Monday, October 29. 2012
Programmers are the New Art World Renegades
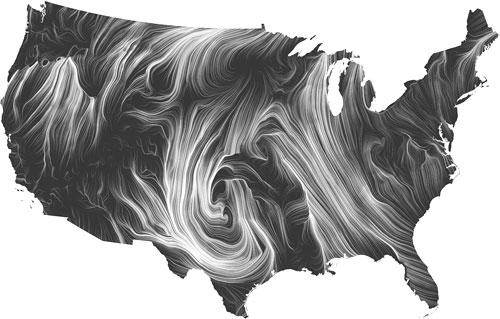
A visualization from researchers at Google shows wind flowing over the United States.
Just as photography was a controversial new art form in the late 19th century (critics questioned the role of the artist if the machine ultimately produced the work), it seems computer programmers have yet to be fully accepted into the art world.
This much was clear at the first Leaders in Software and Art (LISA) Conference, which took place at the GuggenheimMuseum in New York last week. The conference grew out of the LISA Salons that conference organizer Isabel Draves has hosted for three years in an effort to create a sense of community among software artists.
Panel discussions at the event addressed questions about the place of software art in history. Draves said in her opening remarks that it could even become the next big artistic movement: "something has to come after post-modernism. It's only a matter of time" before media art takes its rightful place in history.
But software art—images, videos, and interactive content created by programming computers—is still experiencing resistance from the mainstream art community, according to Draves and others at the conference. While the field is decades old, they said, it still hasn't been accepted as a mainstream art form.
Panel discussions included media art collectors, museum curators and new media artists asking how does one evaluate, collect and distribute this kind of art? How can social media and crowd sourcing play a role in art? And how does software change the language of art and the space in which it is exhibited?
Much of the rest of the event was dedicated to celebrating work that could perhaps help convince some of those doubters.
Keynote speaker Scott Snibbe called the computer “the ultimate looking glass” through which to create alternate universes. His work with musician Bjork on the first app album Biophilia (October, 2011) is exactly that: a cosmos of clickable constellations, each of which leads to an “interactive” song over which the user has some control. His forthcoming project is an interactive app for REWORK_Philip Glass Remixed (out this month).
Of the lightening speakers there were several standouts. Data visualization expert Martin Wattenberg, half of two-person team leading the “Big Picture,” visualization research team at Google, presented the Wind Map which displays data from the National Digital Forecast Database with brush-stroke beauty across a map of the United States. His colleague, Fernanda Viegas, showed edit wars in the Wikipedia entry for “chocolate” by colorfully charting each change made to the page. What looks like a zig-zagging artistic effect is in fact a scuffle over the roots of chocolate “coulage”.
Bang-Geul Han showed her Blogreader project, a haunting video in which she sits on a stool in a snowy plane robotically telling personal narratives. The narratives are pulled from blog entries by a Perl script from a now-defunct site called teenagediary.com. She recorded herself reading 3800 of the site’s most frequent words and played them back in the stark visual context. If a word existed in the blog but wasn’t recorded it appears in text on the video. The effect is a visual and audio disconnect from the emotional content of the blogs, many of which recount crushes and heartbreaks.
a haunting video in which she sits on a stool in a snowy plane robotically telling personal narratives from others' blog entries. She recorded herself reading blog entries in front of camera, and wrote a program that grabbed new blog entries every 5 minutes, and turned them into a strings of text that are matched against the pre-recorded words. The effect is a visual and audio disconnect from the emotional content of the blogs, many of which recount crushes and heartbreaks.
Jake Barton, founder of Local Projects, which was involved in the 911 Memorial Museum, talked about his design for an interactive addition to the Cleveland Museum of Art. The display will show the museum's entire collection on a digital panel through which users can create their own collections sorted by theme. For example, if a user searches for art depicting “Love and Lust” the panel would display the racier paintings and sculptures in the collection. The new space opens in January.
Karolina Sobecka's work might've been the most haunting: virtual storefronts housing crowds that don't exist but which nevertheless turn to look at passersby. And a virtual dog that, using tracking software, follows the viewer as if it could see and sniff.
And the most popular of the bunch, Golan Levin, showed work he feels should be “driven by civic concerns and conscience.” When his son noticed that the parts of the toys he played with don't work together (Legos, Tinkertoys), Levin created the Free Universal Construction Kit, 3D printed parts that allow the two divergent toy species to mate.
Mainstream or not, several of the works displayed reflected the very best of the overlap between art and science.
Wednesday, October 24. 2012
Get moving
Google Releases Never-Before-Seen Images of Its Data Centers
Via ArchDaily
-----
“A rare look behind the server aisle. Here hundreds of fans funnel hot air from the server racks into a cooling unit to be recirculated. The green lights are the server status LEDs reflecting from the front of Google’s servers.” Photo © Google/ Connie Zhou
If you’ve never heard of a Data Center before, there’s a reason. Despite the fact that data centers are “Giant, whirring, power-guzzling behemoths of data storage – made of cables, servers, routers, tubes, coolers, and wires,” they’re often hidden far away, where their energy-guzzling is more efficient (and way less less obvious).
Indeed, largely because of their gargantuan energy requirements and high-tech secrets, Data Centers have been shrouded in mystery since their beginnings. This is particularly true in Google’s case. When Andrew Blum, author of Tubes: A Journey to the Center of the Internet, visited Google’s Data Center in The Dalles, Oregon, he said it was like “ a prison,” and couldn’t even get past the cafeteria. Nary a peek has been seen of a Google Data Center.
Until now, that is. Google just launched a new website, Where the Internet Lives, which features never-before-seen images of eight of Google’s 9 data centers, the places the “physical internet” calls home.

Network Room at Google’s Data Center in Council Bluffs, Iowa: “Inside Google’s campus network room, routers and switches allow data centers to talk to each other. The fiber optic networks connecting their sites can run at speeds that are more than 200,000 times faster than a typical home Internet connection. The fiber cables run along the yellow cable trays near the ceiling.” Photo © Google/ Connie Zhou
Google didn’t share with us why they’re choosing to go transparent now (we’re guessing Facebook’s decision to openly tout their Data Centers’ design & energy-efficiency might have something to do with it), but they did alert us to some of their centers’ more ecologically note-worthy features.
According to Google, their facilities, which must process 3 billion search queries a day and 72 hours of YouTube videos every minute, are “among the most energy efficient in the world,” “using half the energy of a typical data center.”
Google’s Data Center in Hamina, Finland, for example, with an Alvar Aalto-designed machine hall, uses a cutting-edge cooling system, utilizing sea water from the Bay of Finland.
Scroll on for images of Hamina and other Google Data Centers – and see them all at Google’s new site: Where the Internet Lives.

Google’s Data Center in Hamina, Finland: “A beautiful landscape forms during winter in Finland, as the gulf ices over and creates a picturesque view.” Photo © Google/Connie Zhou

Servers at Google’s Data Center in Hamina, Finland; “Blue lights like these mean everything is functioning properly on the server floor.” Photo © Google/ Connie Zhou

Google’s Data Center in Hamina, Finland. ““Hamina is one of three data centers Google maintains in Europe. Previously it was the home of the Stora Enso paper mill.” Photo © Google/Connie Zhou

“Another view of Google’s Hamina location, taken while standing on the frozen Gulf of Finland.” Photo © Google/ Connie Zhou
The Dalles, Oregon

Cooling Towers at Google’s Data Center in The Dalles, Oregon: “Plumes of steam rise above Google’s cooling towers. When you can see the water vapor – meaning humidity and temperatures are low – the cooling towers are at their most efficient.” Photo © Google/Connie Zhou

Cooling Towers at Google’s Data Center in The Dalles, Oregon: “Plumes of steam rise above Google’s cooling towers. When you can see the water vapor – meaning humidity and temperatures are low – the cooling towers are at their most efficient.” Photo © Google/Connie Zhou
Saint Ghislain, Belgium

“A sunset over Saint Ghislain, Belgium illuminates Google’s water storage tanks and cooling towers.” Photo © Google/Connie Zhou
Lenoir, North Carolina

“A cool spring night falls on Google’s Lenoir, North Carolina data center. From this beautiful location, they’re able to provide their services – in the middle of the night – to the entire world.” Photo © Google/Connie Zhou
Douglas County, Georgia

“Google keep pipes like these ready with highly-pressurized water in case of a fire. This water, in particular, is cleaned and filtered so if they use it, they don’t contaminate the facility.” Photo © Google/ Connie Zhou

“Thousands of feet of pipe line the inside of Google’s data centers. They paint them bright colors not only because it’s fun, but also to designate which one is which. The bright pink pipe in this photo transfers water from the row of chillers (the green units on the left) to a outside cooling tower” Photo © Google/Connie Zhou
Continue reading "Google Releases Never-Before-Seen Images of Its Data Centers "
Personal comment:
Of course this news has been rebloged a lot recently, I know it and I will just add to the pile of reblogs, a few days later now that the news has spread (and start already to be forgotten). But it is nonetheless interesting for us to keep it as a resource here on | rblg, so as Facebook's "open compute" data center architecture, as we plan to start soon a new set of projects and architectural experiments around the idea of "inhabiting the cloud". A good lecture about this subject is also the recent publication by CLOG about Data Space.
-
See also this video from Google (and access a Datacenter through Streetview).
Monday, October 22. 2012
Ubisoft Montreal_Watch Dogs "Blackout"
Google Puts Its Virtual Brain Technology to Work
-----
By Tom Simonite
A powerful new approach to artificial intelligence is ready to improve many Google products.

Platonic ideal: This composite image represents the ideal stimulus that Google’s neural network recognizes as a cat face.
Credit: Google
This summer Google set a new landmark in the field of artificial intelligence with software that learned how to recognize cats, people, and other things simply by watching YouTube videos (see "Self-Taught Software"). That technology, modeled on how brain cells operate, is now being put to work making Google's products smarter, with speech recognition being the first service to benefit.
Google's learning software is based on simulating groups of connected brain cells that communicate and influence one another. When such a neural network, as it's called, is exposed to data, the relationships between different neurons can change. That causes the network to develop the ability to react in certain ways to incoming data of a particular kind—and the network is said to have learned something.
Neural networks have been used for decades in areas where machine learning is applied, such as chess-playing software or face detection. Google's engineers have found ways to put more computing power behind the approach than was previously possible, creating neural networks that can learn without human assistance and are robust enough to be used commercially, not just as research demonstrations.
The company's neural networks decide for themselves which features of data to pay attention to, and which patterns matter, rather than having humans decide that, say, colors and particular shapes are of interest to software trying to identify objects.
Google is now using these neural networks to recognize speech more accurately, a technology increasingly important to Google's smartphone operating system, Android, as well as the search app it makes available for Apple devices (see "Google's Answer to Siri Thinks Ahead"). "We got between 20 and 25 percent improvement in terms of words that are wrong," says Vincent Vanhoucke, a leader of Google's speech-recognition efforts. "That means that many more people will have a perfect experience without errors." The neural net is so far only working on U.S. English, and Vanhoucke says similar improvements should be possible when it is introduced for other dialects and languages.
Other Google products will likely improve over time with help from the new learning software. The company's image search tools, for example, could become better able to understand what's in a photo without relying on surrounding text. And Google's self-driving cars (see "Look, No Hands") and mobile computer built into a pair of glasses (see "You Will Want Google's Goggles") could benefit from software better able to make sense of more real-world data.
The new technology grabbed headlines back in June of this year, when Google engineers published results of an experiment that threw 10 million images grabbed from YouTube videos at their simulated brain cells, running 16,000 processors across a thousand computers for 10 days without pause.

Average features: This composite image represents the ideal stimulus for Google's software to recognize a human face.
Credit: Google
"Most people keep their model in a single machine, but we wanted to experiment with very large neural networks," says Jeff Dean, an engineer helping lead the research at Google. "If you scale up both the size of the model and the amount of data you train it with, you can learn finer distinctions or more complex features."
The neural networks that come out of that process are more flexible. "These models can typically take a lot more context," says Dean, giving an example from the world of speech recognition. If, for example, Google's system thought it heard someone say "I'm going to eat a lychee," but the last word was slightly muffled, it could confirm its hunch based on past experience of phrases because "lychee" is a fruit and is used in the same context as "apple" or "orange."
Dean says his team is also testing models that understand both images and text together. "You give it 'porpoise' and it gives you pictures of porpoises," he says. "If you give it a picture of a porpoise, it gives you 'porpoise' as a word."
A next step could be to have the same model learn the sounds of words as well. Being able to relate different forms of data like that could lead to speech recognition that gathers extra clues from video, for example, and it could boost the capabilities of Google's self-driving cars by helping them understand their surroundings by combining the many streams of data they collect, from laser scans of nearby obstacles to information from the car's engine.
Google's work on making neural networks brings us a small step closer to one of the ultimate goals of AI—creating software that can match animal or perhaps even human intelligence, says Yoshua Bengio, a professor at the University of Montreal who works on similar machine-learning techniques. "This is the route toward making more general artificial intelligence—there's no way you will get an intelligent machine if it can't take in a large volume of knowledge about the world," he says.
In fact, the workings of Google's neural networks operate in similar ways to what neuroscientists know about the visual cortex in mammals, the part of the brain that processes visual information, says Bengio. "It turns out that the feature learning networks being used [by Google] are similar to the methods used by the brain that are able to discover objects that exist."
However, he is quick to add that even Google's neural networks are much smaller than the brain, and that they can't perform many things necessary to intelligence, such as reasoning with information collected from the outside world.
Dean is also careful not to imply that the limited intelligences he's building are close to matching any biological brain. But he can't resist pointing out that if you pick the right contest, Google's neural networks have humans beat.
"We are seeing better than human-level performance in some visual tasks," he says, giving the example of labeling, where house numbers appear in photos taken by Google's Street View car, a job that used to be farmed out to many humans.
"They're starting to use neural nets to decide whether a patch [in an image] is a house number or not," says Dean, and they turn out to perform better than humans. It's a small victory—but one that highlights how far artificial neural nets are behind the ones in your head. "It's probably that it's not very exciting, and a computer never gets tired," says Dean. It takes real intelligence to get bored.
fabric | rblg
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.
