficient because the batteries share electrical connections with the computers around them, eliminating the dedicated connections and transformers needed for one large store. Park calculates that his new electrical design wastes about 7 percent of the power fed into it, compared to around 23 percent for a more conventional design.
According to the standard measure of data-center efficiency—the power usage efficiency (PUE) score—Facebook's tweaks have created one of the most efficient data centers ever. A PUE is calculated by dividing a building's total power use by the energy used by its computers - a perfect data center would score 1. "Our tests show that Prineville has a PUE of 1.07," says Park. Google, which invests heavily in data-center efficiency, reported an average PUE of 1.13 across all its locations for the last quarter of 2010 (when winter temperatures make data centers most efficient), with the most efficient scoring 1.1.
Google and others will now be able to cherry pick elements from Facebook's designs, but that poses no threat to Facebook's real business, says Frank Frankovsky, the company's director of hardware design. "Facebook is successful because of the great social product, not [because] we can build low-cost infrastructure," he says. "There's no reason we shouldn't help others out with this."
Copyright Technology Review 2011.
Personal comment:
Will efficient and sustainable ways to organize architectural climate as well as to use energy become a by product of data centers? Might be.
Via Creative Applications
-----

Particles is the latest installation by Daito Manabe and Motoi Ishibashi currently on exhibit at the Yamaguchi Center for Arts and Media [YCAM]. The installation centers around a spiral-shaped rail construction on which a number of balls with built-in LEDs and xbee transmitters are rolling while blinking in different time intervals, resulting in spatial drawings of light particles.
This is an art installation which is able to create a visionary beautiful dots pattern of blinking innumerable illuminations floating in all directions on the air. The number of balls with a built-in LED, pass through one after another on the rail “8-spiral shape.” We see this phenomenon like “the light particle float around” because the balls radiate in various timing.
The openFrameworks application controls both the release of “particles” as well as their glow based on the information read within the application. The image below shows perlin noise being translated into particles, giving each one glow and position properties.

The position of each ball is determined via total of 17 control points on the rail. Every time a ball passes through one of them, the respective ball’ s positional information is transmitted via a built-in infrared sensor. During the time the ball travels between one control points to the next, this position is calculated based on its average speed. The data for regulating the balls’ luminescence are divided by the control point segments and are switched every time a ball passes on a control point.
The audiences can select a shape from several patterns floating in aerial space using an interface of the display. The activation of the virtual balls on the screen are determined by the timing which a ball moving on the rail passes through a certain check point on the rail and the speed which is calculated by using average speed values. The sound is generated from the ball positions and the information of LED flash pattern and is played through 8ch speakers. The board inside the ball is an Arduino compatible board based on the original design from Arduino
Exhibition page: particles.ycam.jp/en/
Date & Time:March 5 (sat)−May 5 (thu) , 2011 10:00−19:00
Venue: Yamaguchi Center for Arts and Media [YCAM] Studio B
Admission free
Images courtesy of Yamaguchi Center for Arts and Media [YCAM] Photos: Ryuichi Maruo (YCAM)








Friday, April 01. 2011
Google has launched a close copy of Facebook's Like button that will crowdsource people's opinions to help the search engine know what's valuable online. Called +1, the button will appear on Web pages and alongside search results, enabling users to signal that they appreciated a piece of content. Google will track clicks of the button to hone search results, using clicks from your friends as a signal of what is most relevant to you.
The search company announced the new feature today, saying:
It's called +1—the digital shorthand for "this is pretty cool."
A YouTube video introduces the feature, which will be "slowly rolling out" on Google.com, at first for users of the English version. Google's new feature is very similar to one built by both rival Bing and search startup Blekko. Both use data from Facebook Like buttons to have your friends' opinions tune your search results.
However, your social network is something of a blind spot to Google, which doesn't have the same understanding of your social connections that Facebook does. Initially the +1s of your Google chat buddies and contacts will be used to "enhance" your results, the company says, while eventually +1s from your Twitter contacts might also be taken into account. At launch, though, +1 seems likely to be somewhat hamstrung by Google's lack of a detailed social "graph" for its users.
When Google previously tried to remedy that, it enraged people by guessing at whom its users were friends with from their e-mail activity, and pitching them into a copy of Twitter called Buzz. Coincidentally, the FTC today delivered its verdict on the debacle, labeling Google's behavior an example of "deceptive privacy practices."
Yet Google's hunger for a better understanding of your social network, and hence whose opinions it should use to tune your search results, is only going to be heightened by the launch of +1. Expect to see Google make renewed efforts to launch features and tools that capture social connections in coming months.
Personal comment:
With the actual hype word "crowdsourced", we can see a bigger trend coming on: the collaboration between a digital network of "universal computer machines" and a physical network of human brains to achieve tasks that humans can't do (as quickly) or that computers are not able to achieve (recaptcha paradigm). We see more and more network applications where computers either allow to organize a network of brains or literally rely on "organic brains" (a big and first exemple to my knowledge being the Mechanical Turk service by Amazon).
It is therefore a double augmentation: the human brain augmented by the networked computer(s) augmented by the brains. We can possibly see the same effects on contemporary space: the physical space augmented by the digital networked/mediated space augmented by the physical space...
|