Wednesday, May 19. 2010
Using Ice to Cool Down the Grid
 |
| Ice power: Electric Power Research Institute, TVA and Volunteer Energy are conducting a joint test of the 'Ice Bear' in Knoxville, Tennessee. Neyland Stadium can be seen in the background. Credit: Courtesy of Ice Energy |
The first devices will be installed on about two dozen city-owned buildings in Glendale, CA, under the plan being coordinated by the Southern California Public Power Authority. Over the next two years, the 11 participating utilities will install 1,500 of the devices, providing a total of 53 megawatts of energy storage to relieve strain on the region's electrical grid. The project is the first large-scale implementation of Ice Energy's technology.
Each Ice Energy device is designed to make ice overnight, when demand for electricity is low, using a high-efficiency compressor to freeze 450 gallons of water. Around midday, the cooling mode kicks in, and the device shuts off the building's regular air conditioner for a six-hour cycle. It pipes a stream of coolant from the slowly melting block of ice to an evaporator coil installed within the building's heating, ventilation, and air-conditioning blower system. Once the ice is melted, the air conditioner returns to normal operation. Brian Parsonnet, Ice Energy's chief technology officer, says the Ice Bear can cut a building's power consumption by 95 percent during peak hours on the hottest days.
Cutting demand for electricity during peak hours reduces the need to build new power plants. It also allows utilities to rely on their most efficient power plants, says Ronald Domitrovic, a senior project manager for electric utilization at the Electric Power Research Institute. He says that when utilities fire up their "least efficient, oldest, and least desirable" generating resources to meet peak demand, every increment of increased power on the grid sends costs surging, whether one is talking fuel costs, greenhouse gas emissions, or service reliability. However, at night, utilities draw on their most efficient power plants, which use less fuel than power plants used only during peak hours. The utility also saves energy at other points in the grid--for example, cooler power lines at night transmit electricity more efficiently.
Domitrovic says systems that use ice or cold water on a large scale to provide cooling for campuses and large buildings have "been around for some time." But he says these are usually "expensive one-off units, designed specifically for the building," and that the smaller modular thermal storage systems that Ice Energy provides "can be deployed with relative simplicity" to serve one- or two-story commercial buildings. Ice Energy says that cooling units housed at distributed sites can be networked, presenting utilities with a resource that can be dispatched as needed to help manage demand on the grid.
Parsonnet says the per-unit production cost for the Ice Energy systems has come down from $15,000 for its inaugural model to just $5,000 today. David Walden of SCPPA says that the current models are "cost competitive" with other options for reducing peak power demands, including renewable energy sources such as solar power.
The Ice Energy systems could help integrate more renewable energy into the grid, says Craig Kuennen, marketing manager and project sponsor of Glendale Water and Power, the utility heading up the Glendale portion of the project. He says southern California "has significant wind resources, and those come in at night, when we would be making ice." The Ice Energy systems would provide demand for that wind power, which might otherwise be wasted because of low demand at night.
Copyright Technology Review 2010.
Tuesday, May 18. 2010
Facebook Personal Data a Security Risk
Monday, May 17. 2010
If You Want Freedom, Dont Use Proprietary Software
-----
 Free software pioneer Richard Stallman spoke with us recently about the principles of free and open source programs, and what he had to say is as relevant and revolutionary as when he first started working in this field 30 years ago.
Free software pioneer Richard Stallman spoke with us recently about the principles of free and open source programs, and what he had to say is as relevant and revolutionary as when he first started working in this field 30 years ago.
Our community has been talking a lot lately about what it means to be open, about what makes software open, about what makes companies open. No matter what talk of “openness” you hear in the media, no major web company — not Facebook, not Google, not Adobe and certainly not Apple — is creating truly free and open applications. Some may make gestures toward this ideology with APIs or “open source” projects, but ultimately, the company controls the software and the users’ data.
At the end of the day, if you want freedom and privacy, the only way to attain those goals is to abstain from proprietary software, including media players, social networks, operating systems, document storage, email services and any other program that is licensed, patented and locked down by a corporation. If you prefer convenience — well, best to stop complaining about your loss of freedom and/or privacy.
Like many heroes of the digital era, Richard Stallman is largely unsung by the general populace. Yet when it comes to user privacy and technological freedom, he’s probably one of the most committed individuals in the world.
By freedom, he means four things:
- The software should be freely accessible.
- The software should be free to modify.
- The software should be free to share with others.
- The software should be free to change and redistribute copies of the changed software.
Stallman started the Free Software Foundation. He even worked to make an operating system (GNU/Linux) that could be entirely free. And he is deeply opposed to proprietary software, software with commercial licenses that fly in the face of everything he calls freedom.
If you’ve ever downloaded music illegally, if you’ve ever complained about closed platforms, if you’ve ever gotten a serial number online for software you didn’t buy, if you’re worried about social networks controlling your data, you need to hear what Stallman has to say.
We got the chance to interview Stallman extensively at WordCamp San Francisco, and we’ll be posting segments of that interview each week. Stay tuned for insights on music sharing, Apple versus Adobe and more.
Note: Stallman asked that we use Ogg Theora, an open format, for encoding this video. To download the original video, go to its Wikimedia page. This video is published under a Creative Commons-No Derivatives license.
Personal comment:
There's a debate now on Mashable about what is open vs what is proprietary in technology. Especially now that this has become a marketing term full of lies.
Interesting debate to follow, in particular for us in the perspective of two projects we are currently working on where we'll claim for an open approach regarding technology in public spaces (all of them, including in outer space! I-Weather as Deep Space Public Lighting) or where we'll adopt a critical approach regarding surveillance (technologies) in the public space (a future "Paranoid Shelter" project we are working on for a while), followed maybe a bit later by a collaboration ("Globale Paranoïa") with French writer and essayist Eric Sadin.
It's a really a whole big debate, quite complex, just as the question of freedom that is a complex one. For our part, we are interested maybe in a less complex question at first. The one of public space (public is not free so to say, it is shared in different ways and allows for, or offer this and that but not everything).
Friday, May 14. 2010
DNA Robots on the Move
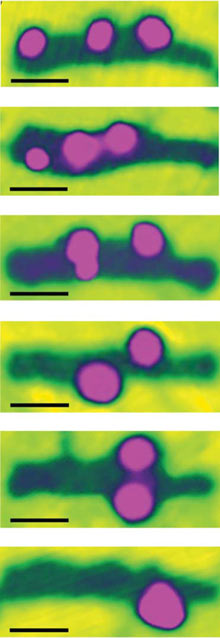 |
| DNA assembly line: An atomic force microscope image shows gold nanoparticles on a DNA track. Credit: Courtesy of Ned Seeman |
Researchers from Columbia University, Arizona State University, and Caltech have made a device that follows a programmable path on a surface patterned with DNA. Meanwhile, researchers from New York University, led by DNA nanoarchitecture pioneer Ned Seeman, have combined multiple DNA devices to make an assembly line. The nano contraption picks up gold nanoparticles as it tumbles along a DNA-patterned surface.
The two machines, described in today's Nature journal, are a possible step forward in making DNA nanobots that could assemble tiny electrical and mechanical devices. DNA robots could also put together molecules in new ways to make new materials, says Lloyd Smith, a chemistry professor at the University of Wisconsin-Madison. "Robots might have the ability to position one molecule in a particular way so that a reaction happens with another molecule which might not happen if they randomly collide in solution," he says.
In the past, researchers have made simple machines such as tweezers and walkers that have also been fashioned from DNA. Tweezers open and close by adding specific DNA strands to the solution. Walkers are molecules with dangling strands, or legs, that bind and detach from other DNA strands patterned on a surface, in effect moving along the surface.
The nano walker made at Columbia University is a protein molecule decorated with three legs--single-stranded DNAzymes, synthetic DNA molecules that act as enzymes and catalyze a reaction. The legs bind to complementary DNA strands on a surface. Then they catalyze a reaction that shortens one of the surface strands, so that its attachment to the leg becomes weaker. That leg lets go and moves on to the next surface strand.
The walker follows a track of strands that the researchers pattern on the surface. It can take up to 50 steps--compared to the two or three steps taken by previous walkers. It stops when it encounters a sequence that cannot be shortened. "We show how to program [the walker's] behavior by programming the landscape," says Milan Stojanovic, a biomedical engineer at Columbia University who developed the walker. "It enables us to think about adding further complexity: more than one molecule interacting and more complicated commands on the surface. What we hope to do eventually is to be able to [use nanobots to] repair tissues."
Seeman and his colleagues at New York University combine three different DNA components to make an assembly line. They have DNA path, a walker, and a machine that can deliver or hold back a cargo of a molecule of gold. The machine is a DNA structure that can be set up to either put a gold nanoparticle-laden strand in the path of the walker or away from it. The walker has four legs and three single-stranded DNA hands that can bind to the gold.
The researchers demonstrated a system in which the walker passes three machines, each carrying a different type of gold particle. Each machine can be set up to either deliver its cargo or keep it, giving a total of eight different ways in which the walker can be loaded, leading to eight different products.
The advances represent continuing success in creating nano devices with increasingly complex functions. "[We're] moving from individual entities that do something interesting to systems of entities working on something with a more complex behavior and function," Smith says.
Copyright Technology Review 2010.
Who Controls Identity on the Web?
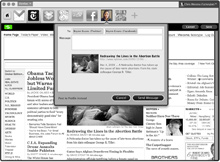 |
| Identity parade: A concept browser designed by Mozilla would let users control a single identity for logging in to different websites. Credit: Mozilla Foundation |
The two approaches are fundamentally different. Facebook's Open Graph Protocol uses the oAuth standard, which lets a website identify a user via a third-party site without exchanging sensitive information. Facebook--whose 400 million active users make it the world's largest social network in the world--stands to benefit as other sites come to rely on the information it holds about users and their social connections.
The approach taken by the Mozilla Foundation, which makes the Firefox browser, comes in the form of a suite of browser extensions. One of the extensions, called Account Manager, can replace all of a user's online passwords with secure, computer-generated strings that are encrypted and protected with a single master password. Mozilla's identity extensions can interact with other identity standards, including OpenGraph, oAuth, and OpenID, a standard that allows any website or Web service provider to host a social network-style profile of a user. The goal of the Mozilla Foundation's efforts is to establish a set of open standards and protocols that could be implemented in any browser or website.
As much as possible, identity would be moved out of the webpage itself and into the "chrome" of the browser--the parts around of the webpage. Logging in and out of sites would be accomplished through buttons at the top of the browser that would activate secure protocols--rendering the process of creating and memorizing usernames and passwords obsolete.
"Every user of the Internet today is expected to describe themselves to every site they go to," says Mike Hanson, principal engineer at Mozilla Labs. Inevitably, Hanson says, this leads to confusion and security holes, such as passwords that are identical across multiple sites.
The solution, according to Hanson, is to let the browser itself manage user identity. Weave Sync, another Mozilla extension, is designed to enable that vision. It stores encrypted versions of a growing list of data on a Mozilla-hosted server (or any user-specified server), including a person's history, preferences, bookmarks, and even open tabs, which can be synced across two or more browsers. This allows users to have the same browser workspace on any device that supports Firefox or its mobile equivalent, Fennec. There's even a prototype for the iPhone, built on top of Apple's Safari browser.
Last fall Mozilla Labs also commissioned Chris Messina, at the time a researcher in residence at Mozilla Labs, to design a Web browser that would manage the other half of online identity--a user's social graph. In Messina's mock-ups, a user can interact with people on the Web in ways that go beyond what OpenID or Facebook's OpenGraph currently offer. "The idea of a social browser is important to me because it's the single point of integration for all websites," says Messina. "It's the one thing that knows who you are across all social experiences."
Messina's designs envision a browser that lets users "follow" other users by viewing all of their relevant information streams--Facebook, Twitter, Flickr, etc.--collected into a single browser tab stamped with that user's profile picture. A similar interface could also be used to control exactly what personal information other people and websites have access to. This could allow, for instance, a user to change her shipping address across any number of sites at once, or to control which version of their identity a particular groups of friends can access. "I'm not interested in the [Mark] Zuckerberg approach, where privacy doesn't exist anymore," says Messina, referring to the CEO of Facebook.
Both Facebook and the Mozilla Foundation will face challenges in pushing their own vision of online identity. John Mitchell, a professor of computer science at Stanford, says the most significant barrier will be the adoption of suitable protocols. Before such protocols can be standardized and rolled into, for instance, the next version of HTML, Web developers are going to have to be willing to experiment.
"What I've seen from a lot of companies is an attempt to guess the end solution and build that only," says Mitchell. "It would be better if, instead, we had an open architecture where people could try many different approaches."
If the new Mozilla software and Messina's designs are sufficiently popular with users and developers (not to mention the influencers who sit on the boards of standards committees like the World Wide Web Consortium), then the foundation's technology could find its way into the regular release of Firefox and perhaps, ultimately, into other browsers.
To Messina, just drawing up the blueprints for such technology was an important first step. "We're further away from the death of the password than I'd like to be, but it's a nice goal to aim for," he says.
Copyright Technology Review 2010.
Personal comment:
Back in 2003 (and up to 2005), we treated this question of identity, surveillance-monitoring technique and data mining of user's data in the Knowscape Mobile project, or in the AI vs AI in self-space project too. We claimed for a total open approach of online identity considering the web as a public space (open data collected in open space belongs to everybody). Of course, this was a speculative project to address the question. An approach that won't be feasible in reality because we definitely need all type of spaces: public, private, semi-public, semi-private, etc. But the status of "space" and their data should be transparent to all users.
Today, this question of "who owns the data", of "public vs private" is becoming more and more of a hot problem, in particular regarding personal data. But it is definitely a problem worth discussing it. So as the status of public space.
fabric | rblg
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.
