Monday, May 31. 2010
Books As Social Objects
In graphics: Supercomputing superpowers
Via BBC
-----
The biannual Top 500 supercomputer list has been released. Use this graphic to explore the world's fastest number crunchers or find out more about alternative supercomputer powers.


The data used to generate the interactive treemap visualisation come from a draft of the June 2010 TOP500 Supercomputing list. This ranks most of the world's fastest supercomputers twice a year. There may be minor differences between this list and the final published list.
The graphic allows you to see the visualise the list by the speed of each machine; the operating systems used; what it is used for; the country where it is based; the maker of the silicon chips used to build the machine and the manufacturer of the super computer.
The maps were produced using the Prefuse Flare software, developed by the University of California Berkeley.
Related Links:
Friday, May 28. 2010
Defence lab reveals ultimate CCTV
Via Archinect
-----

"You can't tell who is an insurgent by what they look like, but you can track their behaviour," explained Andrew Seedhouse, chief technologist for sensors and countermeasures at Dstl. The surveillance, DSTL says, will eventually help to "win the battle" against insurgency. Um what ?
Friday, May 21. 2010
Synthetic Life Is Born... Er, Synthesized
Via GOOD (is it, really?)
-----
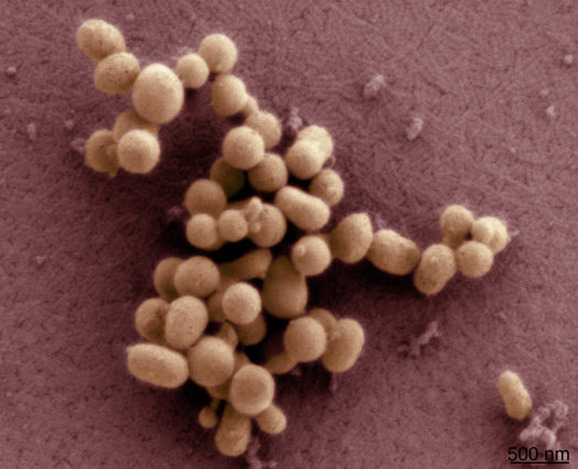
Good/terrifying news! J. Craig Venter, the maverick geneticist, has created a new synthetic life form. Using an existing bacteria genome as a model, Venter's team created a new 1.08-million base pair genome and transplanted it into a natual cell, where it took over and started replicating.
As Venter described it during a press conference this morning, “This is the first self-replicating species we’ve had on the planet whose parent is a computer.” Popular Science says this "opens the door to engineered biology that is completely manipulated by laboratory scientists." Venter wants to use synthetic life to create algae that can eat carbon dioxide and produce fuel, but potential applications include creating new foods, speeding up the production of vaccines, and of course, taking over the world with an army of engineered superorganisms.
The number of people writing about this online will far exceed the number who know what they're talking about. If you want informed opinions, this PDF provides a roundup of reactions from eight actual experts.
Qbo open-source robot detailed
Via Slash Gear
-----
Could it be love at first sight? As soon as I saw his tubby little body and wide eyes, I knew I had to make him mine. No, not my clandestine and short-lived love affair with Elton John, but the Qbo robot. Having teased us with an open-source ethos and design schematics, project lead TheCorpora have followed up with some proper details about what this DIY ‘bot should do. That includes stereoscopic high-def webcam vision in a moveable head, complete with three microphones and even motorized eyelids. Meanwhile the base section has various ultrasonic and infrared sensors, a status display, stereo speakers and the brains of the Qbo, a Mini-ITX board with Intel Atom CPU and NVIDIA Ion graphics. Altogether that supports stereoscopic vision, speech recognition and synthesis, and object avoidance, with the ‘bot using WiFi and Bluetooth to communicate. Being a big robot geek I’m really looking forward to seeing this project grow.

Related Links:
fabric | rblg
This blog is the survey website of fabric | ch - studio for architecture, interaction and research.
We curate and reblog articles, researches, writings, exhibitions and projects that we notice and find interesting during our everyday practice and readings.
Most articles concern the intertwined fields of architecture, territory, art, interaction design, thinking and science. From time to time, we also publish documentation about our own work and research, immersed among these related resources and inspirations.
This website is used by fabric | ch as archive, references and resources. It is shared with all those interested in the same topics as we are, in the hope that they will also find valuable references and content in it.
