Lev Manovich is a leading theorist of cultural objects produced with digital technology, perhaps best known for The Language of New Media (MIT Press, 2001). I interviewed him about his most recent book, Software Takes Command (Bloomsbury Academic, July 2014).
Photograph published in Alan Kay and Adele Goldberg, "Personal Dynamic Media" with the caption, "Kids learning to use the interim Dynabook."
MICHAEL CONNOR: I want to start with the question of methodology. How does one study software? In other words, what is the object of study—do you focus more on the interface, or the underlying code, or some combination of the two?
LEV MANOVICH: The goal of my book is to understand media software—its genealogy (where does it come from), its anatomy (the key features shared by all media viewing and editing software), and its effects in the world (pragmatics). Specifically, I am concerned with two kinds of effects:
1) How media design software shapes the media being created, making some design choices seem natural and easy to execute, while hiding other design possibilities;
2) How media viewing / managing / remixing software shapes our experience of media and the actions we perform on it.
I devote significant space to the analysis of After Effects, Photoshop and Google Earth—these are my primary case studies.
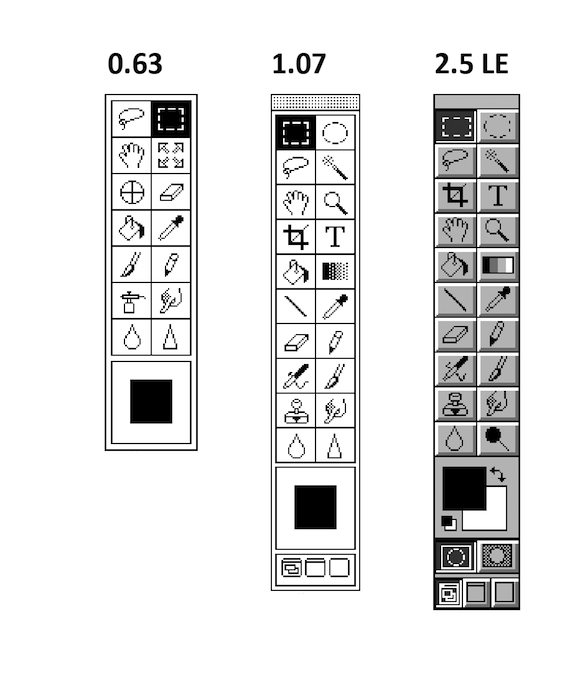
Photoshop Toolbox from version 0.63 (1988) to 7.0 (2002).
I also want to understand what media is today conceptually, after its "softwarization." Do the concepts of media developed to account for industrial-era technologies, from photography to video, still apply to media that is designed and experienced with software? Do they need to be updated, or completely replaced by new more appropriate concepts? For example: do we still have different media or did they merge into a single new meta-medium? Are there some structural features which motion graphics, graphic designs, web sites, product designs, buildings, and video games all share, since they are all designed with software?
In short: does "media" still exist?
For me, "software studies" is about asking such broad questions, as opposed to only focusing on code or interface. Our world, media, economy, and social relations all run on software. So any investigation of code, software architectures, or interfaces is only valuable if it helps us to understand how these technologies are reshaping societies and individuals, and our imaginations.
MC: In order to ask these questions, your book begins by delving into some early ideas from the 1960s and 1970s that had a profound influence on later developers. In looking at these historical precedents, to what extent were you able to engage with the original software or documentation thereof? And to what extent were you relying on written texts by these early figures?
Photograph published in Kay and Goldberg with the caption, "The interim Dynabook system consists of processor, disk drive, display, keyboard, and pointing devices."
LM: In my book I only discuss the ideas of a few of the most important people, and for this, I could find enough sources. I focused on the theoretical ideas from the 1960s and 1970s which led to the development of modern media authoring environment, and the common features of their interfaces. My primary documents were published articles by J. C. R. Licklider, Ivan Sutherland, Ted Nelson, Douglas Engelbart, Alan Kay, and their collaborators, and also a few surviving film clips—Sutherland demonstrating Sketchpad (the first interactive drawing system seen by the public), a tour of Xerox Alto, etc. I also consulted manuals for a few early systems which are available online.
While I was doing this research, I was shocked to realize how little visual documentation of the key systems and software (Sketchpad, Xerox Parc's Alto, first paint programs from late 1960s and 1970s) exists. We have original articles published about these systems with small black-and-white illustrations, and just a few low resolution film clips. And nothing else. None of the historically important systems exist in emulation, so you can't get a feeling of what it was like to use them.
This situation is quite different with other media technologies. You can go to a film museum and experience the real Panoroma from early 1840s, camera obscura, or another pre-cinematic technology. Painters today use the same "new media" as Impressionists in the 1870s—paints in tubes. With computer systems, most of the ideas behind contemporary media software come directly from the 1960s and 1970s—but the original systems are not accessible. Given the number of artists and programmers working today in "software art" and "creative coding," it should be possible to create emulations of at least a few most fundamental early systems. It's good to take care of your parents!
MC: One of the key early examples in your book is Alan Kay's concept of the "Dynabook," which posited the computer as "personal dynamic media" which could be used by all. These ideas were spelled out in his writing, and brought to some fruition in the Xerox Alto computer. I'd like to ask you about the documentation of these systems that does survive. What importance can we attach to these images of users, interfaces and the cultural objects produced with these systems?
Top and center: Images published in Kay and Goldberg with the captions, "An electronic circuit layout system programmed by a 15-year- old student" and "Data for this score was captured on a musical keyboard. A program then converts the data to standard musical notation." Bottom: The Alto Screen showing windows with graphics drawn using commands in Smalltalk programming language.
LM: The most informative sets of images of Alan Kay's "Dynabook" (Xerox Alto) appears in the article he wrote with his collaborator Adele Goldberg in 1977. In my book I analyze this article in detail, interpreting it as "media theory" (as opposed to just documentation of the system). Kay said that reading McLuhan convinced him that computer can be a medium for personal expression. The article presents theoretical development of this idea and reports on its practical implementation (Xerox Alto).
Alan Turing theoretically defined a computer as a machine that can simulate a very large class of other machines, and it is this simulation ability that is largely responsible for the proliferation of computers in modern society. But it was only Kay and his generation that extended the idea of simulation to media—thus turning the Universal Turing Machine into a Universal Media Machine, so to speak. Accordingly, Kay and Goldberg write in the article: "In a very real sense, simulation is the central notion of the Dynabook." However, as I suggest in the book, simulating existing media become a chance to extend and add new functions. Kay and Goldberg themselves are clear about this—here is, for example, what they say about an electronic book: "It need not be treated as a simulated paper book since this is a new medium with new properties. A dynamic search may be made for a particular context. The non-sequential nature of the file medium and the use of dynamic manipulation allow a story to have many accessible points of view."
The many images of media software developed both by Xerox team and other Alto users which appear in the article illustrate these ideas. Kay and Goldberg strategically give us examples of how their "interim 'Dynabook'" can allow users to paint, draw, animate, compose music, and compose text. This maked Alto first Universal Media Machine—the first computer offering ability to compose and create cultural experiences and artifacts for all senses.
MC: I'm a bit surprised to hear you say the words "just documentation!" In the case of Kay, his theoretical argument was perhaps more important than any single prototype. But, in general, one of the things I find compelling about your approach is your analysis of specific elements of interfaces and computer operations. So when you use the example of Ivan Sutherland's Sketchpad, wasn't it the documentation (the demo for a television show produced by MIT in 1964) that allowed you to make the argument that even this early software wasn't merely a simulation of drawing, but a partial reinvention of it?
Frames from Sketchpad demo video illustrating the program’s use of constraints. Left column: a user selects parts of a drawing. Right column: Sketchpad automatically adjusts the drawing. (The captured frames were edited in Photoshop to show the Sketchpad screen more clearly.)
LM: The reason I said "just documentation" is that normally people dont think about Sutherland, Engelbart or Kay as "media theorists," and I think it's more common to read their work as technical reports.
On to to Sutherland. Sutherland describes the new features of his system in his Ph.D. thesis and the published article, so in principle you can just read them and get these ideas. But at the same time, the short film clip which demonstrates the Sketchpad is invaluable—it helps you to better understand how these new features (such as "contraints satisfaction") actually worked, and also to "experience" them emotionally. Since I have seen the film clip years before I looked at Sutherland's PhD thesis (now available online), I can't really say what was more important. Maybe it was not even the original film clip, but its use in one of Alan Kay's lectures. In the lecture Alan Kay shows the clip, and explains how important these new features were.
MC: The Sketchpad demo does have a visceral impact. You began this interview by asking, "does media still exist?" Along these lines, the Sutherland clip raises the question of whether drawing, for one, still exists. The implications of this seem pretty enormous. Now that you have established the principle that all media are contingent on the software that produces, do we need to begin analyzing all media (film, drawing or photography) from the point of view of software studies? Where might that lead?
LM: The answer which I arrive to the question "does media still exist?" after 200 pages is relevant to all media which is designed or accessed with software tools. What we identify by conceptual inertia as "properties" of different mediums are actually the properties of media software—their interfaces, the tools, and the techniques they make possible for navigating, creating, editing, and sharing media documents. For example, the ability to automatically switch between different views of a document in Acrobat Reader or Microsoft Word is not a property of “text documents,” but as a result of software techniques whose heritage can be traced to Engelbart’s “view control.” Similarly, "zoom" or "pan" is not exclusive to digital images or texts or 3D scenes—its the properly of all modern media software.
Along with these and a number of other "media-independent" techniques (such as "search") which are build into all media software, there are also "media-specific" techniques which can only be used with particular data types. For example, we can extrude a 2-D shape to make a 3D model, but we can't extrude a text. Or, we can change contrast and saturation on a photo, but these operations do not make sense in relation to 3D models, texts, or sound.
So when we think of photography, film or any other medium, we can think of it as a combination of "media-independent" techniques which it shares with all other mediums, and also techniques which are specific to it.
MC: I'd proposed the title, "Don't Study Media, Study Software" for this article. But it sounds like you are taking a more balanced view?
LM: Your title makes me nervous, because some people are likely to misinterpret it. I prefer to study software such as Twitter, Facebook, Instagram, Photoshop, After Effects, game engines, etc., and use this understanding in interpreting the content created with this software—tweets, messages, social media photos, professional designs, video games, etc. For example, just this morning I was looking at a presentation by one of Twitter's engineers about the service, and learned that sometimes the responses to tweets can arrive before the tweet itself. This is important to know if we are to analyze the content of Twitter communication between people, for example.
Today, all cultural forms which require a user to click even once on their device to access and/or participate run on software. We can't ignore technology any longer. In short: "software takes command."
The NSA revelations highlight the role sophisticated algorithms play in sifting through masses of data. But more surprising is their widespread use in our everyday lives. So should we be more wary of their power?
The financial sector has long used algorithms to predict market fluctuations, but they can also help police identify crime hot spots or online shops target their customers. Photograph: Danil Melekhin/Getty Images
On 4 August 2005, the police department of Memphis, Tennessee, made so many arrests over a three-hour period that it ran out of vehicles to transport the detainees to jail. Three days later, 1,200 people had been arrested across the city – a new police department record. Operation Blue Crush was hailed a huge success.
Larry Godwin, the city's new police director, quickly rolled out the scheme and by 2011 crime across the city had fallen by 24%. When it was revealed Blue Crush faced budget cuts earlier this year, there was public outcry. "Crush" policing is now perceived to be so successful that it has reportedly been mimicked across the globe, including in countries such as Poland and Israel. In 2010, it was reported that two police forces in the UK were using it, but their identities were not revealed.
Crush stands for "Criminal Reduction Utilising Statistical History". Translated, it means predictive policing. Or, more accurately, police officers guided by algorithms. A team of criminologists and data scientists at the University of Memphis first developed the technique using IBM predictive analytics software. Put simply, they compiled crime statistics from across the city over time and overlaid it with other datasets – social housing maps, outside temperatures etc – then instructed algorithms to search for correlations in the data to identify crime "hot spots". The police then flooded those areas with highly targeted patrols.
"It's putting the right people in the right places on the right day at the right time," said Dr Richard Janikowski, an associate professor in the department of criminology and criminal justice at the University of Memphis, when the scheme launched. But not everyone is comfortable with the idea. Some critics have dubbed it "Minority Report" policing, in reference to the sci-fi film in which psychics are used to guide a "PreCrime" police unit.
The use of algorithms in policing is one example of their increasing influence on our lives. And, as their ubiquity spreads, so too does the debate around whether we should allow ourselves to become so reliant on them – and who, if anyone, is policing their use. Such concerns were sharpened further by the continuing revelations about how the US National Security Agency (NSA) has been using algorithms to help it interpret the colossal amounts of data it has collected from its covert dragnet of international telecommunications.
"For datasets the size of those the NSA collect, using algorithms is the only way to operate for certain tasks," says James Ball, the Guardian's data editor and part of the paper's NSA Files reporting team. "The problem is how the rules are set: it's impossible to do this perfectly. If you're, say, looking for terrorists, you're looking for something very rare. Set your rules too tight and you'll miss lots of, probably most, potential terror suspects. But set them more broadly and you'll drag lots of entirely blameless people into your dragnet, who will then face further intrusion or even formal investigation. We don't know exactly how the NSA or GCHQ use algorithms – or how extensively they're applied. But we do know they use them, including on the huge data trawls revealed in the Guardian."
From dating websites and City trading floors, through to online retailing and internet searches (Google's search algorithm is now a more closely guarded commercial secret than the recipe for Coca-Cola), algorithms are increasingly determining our collective futures. "Bank approvals, store cards, job matches and more all run on similar principles," says Ball. "The algorithm is the god from the machine powering them all, for good or ill."
Most observers blame the 'flash crash' of May 2010 on the use of algorithms to perform high-frequency trading. Photograph: Spencer Platt/Getty Images
But what is an algorithm? Dr Panos Parpas, a lecturer in the quantitative analysis and decision science ("quads") section of the department of computing at Imperial College London, says that wherever we use computers, we rely on algorithms: "There are lots of types, but algorithms, explained simply, follow a series of instructions to solve a problem. It's a bit like how a recipe helps you to bake a cake. Instead of having generic flour or a generic oven temperature, the algorithm will try a range of variations to produce the best cake possible from the options and permutations available."
Parpas stresses that algorithms are not a new phenomenon: "They've been used for decades – back to Alan Turing and the codebreakers, and beyond – but the current interest in them is due to the vast amounts of data now being generated and the need to process and understand it. They are now integrated into our lives. On the one hand, they are good because they free up our time and do mundane processes on our behalf. The questions being raised about algorithms at the moment are not about algorithms per se, but about the way society is structured with regard to data use and data privacy. It's also about how models are being used to predict the future. There is currently an awkward marriage between data and algorithms. As technology evolves, there will be mistakes, but it is important to remember they are just a tool. We shouldn't blame our tools."
The "mistakes" Parpas refers to are events such as the "flash crash" of 6 May 2010, when the Dow Jones industrial average fell 1,000 points in just a few minutes, only to see the market regain itself 20 minutes later. The reasons for the sudden plummet has never been fully explained, but most financial observers blame a "race to the bottom" by the competing quantitative trading (quants) algorithms widely used to perform high-frequency trading. Scott Patterson, a Wall Street Journal reporter and author of The Quants, likens the use of algorithms on trading floors to flying a plane on autopilot. The vast majority of trades these days are performed by algorithms, but when things go wrong, as happened during the flash crash, humans can intervene.
"By far the most complicated algorithms are to be found in science, where they are used to design new drugs or model the climate," says Parpas. "But they are done within a controlled environment with clean data. It is easy to see if there is a bug in the algorithm. The difficulties come when they are used in the social sciences and financial trading, where there is less understanding of what the model and output should be, and where they are operating in a more dynamic environment. Scientists will take years to validate their algorithm, whereas a trader has just days to do so in a volatile environment."
Most investment banks now have a team of computer science PhDs coding algorithms, says Parpas, who used to work on such a team. "With City trading, everyone is running very similar algorithms," he says. "They all follow each other, meaning you get results such as the flash crash. They use them to speed up the process and to break up big trades to disguise them from competitors when a big investment is being made. It's an on-going, live process. They will run new algorithms for a few days to test them before letting them loose with real money. In currency trading, an algorithm lasts for about two weeks before it is stopped because it is surpassed by a new one. In equities, which is a less complicated market, they will run for a few months before a new one replaces them. It takes a day or two to write a currency algorithm. It's hard to find out information about them because, for understandable reasons, they don't like to advertise when they are successful. Goldman Sachs, though, has a strong reputation across the investment banks for having a brilliant team of algorithm scientists. PhDs students in this field will usually be employed within a few months by an investment bank."
The idea that the world's financial markets – and, hence, the wellbeing of our pensions, shareholdings, savings etc – are now largely determined by algorithmic vagaries is unsettling enough for some. But, as the NSA revelations exposed, the bigger questions surrounding algorithms centre on governance and privacy. How are they being used to access and interpret "our" data? And by whom?
Dr Ian Brown, the associate director of Oxford University's Cyber Security Centre, says we all urgently need to consider the implications of allowing commercial interests and governments to use algorithms to analyse our habits: "Most of us assume that 'big data' is munificent. The laws in the US and UK say that much of this [the NSA revelations] is allowed, it's just that most people don't realise yet. But there is a big question about oversight. We now spend so much of our time online that we are creating huge data-mining opportunities."
Algorithms can run the risk of linking some racial groups to particular crimes. Photograph: Alamy
Brown says that algorithms are now programmed to look for "indirect, non-obvious" correlations in data. "For example, in the US, healthcare companies can now make assessments about a good or bad insurance risk based, in part, on the distance you commute to work," he says. "They will identity the low-risk people and market their policies at them. Over time, this creates or exacerbates societal divides. Professor Oscar Gandy, at the University of Pennsylvania, has done research into 'secondary racial discrimination', whereby credit and health insurance, which relies greatly on postcodes, can discriminate against racial groups because they happen to live very close to other racial groups that score badly."
Brown harbours similar concerns over the use of algorithms to aid policing, as seen in Memphis where Crush's algorithms have reportedly linked some racial groups to particular crimes: "If you have a group that is disproportionately stopped by the police, such tactics could just magnify the perception they have of being targeted."
Viktor Mayer-Schönberger, professor of internet governance and regulation at the Oxford Internet Institute, also warns against humans seeing causation when an algorithm identifies a correlation in vast swaths of data. "This transformation presents an entirely new menace: penalties based on propensities," he writes in his new book, Big Data: A Revolution That Will Transform How We Live, Work and Think, which is co-authored by Kenneth Cukier, the Economist's data editor. "That is the possibility of using big-data predictions about people to judge and punish them even before they've acted. Doing this negates ideas of fairness, justice and free will. In addition to privacy and propensity, there is a third danger. We risk falling victim to a dictatorship of data, whereby we fetishise the information, the output of our analyses, and end up misusing it. Handled responsibly, big data is a useful tool of rational decision-making. Wielded unwisely, it can become an instrument of the powerful, who may turn it into a source of repression, either by simply frustrating customers and employees or, worse, by harming citizens."
Mayer-Schönberger presents two very different real-life scenarios to illustrate how algorithms are being used. First, he explains how the analytics team working for US retailer Target can now calculate whether a woman is pregnant and, if so, when she is due to give birth: "They noticed that these women bought lots of unscented lotion at around the third month of pregnancy, and that a few weeks later they tended to purchase supplements such as magnesium, calcium and zinc. The team ultimately uncovered around two dozen products that, used as proxies, enabled the company to calculate a 'pregnancy prediction' score for every customer who paid with a credit card or used a loyalty card or mailed coupons. The correlations even let the retailer estimate the due date within a narrow range, so it could send relevant coupons for each stage of the pregnancy."
Harmless targeting, some might argue. But what happens, as has already reportedly occurred, when a father is mistakenly sent nappy discount vouchers instead of his teenage daughter whom a retailer has identified is pregnant before her own father knows?
Mayer-Schönberger's second example on the reliance upon algorithms throws up even more potential dilemmas and pitfalls: "Parole boards in more than half of all US states use predictions founded on data analysis as a factor in deciding whether to release somebody from prison or to keep him incarcerated.
Norah Jones: a specially developed algorithm predicted that her debut album contained a disproportionately high number of hit records. Photograph: Olycom SPA/Rex Features
Christopher Steiner, author of Automate This: How Algorithms Came to Rule Our World, has identified a wide range of instances where algorithms are being used to provide predictive insights – often within the creative industries. In his book, he tells the story of a website developer called Mike McCready, who has developed an algorithm to analyse and rate hit records. Using a technique called advanced spectral deconvolution, the algorithm breaks up each hit song into its component parts – melody, tempo, chord progression and so on – and then uses that to determine common characteristics across a range of No 1 records. McCready's algorithm correctly predicted – before they were even released – that the debut albums by both Norah Jones and Maroon 5 contained a disproportionately high number of hit records.
The next logical step – for profit-seeking record companies, perhaps – is to use algorithms to replace the human songwriter. But is that really an attractive proposition? "Algorithms are not yet writing pop music," says Steiner. He pauses, then laughs. "Not that we know of, anyway. If I were a record company executive or pop artist, I wouldn't tell anyone if I'd had a number one written by an algorithm."
Steiner argues that we should not automatically see algorithms as a malign influence on our lives, but we should debate their ubiquity and their wide range of uses. "We're already halfway towards a world where algorithms run nearly everything. As their power intensifies, wealth will concentrate towards them. They will ensure the 1%-99% divide gets larger. If you're not part of the class attached to algorithms, then you will struggle. The reason why there is no popular outrage about Wall Street being run by algorithms is because most people don't yet know or understand it."
But Steiner says we should welcome their use when they are used appropriately to aid and speed our lives. "Retail algorithms don't scare me," he says. "I find it useful when Amazon tells me what I might like. In the US, we know we will not have enough GP doctors in 15 years, as not enough are being trained. But algorithms can replace many of their tasks. Pharmacists are already seeing some of their prescribing tasks replaced by algorithms. Algorithms might actually start to create new, mundane jobs for humans. For example, algorithms will still need a human to collect blood and urine samples for them to analyse."
There can be a fine line, though, between "good" and "bad" algorithms, he adds: "I don't find the NSA revelations particularly scary. At the moment, they just hold the data. Even the best data scientists would struggle to know what to do with all that data. But it's the next step that we need to keep an eye on. They could really screw up someone's life with a false prediction about what they might be up to."
Facebook leaking user information, a dust-up over Facebook shadow profiles has relaunched. A “shadow profile” sounds like something a CIA operative would have – but if you’re a Facebook user, you have a shadow profile, whether you’re a real-life James Bond or just an accountant from Des Moines.
So what is a Facebook shadow profile, and where does yours lurk?
A Facebook shadow profile is a file that Facebook keeps on you containing data it pulls up from looking at the information that a user’s friends voluntarily provide. You’re not supposed to see it, or even know it exists. This collection of information can include phone numbers, e-mail addresses, and other pertinent data about a user that they don’t necessarily put on their public profile. Even if you never gave Facebook your second email address or your home phone number, they may still have it on file, since anyone who uses the “Find My Friends” feature allows Facebook to scan their contacts. So if your friend has your contact info on her phone and uses that feature, Facebook can match your name to that information and add it to your file.
“When people use Facebook, they may store and share information about you.”
Facebook recently announced that it fixed a bug that inadvertently revealed this hidden contact information for six million users. Their mea culpa was not particularly well-received, since this security breach revealed that the social network had been collecting this data on all of its users and compiling it into shadow profiles for years. Some people who use Facebook’s Download Your Information (DYI) tool could see the dossiers Facebook had been collecting as well as information their friends put up themselves. So, if I downloaded my information and was affected by the bug, I’d see some of the email addresses and phone numbers of my friends who did not make that information public.
Although Facebook corrected the bug, it hasn’t stopped this program of accumulating extra information on people. And researchers looking at the numbers say the breach is actually more involved than Facebook initially claimed, with four pieces of data released for a user that Facebook said had one piece of data leaked.
This snafu won’t come as a surprise to researchers who brought up Facebook’s shadow profiles long before this most recent breach. In 2011, an Irish advocacy group filed a complaint against Facebook for collecting information like email addresses, phone numbers, work details, and other data to create shadow profiles for people who don’t use the service. Since it actually takes moral fortitude to resist the social pull of Facebook, this is a slap in the face for people who make a point to stay off the network: The group claimed that Facebook still has profiles for non-Facebookers anyway.
Though the decision to publicly own up to the bug was a step in the right direction, this leak is disturbing because it illustrates just how little control we have over our data when we use services like Facebook. And it illustrates that Facebook isn’t apologizing for collecting information – it’s just apologizing for the bug. The shadow profile will live another day.
Most people understand that Facebook can see, archive, and data-mine the details you voluntarily put up on the site. The reason people are disturbed by shadow profiles is the information was collected in a roundabout way, and users had no control over what was collected (which is how even people who abstain from Facebook may have ended up with dossiers despite their reluctance to get involved with the site). Now we don’t just need to worry about what we choose to share; we also have to worry that the friends we trust with personal information will use programs that collect our data.
To Facebook’s credit, they do make this clear in the privacy policy, it’s just that no one bothers to read it:
“We receive information about you from your friends and others, such as when they upload your contact information, post a photo of you, tag you in a photo or status update, or at a location, or add you to a group. When people use Facebook, they may store and share information about you and others that they have, such as when they upload and manage their invites and contacts.”
Now, the Facebook shadow profiles contain information that many people make public anyways; plenty of people have made their phone numbers and addresses discoverable via a simple Google Search (not that they should, but that’s another story). But if you make a point to keep that kind of information private, this shadow profile business will sting. And even if you don’t mind the fact that Facebook creeped on your phone number via your friends, you should be concerned that next time these shadow profiles make it into the news, it will be over other data-mining that could be potential harmful. Imagine if your credit card information or PIN number ended up going public.
The way Facebook worded its apology is interesting because it doesn’t say that they don’t collect that type of information.
“Additionally, no other types of personal or financial information were included and only people on Facebook – not developers or advertisers – have access to the DYI tool.”
The fact that they said “were included” instead of “were collected” leaves open the possibility that Facebook does have this kind of information on file – it just wasn’t part of this particular mix-up.
Facebook hasn’t reassured users by saying they don’t collect this kind of data, and that’s awfully suspicious; if their shadow data collection was really limited to phone numbers and email addresses, your would think they would’ve explicitly said so, to ameliorate critics. What Facebook isn’t saying here versus what they are saying speaks volumes. The site is sorry for the bug, but not sorry for surreptitiously collecting data on you. And they’re admitting the data that was released in the bug, but not explaining the exact scope of the shadow profile amalgamation.
Facebook’s shadow profiles aren’t uniquely or especially nefarious, but this incident makes it all the more obvious that the amount of data companies are collecting on you far surpasses what you might suspect. And unless there are legislative changes, this will continue unabated.
Having mobile devices closely monitoring our behavior could make them more useful, and open up new business opportunities.
Many of us already record the places we go and things we do by using our smartphone to diligently snap photos and videos, and to update social media accounts. A company called ARO is building technology that automatically collects a more comprehensive, automatic record of your life.
ARO is behind an app called Saga that automatically records every place that a person goes. Now ARO’s engineers are testing ways to use the barometer, cameras, and microphones in a device, along with a phone’s location sensors, to figure out where someone is and what they are up to. That approach should debut in the Saga app in late summer or early fall.
The current version of Saga, available for Apple and Android phones, automatically logs the places a person visits; it can also collect data on daily activity from other services, including the exercise-tracking apps FitBit and RunKeeper, and can pull in updates from social media accounts like Facebook, Instagram, and Twitter. Once the app has been running on a person’s phone for a little while, it produces infographics about his or her life; for example, charting the variation in times when they leave for work in the morning.
Software running on ARO’s servers creates and maintains a model of each user’s typical movements. Those models power Saga’s life-summarizing features, and help the app to track a person all day without requiring sensors to be always on, which would burn too much battery life.
“If I know that you’re going to be sitting at work for nine hours, we can power down our collection policy to draw as little power as possible,” says Andy Hickl, CEO of ARO. Saga will wake up and check a person’s location if, for example, a phone’s accelerometer suggests he or she is on the move; and there may be confirmation from other clues, such as the mix of Wi-Fi networks in range of the phone. Hickl says that Saga typically consumes around 1 percent of a device’s battery, significantly less than many popular apps for e-mail, mapping, or social networking.
That consumption is low enough, says Hickl, that Saga can afford to ramp up the information it collects by accessing additional phone sensors. He says that occasionally sampling data from a phone’s barometer, cameras, and microphones will enable logging of details like when a person walked into a conference room for a meeting, or when they visit Starbucks, either alone or with company.
The Android version of Saga recently began using the barometer present in many smartphones to distinguish locations close to one another. “Pressure changes can be used to better distinguish similar places,” says Ian Clifton, who leads development of the Android version of ARO. “That might be first floor versus third floor in the same building, but also inside a vehicle versus outside it, even in the same physical space.”
ARO is internally testing versions of Saga that sample light and sound from a person’s environment. Clifton says that using a phone’s microphone to collect short acoustic fingerprints of different places can be a valuable additional signal of location, and allow inferences about what a person is doing. “Sometimes we’re not sure if you’re in Starbucks or the bar next door,” says Clifton. “With acoustic fingerprints, even if the [location] sensor readings are similar, we can distinguish that.”
Occasionally sampling the light around a phone using its camera provides another kind of extra signal of a person’s activity. “If you go from ambient light to natural light, that would say to us your context has changed,” says Hickl, and it should be possible for Saga to learn the difference between, say, the different areas of an office.
The end result of sampling light, sound, and pressure data will be Saga’s machine learning models being able to fill in more details of a users’ life, says Hickl. “[When] I go home today and spend 12 hours there, to Saga that looks like a wall of nothing,” he says, noting that Saga could use sound or light cues to infer when during that time at home he was, say, watching TV, playing with his kids, or eating dinner.
Andrew Campbell, who leads research into smartphone sensing at Dartmouth College, says that adding more detailed, automatic life-logging features is crucial for Saga or any similar app to have a widespread impact. “Automatic sensing relieves the user of the burden of inputting lots of data,” he says. “Automatic and continuous sensing apps that minimize user interaction are likely to win out.”
Campbell says that automatic logging coupled with machine learning should allow apps to learn more about users’ health and welfare, too. He recently started analyzing data from a trial in which 60 students used a life-logging app that Campbell developed called Biorhythm. It uses various data collection tricks, including listening for nearby voices to determine when a student is in a conversation. “We can see many interesting patterns related to class performance, personality, stress, sociability, and health,” says Campbell. “This could translate into any workplace performance situation, such as a startup, hospital, large company, or the home.”
Campbell’s project may shape how he runs his courses, but it doesn’t have to make money. ARO, funded by Microsoft cofounder Paul Allen, ultimately needs to make life-logging pay. Hickl says that he has already begun to rent out some of ARO’s technology to other companies that want to be able to identify their users’ location or activities. Aggregate data from Saga users should also be valuable, he says.
“Now we’re getting a critical mass of users in some areas and we’re able to do some trend-spotting,” he says. “The U.S. national soccer team was in Seattle, and we were able to see where activity was heating up around the city.” Hickl says the data from that event could help city authorities or businesses plan for future soccer events in Seattle or elsewhere. He adds that Saga could provide similar insights into many other otherwise invisible patterns of daily life.
Personal comment:
Or how to build up knowledge and minable data from low end "sensors". Finally, how some trivial inputs from low cost sensors can, combined with others, reveal deeper patterns in our everyday habits.
But who's Aro? Who founded it? Who are the "business angels" behind it and what are they up to? What does the technology exactly do? Where are its legal headquarters located (under which law)? That's the first questions you should ask yourself before eventually giving your data to a private company... (I know, this is usual suspects these days). But that's pretty hard to find! CEO is Mr Andy Hickl based in Seattle, having 1096 followers on Twitter and a "Sorry, this page isn't available" on Facebook, you can start to digg from there and mine for him on Google...
-
We are in need of some sort of efficient Creative Commons equivalent for data. But that would be respected by companies. As well as some open source equivalent for Facebook, Google, Dropbox, etc. (but also MS, Apple, etc.), located in countries that support these efforts through their laws and where these "Creative Commons" profiles and data would be implemented. Then, at least, we would have some choice.
In Switzerland, we had a term to describe how the landscape has been progressivily used since the 60ies to build small individual or holiday houses: "mitage du territoire" ("urban sprawl" sounds to be the equivalent in english, but "mitage" is related to "moths" to be precise, so rather ""mothed" landscape" if I could say so, which says what it says) and we had the opportunity to vote against it recently, with success. I believe that now the same thing is happening with personal and/or public sphere, with our lives: it is sprawled or "mothed" by private interests.
So, it is time to ask for the opportunity to "vote" (against it) everybody and have the choice between keeping the ownership of your data, releasing them as public or being paid for them (like a share in the company('s product))!
Smart city infrastructure can augment the ability of managers, planners, designers and engineers to define and implement a fundamentally better next generation of buildings, cities, regions — right? Maybe. For that to be a serious proposition, it’s going to have to be normal for planners and designers not only to collaborate productively with engineers, but to do so with the full and competent participation of the only people they mistrust more than each other ... customers.
"A city is not a BMW," writes Carl Skelton. "You can't drive it without knowing how it works." In a weighty think-piece on Places, he argues that the public needs new tools of citizenship to thrive in a "new soft world" increasingly shaped by smart meters, surveillance cameras, urban informatics and big data. "To be a citizen of a digital city requires understanding what the databases do and don’t contain, and what they could contain, and how the software used to process that data and drive design decisions does, doesn’t, and might yet perform."
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.