Thursday, May 16. 2013
The Whole Earth (exhibition)
Via manystuff
-----

The image of the “blue planet”, a new perspective of the earth as seen from the outside, is one of the most popular images in history. This image, more than any other, has shaped the popular notion of the age of the “whole world” and globalization, from a worldwide society linked by the Internet to the current debate on the climate. Using artworks and materials from cultural history, the exhibition will critically explore the application of ecological-systemic concepts to society, politics, and aesthetics.
The exhibition The Whole Earth – until July 1, Haus der Kulturen der Welt, Berlin – is one of the first to explore the history of the photograph of the “blue planet”, and reflects in a comprehensive way the power of the Whole Earth Catalog…
Related Links:
Tuesday, May 14. 2013
Sky Crane
Via BLDGBLOG
-----
de noreply@blogger.com (Geoff Manaugh)

When I walked out to get breakfast this morning, clouds had obscured all but the topmost workings of the 1 World Trade Center site, visible through our living room window—a strange vision of machines, pulleys, cranes, and gears sort of hovering in the sky, like something out of Archigram by way of Hayao Miyazaki.
Friday, May 10. 2013
Brooklyn Developer Offers Up His Personal Data on Kickstarter
Wednesday, May 08. 2013
Stephen Wolfram on Personal Analytics
-----
The creator of the Wolfram Alpha search engine explains why he thinks your life should be measured, analyzed, and improved.

Personal control: Stephen Wolfram created the search engine Wolfram Alpha
Don’t be surprised if Stephen Wolfram, the renowned complexity theorist, software company CEO, and night owl, wants to schedule a work call with you at 9 p.m. In fact, after a decade of logging every phone call he makes, Wolfram knows the exact probability he’ll be on the phone with someone at that time: 39 percent.
Wolfram, a British-born physicist who earned a doctorate at age 20, is obsessed with data and the rules that explain data. He is the creator of the software Mathematica and of Wolfram Alpha, the nerdy “computational knowledge engine” that can tell you the distance to the moon right now, in units including light-seconds.
Now Wolfram wants to apply the same techniques to people’s personal data, an idea he calls “personal analytics.” He started with himself. In a blog post last year, Wolfram disclosed and analyzed a detailed record of his life stretching back three decades, including documents, hundreds of thousands of e-mails, and 10 years of computer keystrokes, a tally of which is e-mailed to him each morning so he can track his productivity the day before.
Last year, his company released its first consumer product in this vein, called “Personal Analytics for Facebook.” In under a minute, the software generates a detailed study of a person’s relationships and behavior on the site. My own report was revealing enough. It told me which friend lives at the highest latitude (Wicklow, Ireland) and the lowest (Brisbane, Australia), the percentage who are married (76.7 percent), and everyone’s local time. More of my friends are Scorpios than any other sign of the zodiac.
It looks just like a dashboard for your life, which Wolfram says is exactly the point. In a phone call that was recorded and whose start and stop time was entered into Wolfram’s life log, he discussed why personal analytics will make people more efficient at work and in their personal lives.
What do you typically record about yourself?
E-mails, documents, and normally, if I was in front of my computer, it would be recording keystrokes. I have a motion sensor for the room that records when I pace up and down. Also a pedometer, and I am trying to get an eye-tracking system set up, but I haven’t done that yet. Oh, and I’ve been wearing a sensor to measure my posture.
Do you think that you’re the most quantified person on the planet?
I couldn’t imagine that that was the case until maybe a year ago, when I collected together a bunch of this data and wrote a blog post on it. I was expecting that there would be people who would come forward and say, “Gosh, I’ve got way more than you.” But nobody’s come forward. I think by default that may mean I’m it, so to speak.
You coined this term “personal analytics.” What does it mean?
There’s organizational analytics, which is looking at an organization and trying to understand what the data says about its operation. Personal analytics is what you can figure out applying analytics to the person, to understand the operation of the person.
Why have you been analyzing Facebook data?
We are trying to feel out the market for personal analytics. Most people are not recording all their keystrokes like I am. But the one thing they are doing is leaving lots of digital trails, including on Facebook, and that is one of the pieces we’ve been experimenting with.
We’ve accumulated a lot of Facebook data—you’re seeing the story of people’s lives, played out in the level of data. You can see relationship status as a function of age, or the evolution of the clustering of friends at different ages. It’s really quite fascinating to see how all this stuff is just right there in the data.

Social grid: People’s friend networks on Facebook are presented as cluster diagrams.
Isn’t a lot of what you find kind of obvious? Like friends from college aren’t connected to the ones from grammar school?
Yes, but then you get a case where the data analysis is buggy. You get some curve, and your reaction is, “Oh, yeah, I understand why the curve is that way, I’ve got an argument for it.” But then, oops, there was a bug in the analysis and actually the curve is something different. That reminds you things aren’t quite so obvious. If you actually measure it, that’s doing science.
What’s the connection to the search engine you built?
Right now Wolfram Alpha is strong on public knowledge: accumulating and searching the knowledge of the civilization. But what you have to do in personal analytics is try to accumulate the knowledge of a person’s life. Then the two can actually be integrated, and I’ll give a kind of silly example. You might ask: “Who do I know that can go out into their backyard and go and look at the night sky right now?” For that you have to be able to compute who is in nighttime, who doesn’t have cloudy weather, and things like this. And we can compute all that stuff.
What do you see as the big applications in personal analytics?
Augmented memory is going to be very important. I’ve been spoiled because for years I’ve had the ability to search my e-mail and all my other records. I’ve been the CEO of the same company for 25 years, and so I never changed jobs and lost my data. That’s something that I think people will just come to expect. Pure memory augmentation is probably the first step.
The next is preëmptive information delivery. That means knowing enough about people’s history to know what they’re going to care about. Imagine someone is reading a newspaper article, and we know there is a person mentioned in it that they went to high school with, and so we can flag it. I think that’s the sort of thing it’s possible to dramatically automate and make more efficient.
Then there will be a certain segment of the population that will be into the self-improvement side of things, using analytics to learn about ourselves. Because we may have a vague sense about something, but when the pattern is explicit, we can decide, “Do we like that behavior, do we not?” Very early on, back in the 1990s, when I first analyzed my e-mail archive, I learned that a lot of e-mail threads at my company would, by a certain time of day, just resolve themselves. That was a useful thing to know, because if I jumped in too early I was just wasting my time.
What technologies are needed to do personal analytics at a large scale?
It’s data science and the whole cluster of technologies that come with that. Then it’s having computational knowledge about the world and being able to make queries in natural language. Then you need to sense things about the world, whether it’s with sensors or being able to do visual recognition to know what one is seeing. Then the final thing is just all the plumbing infrastructure to get all of these devices to communicate and feed their information to a place where one can do analysis.
Where do you stand on commercializing these ideas?
The personal analytics of Facebook for Wolfram Alpha is a deployed project, and there will be more of those in the personal-analytics space. We think we can do terrific things, but you have to be able to get to the data. That has been the holdup. The data isn’t readily available. Recently we’ve been working with different companies to try and make sure we can connect their sensors to kind of a generic analytics platform, to take people’s data, move it to the cloud, and do analytics on it.
How much better do you think that people or organizations can become with some data feedback?
I think it will be fairly dramatic. It’s like asking how much more money can you make if you track your portfolio rather than just vaguely remembering what investments you made.
Related Links:
Friday, May 03. 2013
Moores Law and the Origin of Life
-----
As life has evolved, its complexity has increased exponentially, just like Moore’s law. Now geneticists have extrapolated this trend backwards and found that by this measure, life is older than the Earth itself.
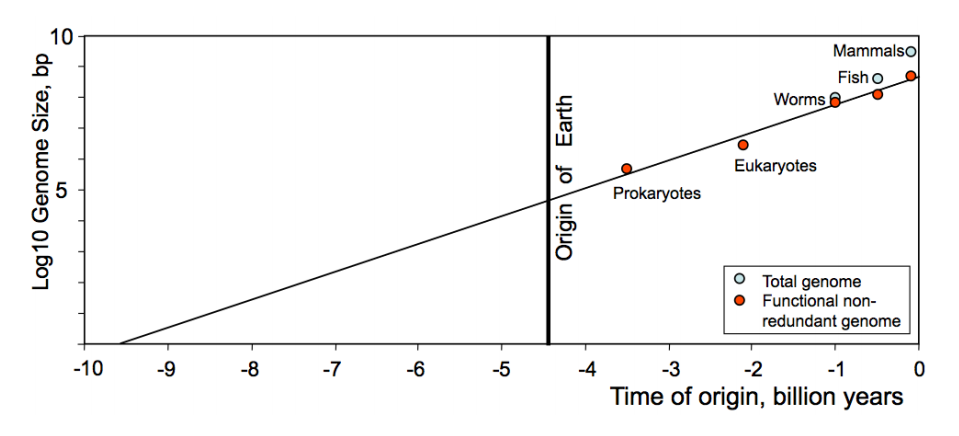
Here’s an interesting idea. Moore’s Law states that the number of transistors on an integrated circuit doubles every two years or so. That has produced an exponential increase in the number of transistors on microchips and continues to do so.
But if an observer today was to measure this rate of increase, it would be straightforward to extrapolate backwards and work out when the number of transistors on a chip was zero. In other words, the date when microchips were first developed in the 1960s.
A similar process works with scientific publications. Between 1990 and 1960, they doubled in number every 15 years or so. Extrapolating this backwards gives the origin of scientific publication as 1710, about the time of Isaac Newton.
Today, Alexei Sharov at the National Institute on Ageing in Baltimore and his mate Richard Gordon at the Gulf Specimen Marine Laboratory in Florida, have taken a similar to complexity and life.
These guys argue that it’s possible to measure the complexity of life and the rate at which it has increased from prokaryotes to eukaryotes to more complex creatures such as worms, fish and finally mammals. That produces a clear exponential increase identical to that behind Moore’s Law although in this case the doubling time is 376 million years rather than two years.
That raises an interesting question. What happens if you extrapolate backwards to the point of no complexity–the origin of life?
Sharov and Gordon say that the evidence by this measure is clear. “Linear regression of genetic complexity (on a log scale) extrapolated back to just one base pair suggests the time of the origin of life = 9.7 ± 2.5 billion years ago,” they say.
And since the Earth is only 4.5 billion years old, that raises a whole series of other questions. Not least of these is how and where did life begin.
Of course, there are many points to debate in this analysis. The nature of evolution is filled with subtleties that most biologists would agree we do not yet fully understand.
For example, is it reasonable to think that the complexity of life has increased at the same rate throughout Earth’s history? Perhaps the early steps in the origin of life created complexity much more quickly than evolution does now, which will allow the timescale to be squeezed into the lifespan of the Earth.
Sharov and Gorden reject this argument saying that it is suspiciously similar to arguments that squeeze the origin of life into the timespan outlined in the biblical Book of Genesis.
Let’s suppose for a minute that these guys are correct and ask about the implications of the idea. They say there is good evidence that bacterial spores can be rejuvenated after many millions of years, perhaps stored in ice.
They also point out that astronomers believe that the Sun formed from the remnants of an earlier star, so it would be no surprise that life from this period might be preserved in the gas, dust and ice clouds that remained. By this way of thinking, life on Earth is a continuation of a process that began many billions of years earlier around our star’s forerunner.
Sharov and Gordon say their interpretation also explains the Fermi paradox, which raises the question that if the universe is filled with intelligent life, why can’t we see evidence of it.
However, if life takes 10 billion years to evolve to the level of complexity associated with humans, then we may be among the first, if not the first, intelligent civilisation in our galaxy. And this is the reason why when we gaze into space, we do not yet see signs of other intelligent species.
There’s no question that this is a controversial idea that will ruffle more than a few feathers amongst evolutionary theorists.
But it is also provocative, interesting and exciting. All the more reason to debate it in detail.
Ref: arxiv.org/abs/1304.3381: Life Before Earth
fabric | rblg
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.
